 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lean Data Scientist: Recent Advances towards Overcoming the Data Bottleneck
Nov 15, 2022



Machine learning (ML) is revolutionizing the world, affecting almost every field of science and industry. Recent algorithms (in particular, deep networks) are increasingly data-hungry, requiring large datasets for training. Thus, the dominant paradigm in ML today involves constructing large, task-specific datasets. However, obtaining quality datasets of such magnitude proves to be a difficult challenge. A variety of methods have been proposed to address this data bottleneck problem, but they are scattered across different areas, and it is hard for a practitioner to keep up with the latest developments. In this work, we propose a taxonomy of these methods. Our goal is twofold: (1) We wish to raise the community's awareness of the methods that already exist and encourage more efficient use of resources, and (2) we hope that such a taxonomy will contribute to our understanding of the problem, inspiring novel ideas and strategies to replace current annotation-heavy approaches.
Topo2vec: Topography Embedding Using the Fractal Effect
Aug 19, 2021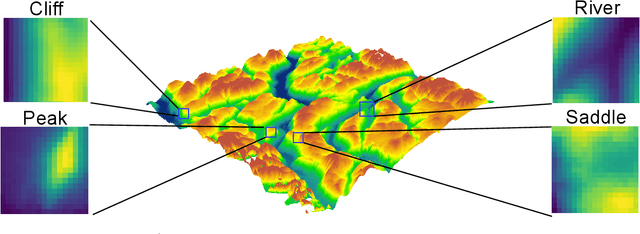

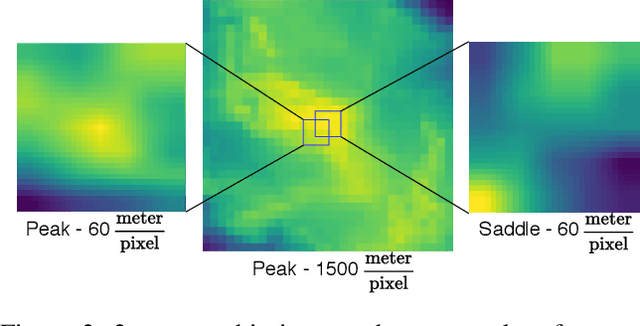
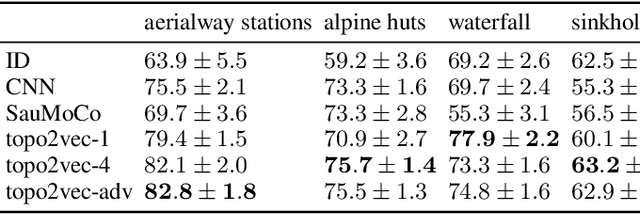
Recent advances in deep learning have transformed many fields by introducing generic embedding spaces, capable of achieving great predictive performance with minimal labeling effort. The geology field has not yet met such success. In this work, we introduce an extension for self-supervised learning techniques tailored for exploiting the fractal-effect in remote-sensing images. The fractal-effect assumes that the same structures (for example rivers, peaks and saddles) will appear in all scales. We demonstrate our method's effectiveness on elevation data, we also use the effect in inference. We perform an extensive analysis on several classification tasks and emphasize its effectiveness in detecting the same class on different scales. To the best of our knowledge, it is the first attempt to build a generic representation for topographic images.
Textual Membership Queries
May 11, 2018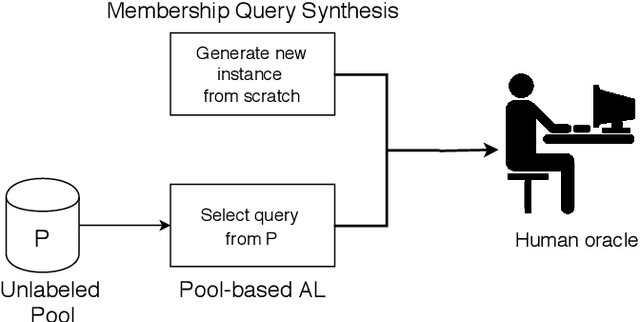
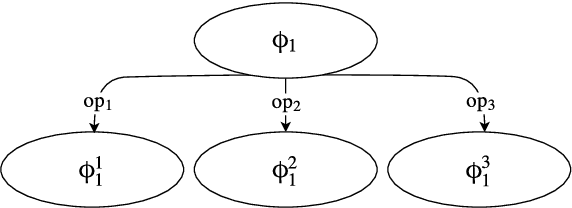
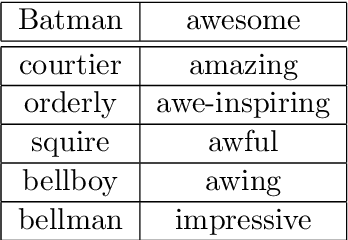
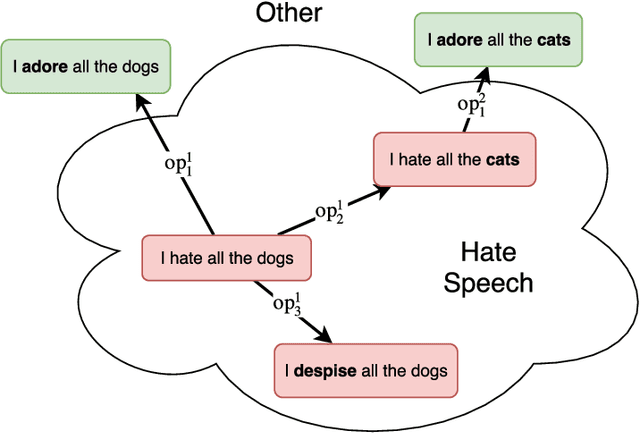
Human labeling of textual data can be very time-consuming and expensive, yet it is critical for the success of an automatic text classification system. In order to minimize human labeling efforts, we propose a novel active learning (AL) solution, that does not rely on existing sources of unlabeled data. It uses a small amount of labeled data as the core set for the synthesis of useful membership queries (MQs) - unlabeled instances synthesized by an algorithm for human labeling. Our solution uses modification operators, functions from the instance space to the instance space that change the input to some extent. We apply the operators on the core set, thus creating a set of new membership queries. Using this framework, we look at the instance space as a search space and apply search algorithms in order to create desirable MQs. We implement this framework in the textual domain. The implementation includes using methods such as WordNet and Word2vec, for replacing text fragments from a given sentence with semantically related ones. We test our framework on several text classification tasks and show improved classifier performance as more MQs are labeled and incorporated into the training set. To the best of our knowledge, this is the first work on membership queries in the textual domain.