 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Generation of Language-Independent Features for Cross-Lingual Classification
Paper and Code
Feb 12, 2018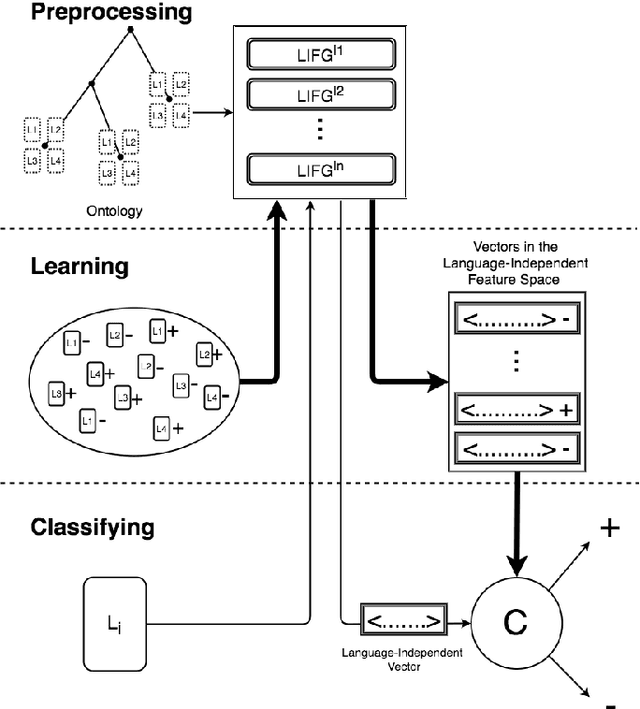
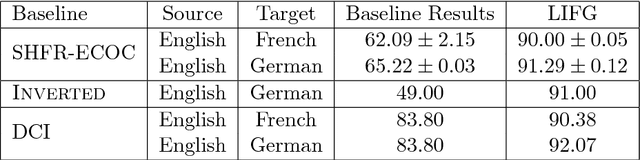

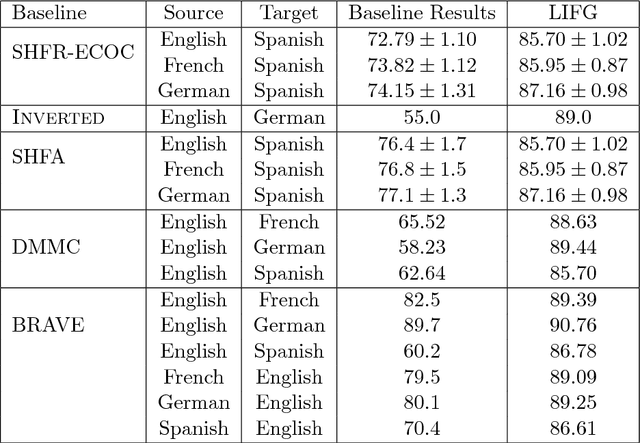
Many applications require categorization of text documents using predefined categories. The main approach to performing text categorization is learning from labeled examples. For many tasks, it may be difficult to find examples in one language but easy in others. The problem of learning from examples in one or more languages and classifying (categorizing) in another is called cross-lingual learning. In this work, we present a novel approach that solves the general cross-lingual text categorization problem. Our method generates, for each training document, a set of language-independent features. Using these features for training yields a language-independent classifier. At the classification stage, we generate language-independent features for the unlabeled document, and apply the classifier on the new representation. To build the feature generator, we utilize a hierarchical language-independent ontology, where each concept has a set of support documents for each language involved. In the preprocessing stage, we use the support documents to build a set of language-independent feature generators, one for each language. The collection of these generators is used to map any document into the language-independent feature space. Our methodology works on the most general cross-lingual text categorization problems, being able to learn from any mix of languages and classify documents in any other language. We also present a method for exploiting the hierarchical structure of the ontology to create virtual supporting documents for languages that do not have them. We tested our method, using Wikipedia as our ontology, on the most commonly used test collections in cross-lingual text categorization, and found that it outperforms existing methods.