 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Tokens: Concept-Level Training Objectives for LLMs
Jan 16, 2026The next-token prediction (NTP) objective has been foundational in the development of modern large language models (LLMs), driving advances in fluency and generalization. However, NTP operates at the \textit{token} level, treating deviations from a single reference continuation as errors even when alternative continuations are equally plausible or semantically equivalent (e.g., ``mom'' vs. ``mother''). As a result, token-level loss can penalize valid abstractions, paraphrases, or conceptually correct reasoning paths, biasing models toward surface form rather than underlying meaning. This mismatch between the training signal and semantic correctness motivates learning objectives that operate over higher-level representations. We propose a shift from token-level to concept-level prediction, where concepts group multiple surface forms of the same idea (e.g., ``mom,'' ``mommy,'' ``mother'' $\rightarrow$ \textit{MOTHER}). We introduce various methods for integrating conceptual supervision into LLM training and show that concept-aware models achieve lower perplexity, improved robustness under domain shift, and stronger performance than NTP-based models on diverse NLP benchmarks. This suggests \textit{concept-level supervision} as an improved training signal that better aligns LLMs with human semantic abstractions.
The Roots of Performance Disparity in Multilingual Language Models: Intrinsic Modeling Difficulty or Design Choices?
Jan 12, 2026Multilingual language models (LMs) promise broader NLP access, yet current systems deliver uneven performance across the world's languages. This survey examines why these gaps persist and whether they reflect intrinsic linguistic difficulty or modeling artifacts. We organize the literature around two questions: do linguistic disparities arise from representation and allocation choices (e.g., tokenization, encoding, data exposure, parameter sharing) rather than inherent complexity; and which design choices mitigate inequities across typologically diverse languages. We review linguistic features, such as orthography, morphology, lexical diversity, syntax, information density, and typological distance, linking each to concrete modeling mechanisms. Gaps often shrink when segmentation, encoding, and data exposure are normalized, suggesting much apparent difficulty stems from current modeling choices. We synthesize these insights into design recommendations for tokenization, sampling, architectures, and evaluation to support more balanced multilingual LMs.
Categorize Early, Integrate Late: Divergent Processing Strategies in Automatic Speech Recognition
Jan 11, 2026In speech language modeling, two architectures dominate the frontier: the Transformer and the Conformer. However, it remains unknown whether their comparable performance stems from convergent processing strategies or distinct architectural inductive biases. We introduce Architectural Fingerprinting, a probing framework that isolates the effect of architecture on representation, and apply it to a controlled suite of 24 pre-trained encoders (39M-3.3B parameters). Our analysis reveals divergent hierarchies: Conformers implement a "Categorize Early" strategy, resolving phoneme categories 29% earlier in depth and speaker gender by 16% depth. In contrast, Transformers "Integrate Late," deferring phoneme, accent, and duration encoding to deep layers (49-57%). These fingerprints suggest design heuristics: Conformers' front-loaded categorization may benefit low-latency streaming, while Transformers' deep integration may favor tasks requiring rich context and cross-utterance normalization.
Bridged Clustering for Representation Learning: Semi-Supervised Sparse Bridging
Oct 08, 2025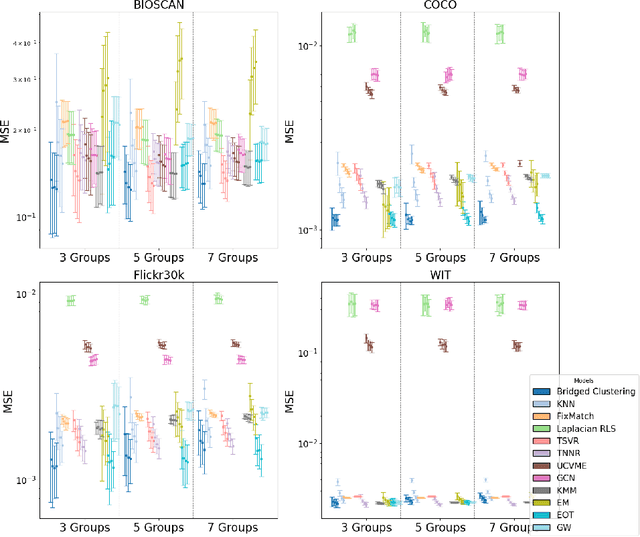
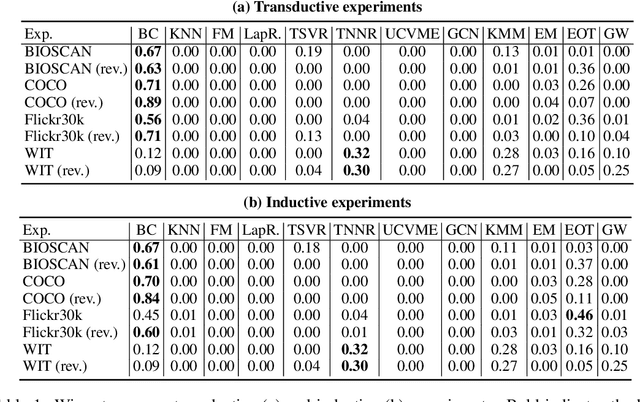

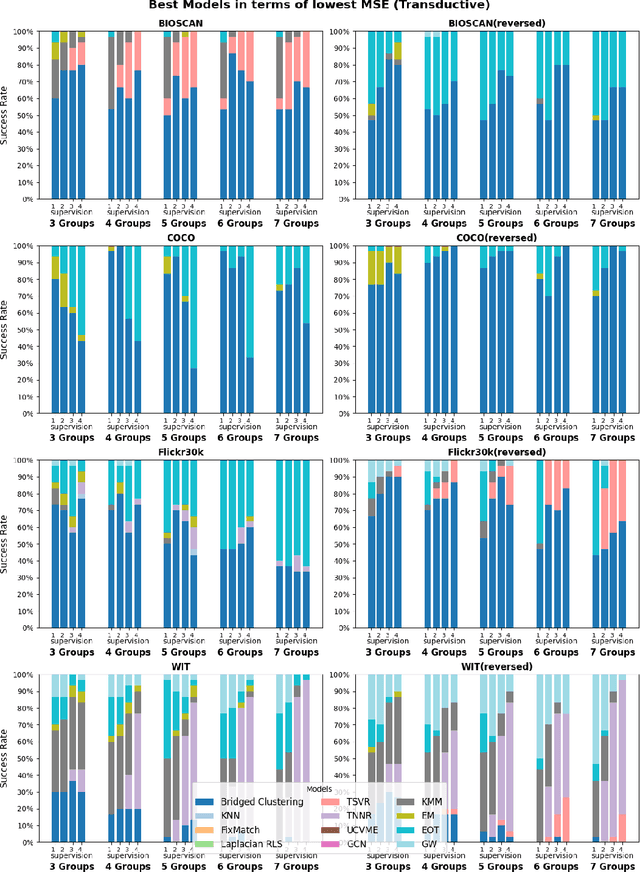
We introduce Bridged Clustering, a semi-supervised framework to learn predictors from any unpaired input $X$ and output $Y$ dataset. Our method first clusters $X$ and $Y$ independently, then learns a sparse, interpretable bridge between clusters using only a few paired examples. At inference, a new input $x$ is assigned to its nearest input cluster, and the centroid of the linked output cluster is returned as the prediction $\hat{y}$. Unlike traditional SSL, Bridged Clustering explicitly leverages output-only data, and unlike dense transport-based methods, it maintains a sparse and interpretable alignment. Through theoretical analysis, we show that with bounded mis-clustering and mis-bridging rates, our algorithm becomes an effective and efficient predictor. Empirically, our method is competitive with SOTA methods while remaining simple, model-agnostic, and highly label-efficient in low-supervision settings.
One Joke to Rule them All? On the (Im)possibility of Generalizing Humor
Aug 26, 2025


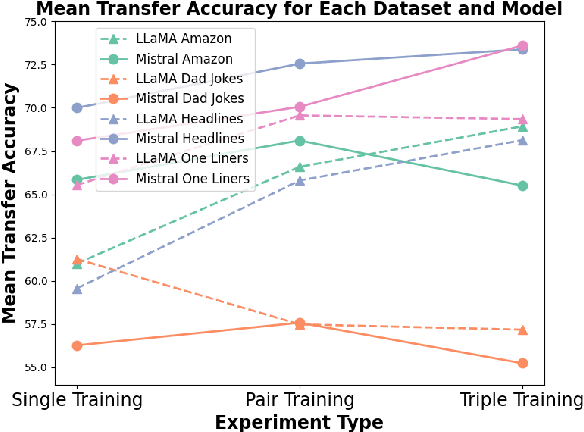
Humor is a broad and complex form of communication that remains challenging for machines. Despite its broadness, most existing research on computational humor traditionally focused on modeling a specific type of humor. In this work, we wish to understand whether competence on one or more specific humor tasks confers any ability to transfer to novel, unseen types; in other words, is this fragmentation inevitable? This question is especially timely as new humor types continuously emerge in online and social media contexts (e.g., memes, anti-humor, AI fails). If Large Language Models (LLMs) are to keep up with this evolving landscape, they must be able to generalize across humor types by capturing deeper, transferable mechanisms. To investigate this, we conduct a series of transfer learning experiments across four datasets, representing different humor tasks. We train LLMs under varied diversity settings (1-3 datasets in training, testing on a novel task). Experiments reveal that models are capable of some transfer, and can reach up to 75% accuracy on unseen datasets; training on diverse sources improves transferability (1.88-4.05%) with minimal-to-no drop in in-domain performance. Further analysis suggests relations between humor types, with Dad Jokes surprisingly emerging as the best enabler of transfer (but is difficult to transfer to). We release data and code.
From Tokens to Thoughts: How LLMs and Humans Trade Compression for Meaning
May 21, 2025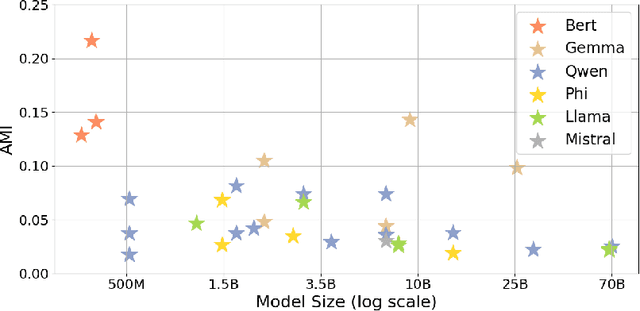
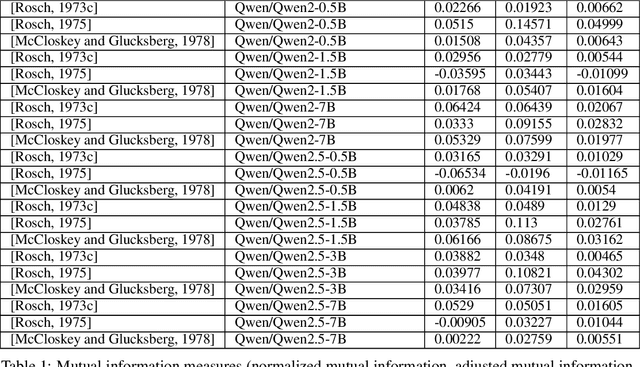
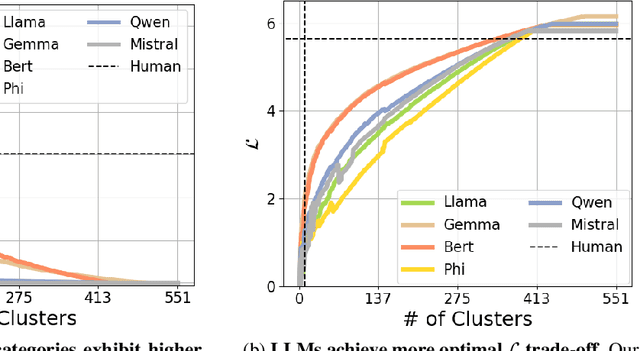
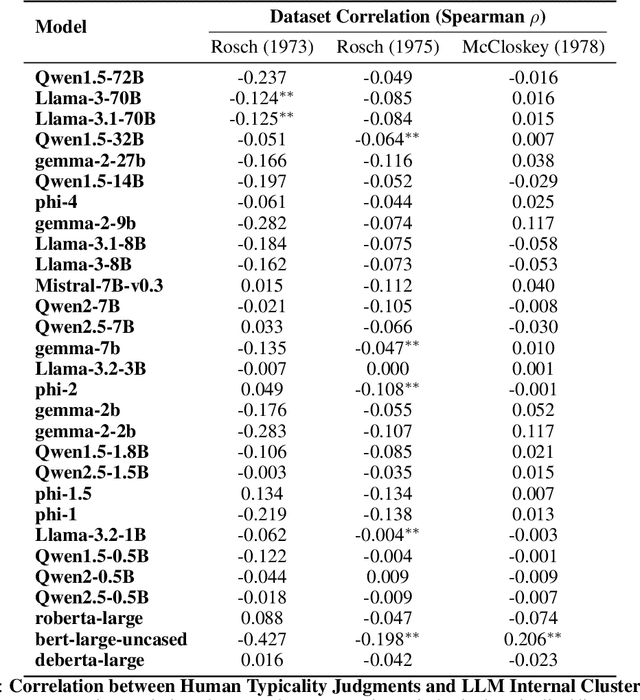
Humans organize knowledge into compact categories through semantic compression by mapping diverse instances to abstract representations while preserving meaning (e.g., robin and blue jay are both birds; most birds can fly). These concepts reflect a trade-off between expressive fidelity and representational simplicity. Large Language Models (LLMs) demonstrate remarkable linguistic abilities, yet whether their internal representations strike a human-like trade-off between compression and semantic fidelity is unclear. We introduce a novel information-theoretic framework, drawing from Rate-Distortion Theory and the Information Bottleneck principle, to quantitatively compare these strategies. Analyzing token embeddings from a diverse suite of LLMs against seminal human categorization benchmarks, we uncover key divergences. While LLMs form broad conceptual categories that align with human judgment, they struggle to capture the fine-grained semantic distinctions crucial for human understanding. More fundamentally, LLMs demonstrate a strong bias towards aggressive statistical compression, whereas human conceptual systems appear to prioritize adaptive nuance and contextual richness, even if this results in lower compressional efficiency by our measures. These findings illuminate critical differences between current AI and human cognitive architectures, guiding pathways toward LLMs with more human-aligned conceptual representations.
Cooking Up Creativity: A Cognitively-Inspired Approach for Enhancing LLM Creativity through Structured Representations
Apr 29, 2025Large Language Models (LLMs) excel at countless tasks, yet struggle with creativity. In this paper, we introduce a novel approach that couples LLMs with structured representations and cognitively inspired manipulations to generate more creative and diverse ideas. Our notion of creativity goes beyond superficial token-level variations; rather, we explicitly recombine structured representations of existing ideas, allowing our algorithm to effectively explore the more abstract landscape of ideas. We demonstrate our approach in the culinary domain with DishCOVER, a model that generates creative recipes. Experiments comparing our model's results to those of GPT-4o show greater diversity. Domain expert evaluations reveal that our outputs, which are mostly coherent and feasible culinary creations, significantly surpass GPT-4o in terms of novelty, thus outperforming it in creative generation. We hope our work inspires further research into structured creativity in AI.
Labeling Messages as AI-Generated Does Not Reduce Their Persuasive Effects
Apr 14, 2025



As generative artificial intelligence (AI) enables the creation and dissemination of information at massive scale and speed, it is increasingly important to understand how people perceive AI-generated content. One prominent policy proposal requires explicitly labeling AI-generated content to increase transparency and encourage critical thinking about the information, but prior research has not yet tested the effects of such labels. To address this gap, we conducted a survey experiment (N=1601) on a diverse sample of Americans, presenting participants with an AI-generated message about several public policies (e.g., allowing colleges to pay student-athletes), randomly assigning whether participants were told the message was generated by (a) an expert AI model, (b) a human policy expert, or (c) no label. We found that messages were generally persuasive, influencing participants' views of the policies by 9.74 percentage points on average. However, while 94.6% of participants assigned to the AI and human label conditions believed the authorship labels, labels had no significant effects on participants' attitude change toward the policies, judgments of message accuracy, nor intentions to share the message with others. These patterns were robust across a variety of participant characteristics, including prior knowledge of the policy, prior experience with AI, political party, education level, or age. Taken together, these results imply that, while authorship labels would likely enhance transparency, they are unlikely to substantially affect the persuasiveness of the labeled content, highlighting the need for alternative strategies to address challenges posed by AI-generated information.
Rethinking Word Similarity: Semantic Similarity through Classification Confusion
Feb 08, 2025Word similarity has many applications to social science and cultural analytics tasks like measuring meaning change over time and making sense of contested terms. Yet traditional similarity methods based on cosine similarity between word embeddings cannot capture the context-dependent, asymmetrical, polysemous nature of semantic similarity. We propose a new measure of similarity, Word Confusion, that reframes semantic similarity in terms of feature-based classification confusion. Word Confusion is inspired by Tversky's suggestion that similarity features be chosen dynamically. Here we train a classifier to map contextual embeddings to word identities and use the classifier confusion (the probability of choosing a confounding word c instead of the correct target word t) as a measure of the similarity of c and t. The set of potential confounding words acts as the chosen features. Our method is comparable to cosine similarity in matching human similarity judgments across several datasets (MEN, WirdSim353, and SimLex), and can measure similarity using predetermined features of interest. We demonstrate our model's ability to make use of dynamic features by applying it to test a hypothesis about changes in the 18th C. meaning of the French word "revolution" from popular to state action during the French Revolution. We hope this reimagining of semantic similarity will inspire the development of new tools that better capture the multi-faceted and dynamic nature of language, advancing the fields of computational social science and cultural analytics and beyond.
Towards Concept-Aware Large Language Models
Nov 03, 2023



Concepts play a pivotal role in various human cognitive functions, including learning, reasoning and communication. However, there is very little work on endowing machines with the ability to form and reason with concepts. In particular, state-of-the-art large language models (LLMs) work at the level of tokens, not concepts. In this work, we analyze how well contemporary LLMs capture human concepts and their structure. We then discuss ways to develop concept-aware LLMs, taking place at different stages of the pipeline. We sketch a method for pretraining LLMs using concepts, and also explore the simpler approach that uses the output of existing LLMs. Despite its simplicity, our proof-of-concept is shown to better match human intuition, as well as improve the robustness of predictions. These preliminary results underscore the promise of concept-aware LLMs.