 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Layers: Enhancing Interpretability and Intervenability via LLM Conceptualization
Feb 19, 2025The opaque nature of Large Language Models (LLMs) has led to significant research efforts aimed at enhancing their interpretability, primarily through post-hoc methods. More recent in-hoc approaches, such as Concept Bottleneck Models (CBMs), offer both interpretability and intervenability by incorporating explicit concept representations. However, these methods suffer from key limitations, including reliance on labeled concept datasets and significant architectural modifications that challenges re-integration into existing system pipelines. In this work, we introduce a new methodology for incorporating interpretability and intervenability into an existing model by integrating Concept Layers (CLs) into its architecture. Our approach projects the model's internal vector representations into a conceptual, explainable vector space before reconstructing and feeding them back into the model. Furthermore, we eliminate the need for a human-selected concept set by algorithmically searching an ontology for a set of concepts that can be either task-specific or task-agnostic. We evaluate CLs across multiple tasks, demonstrating that they maintain the original model's performance and agreement while enabling meaningful interventions. Additionally, we present a proof of concept showcasing an intervenability interface, allowing users to adjust model behavior dynamically, such as mitigating biases during inference.
Anytime Generation of Counterfactual Explanations for Text Classification
Nov 01, 2022In many machine learning applications, it is important for the user to understand the reasoning behind the recommendation or prediction of the classifiers. The learned models, however, are often too complicated to be understood by a human. Research from the social sciences indicates that humans prefer counterfactual explanations over alternatives. In this paper, we present a general framework for generating counterfactual explanations in the textual domain. Our framework is model-agnostic, representation-agnostic, domain-agnostic, and anytime. We model the task as a search problem in a space where the initial state is the classified text, and the goal state is a text in the complementary class. The operators transform a text by replacing parts of it. Our framework includes domain-independent operators, but can also exploit domain-specific knowledge through specialized operators. The search algorithm attempts to find a text from the complementary class with minimal word-level Levenshtein distance from the original classified object.
Knowledge-Based Learning through Feature Generation
Jun 06, 2020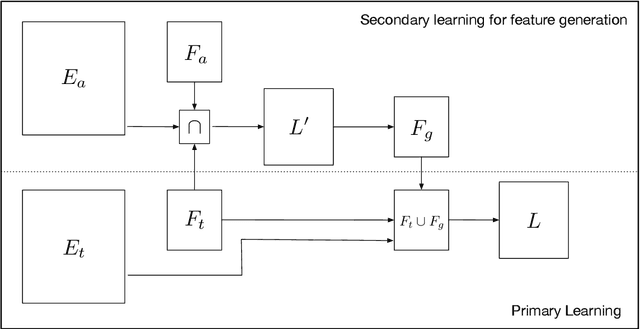
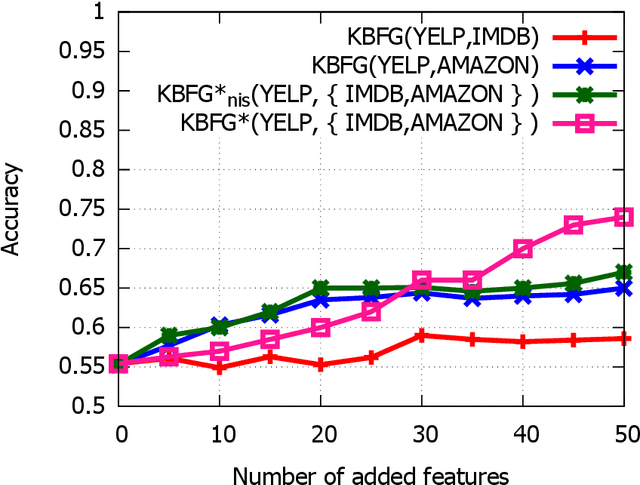
Machine learning algorithms have difficulties to generalize over a small set of examples. Humans can perform such a task by exploiting vast amount of background knowledge they possess. One method for enhancing learning algorithms with external knowledge is through feature generation. In this paper, we introduce a new algorithm for generating features based on a collection of auxiliary datasets. We assume that, in addition to the training set, we have access to additional datasets. Unlike the transfer learning setup, we do not assume that the auxiliary datasets represent learning tasks that are similar to our original one. The algorithm finds features that are common to the training set and the auxiliary datasets. Based on these features and examples from the auxiliary datasets, it induces predictors for new features from the auxiliary datasets. The induced predictors are then added to the original training set as generated features. Our method was tested on a variety of learning tasks, including text classification and medical prediction, and showed a significant improvement over using just the given features.
A Two-Stage Masked LM Method for Term Set Expansion
May 03, 2020
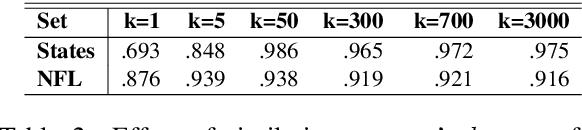
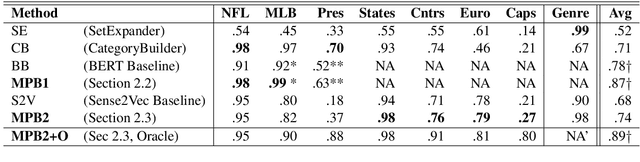

We tackle the task of Term Set Expansion (TSE): given a small seed set of example terms from a semantic class, finding more members of that class. The task is of great practical utility, and also of theoretical utility as it requires generalization from few examples. Previous approaches to the TSE task can be characterized as either distributional or pattern-based. We harness the power of neural masked language models (MLM) and propose a novel TSE algorithm, which combines the pattern-based and distributional approaches. Due to the small size of the seed set, fine-tuning methods are not effective, calling for more creative use of the MLM. The gist of the idea is to use the MLM to first mine for informative patterns with respect to the seed set, and then to obtain more members of the seed class by generalizing these patterns. Our method outperforms state-of-the-art TSE algorithms. Implementation is available at: https://github.com/ guykush/TermSetExpansion-MPB/
Textual Membership Queries
May 11, 2018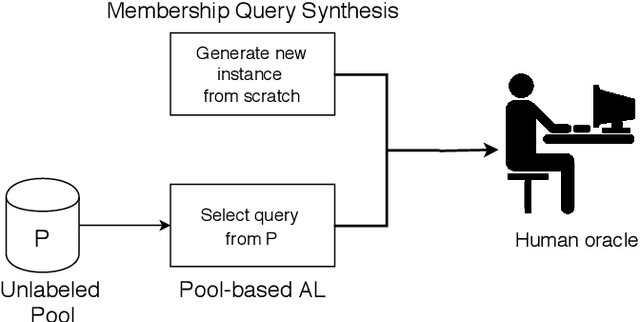
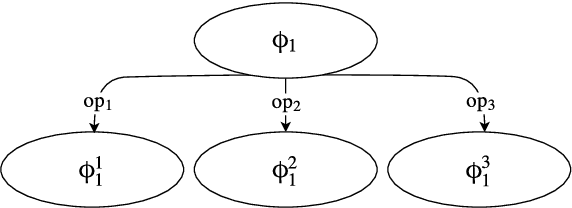
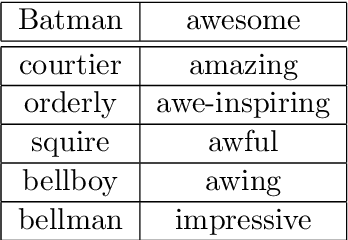
Human labeling of textual data can be very time-consuming and expensive, yet it is critical for the success of an automatic text classification system. In order to minimize human labeling efforts, we propose a novel active learning (AL) solution, that does not rely on existing sources of unlabeled data. It uses a small amount of labeled data as the core set for the synthesis of useful membership queries (MQs) - unlabeled instances synthesized by an algorithm for human labeling. Our solution uses modification operators, functions from the instance space to the instance space that change the input to some extent. We apply the operators on the core set, thus creating a set of new membership queries. Using this framework, we look at the instance space as a search space and apply search algorithms in order to create desirable MQs. We implement this framework in the textual domain. The implementation includes using methods such as WordNet and Word2vec, for replacing text fragments from a given sentence with semantically related ones. We test our framework on several text classification tasks and show improved classifier performance as more MQs are labeled and incorporated into the training set. To the best of our knowledge, this is the first work on membership queries in the textual domain.
Automatic Generation of Language-Independent Features for Cross-Lingual Classification
Feb 12, 2018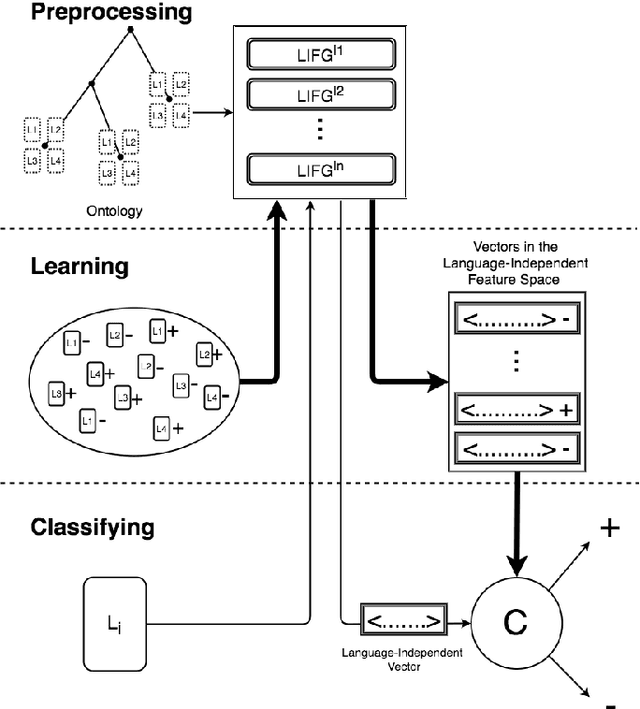
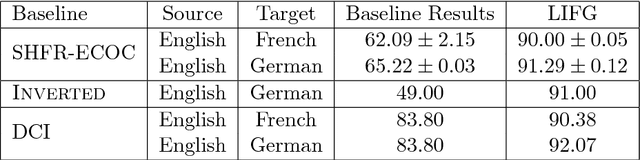

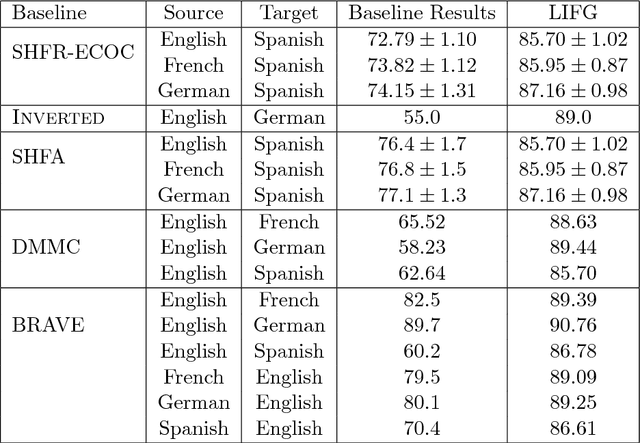
Many applications require categorization of text documents using predefined categories. The main approach to performing text categorization is learning from labeled examples. For many tasks, it may be difficult to find examples in one language but easy in others. The problem of learning from examples in one or more languages and classifying (categorizing) in another is called cross-lingual learning. In this work, we present a novel approach that solves the general cross-lingual text categorization problem. Our method generates, for each training document, a set of language-independent features. Using these features for training yields a language-independent classifier. At the classification stage, we generate language-independent features for the unlabeled document, and apply the classifier on the new representation. To build the feature generator, we utilize a hierarchical language-independent ontology, where each concept has a set of support documents for each language involved. In the preprocessing stage, we use the support documents to build a set of language-independent feature generators, one for each language. The collection of these generators is used to map any document into the language-independent feature space. Our methodology works on the most general cross-lingual text categorization problems, being able to learn from any mix of languages and classify documents in any other language. We also present a method for exploiting the hierarchical structure of the ontology to create virtual supporting documents for languages that do not have them. We tested our method, using Wikipedia as our ontology, on the most commonly used test collections in cross-lingual text categorization, and found that it outperforms existing methods.
Recursive Feature Generation for Knowledge-based Learning
Jan 31, 2018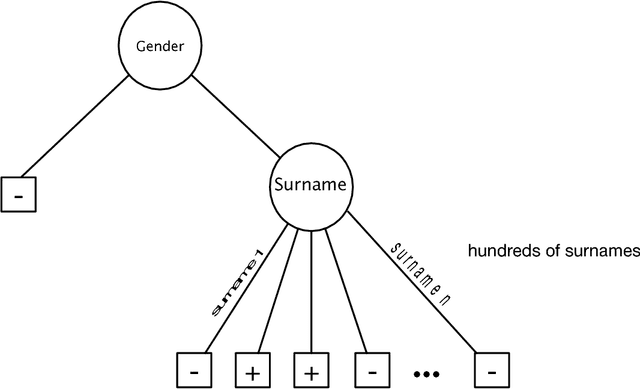
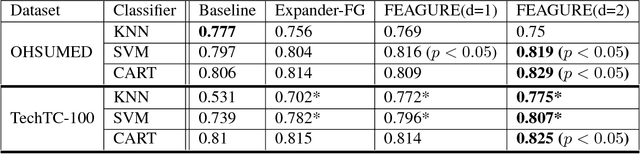
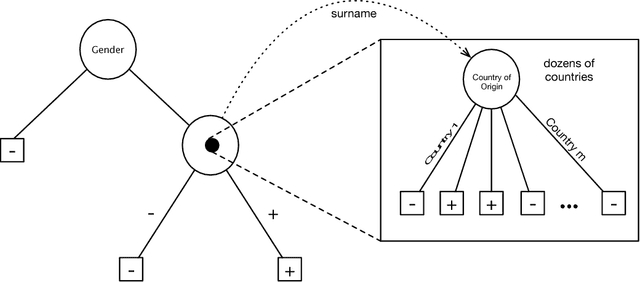
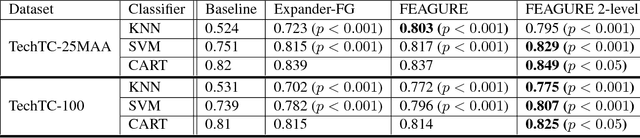
When humans perform inductive learning, they often enhance the process with background knowledge. With the increasing availability of well-formed collaborative knowledge bases, the performance of learning algorithms could be significantly enhanced if a way were found to exploit these knowledge bases. In this work, we present a novel algorithm for injecting external knowledge into induction algorithms using feature generation. Given a feature, the algorithm defines a new learning task over its set of values, and uses the knowledge base to solve the constructed learning task. The resulting classifier is then used as a new feature for the original problem. We have applied our algorithm to the domain of text classification using large semantic knowledge bases. We have shown that the generated features significantly improve the performance of existing learning algorithms.
Named Entity Disambiguation for Noisy Text
Jul 01, 2017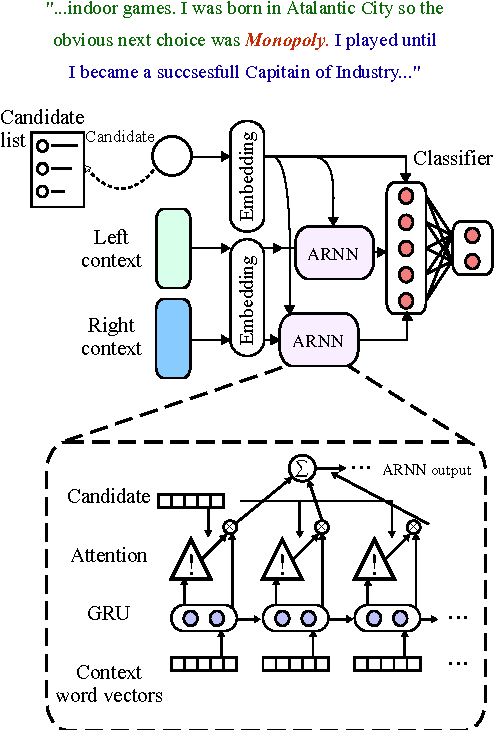
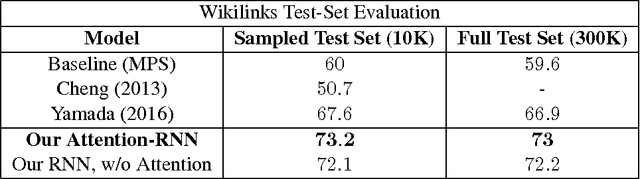
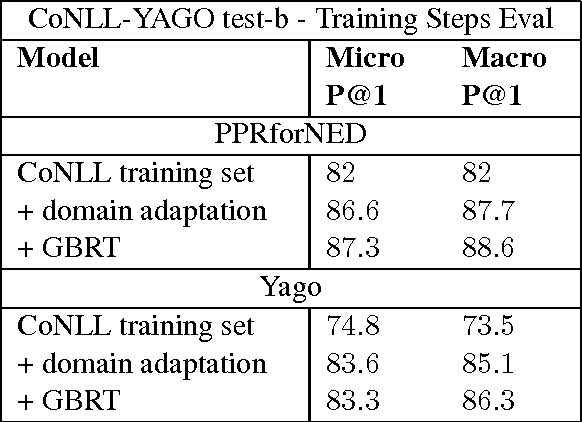
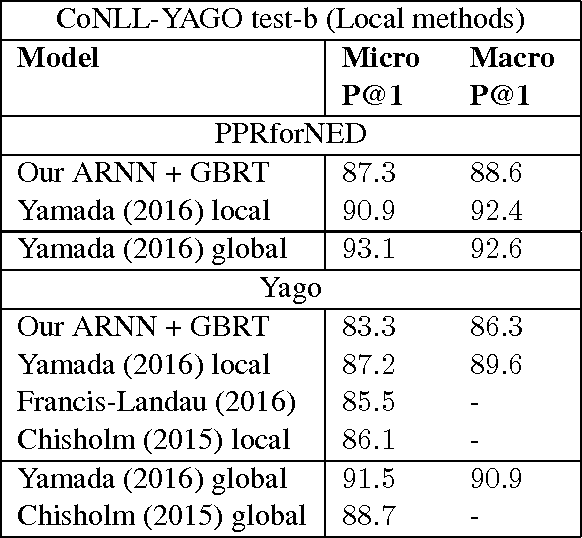
We address the task of Named Entity Disambiguation (NED) for noisy text. We present WikilinksNED, a large-scale NED dataset of text fragments from the web, which is significantly noisier and more challenging than existing news-based datasets. To capture the limited and noisy local context surrounding each mention, we design a neural model and train it with a novel method for sampling informative negative examples. We also describe a new way of initializing word and entity embeddings that significantly improves performance. Our model significantly outperforms existing state-of-the-art methods on WikilinksNED while achieving comparable performance on a smaller newswire dataset.
Learning to Predict from Textual Data
Feb 04, 2014



Given a current news event, we tackle the problem of generating plausible predictions of future events it might cause. We present a new methodology for modeling and predicting such future news events using machine learning and data mining techniques. Our Pundit algorithm generalizes examples of causality pairs to infer a causality predictor. To obtain precisely labeled causality examples, we mine 150 years of news articles and apply semantic natural language modeling techniques to headlines containing certain predefined causality patterns. For generalization, the model uses a vast number of world knowledge ontologies. Empirical evaluation on real news articles shows that our Pundit algorithm performs as well as non-expert humans.
Online Speedup Learning for Optimal Planning
Jan 23, 2014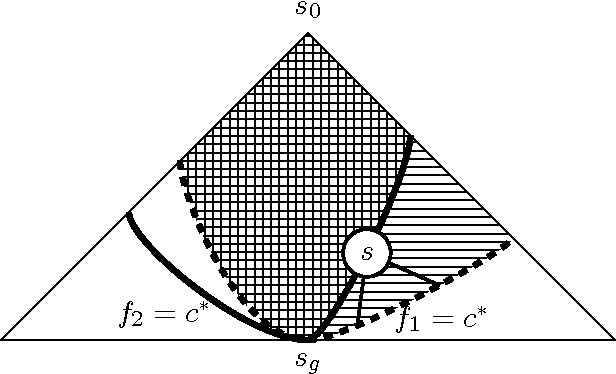
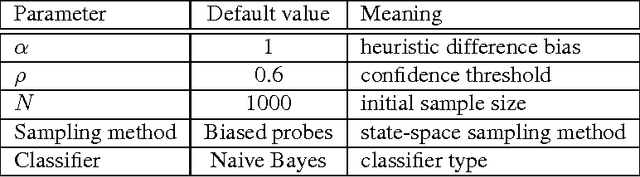
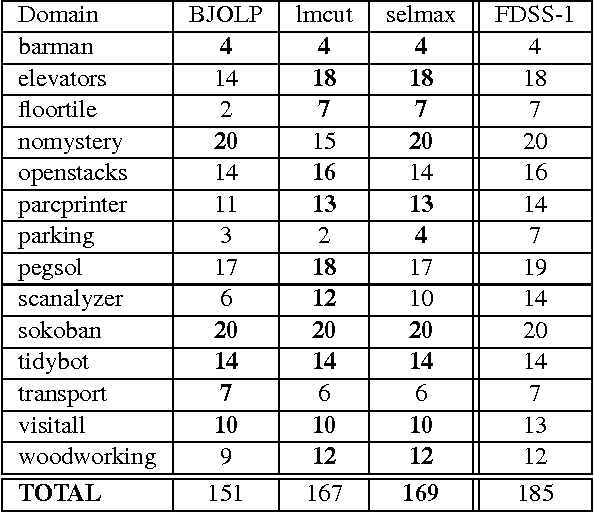
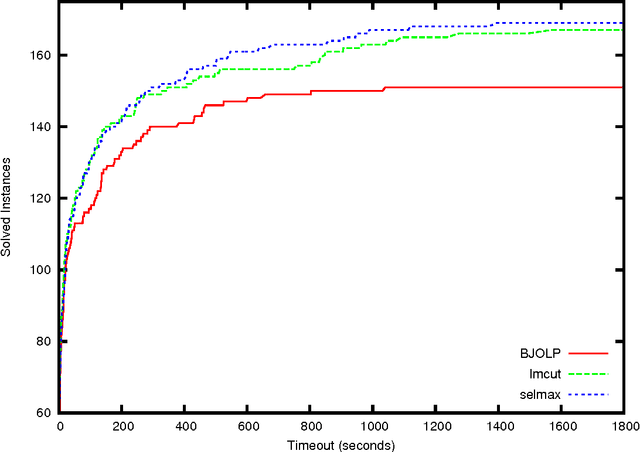
Domain-independent planning is one of the foundational areas in the field of Artificial Intelligence. A description of a planning task consists of an initial world state, a goal, and a set of actions for modifying the world state. The objective is to find a sequence of actions, that is, a plan, that transforms the initial world state into a goal state. In optimal planning, we are interested in finding not just a plan, but one of the cheapest plans. A prominent approach to optimal planning these days is heuristic state-space search, guided by admissible heuristic functions. Numerous admissible heuristics have been developed, each with its own strengths and weaknesses, and it is well known that there is no single "best heuristic for optimal planning in general. Thus, which heuristic to choose for a given planning task is a difficult question. This difficulty can be avoided by combining several heuristics, but that requires computing numerous heuristic estimates at each state, and the tradeoff between the time spent doing so and the time saved by the combined advantages of the different heuristics might be high. We present a novel method that reduces the cost of combining admissible heuristics for optimal planning, while maintaining its benefits. Using an idealized search space model, we formulate a decision rule for choosing the best heuristic to compute at each state. We then present an active online learning approach for learning a classifier with that decision rule as the target concept, and employ the learned classifier to decide which heuristic to compute at each state. We evaluate this technique empirically, and show that it substantially outperforms the standard method for combining several heuristics via their pointwise maximum.