 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveRAG: A diverse Q&A dataset with varying difficulty level for RAG evaluation
Nov 18, 2025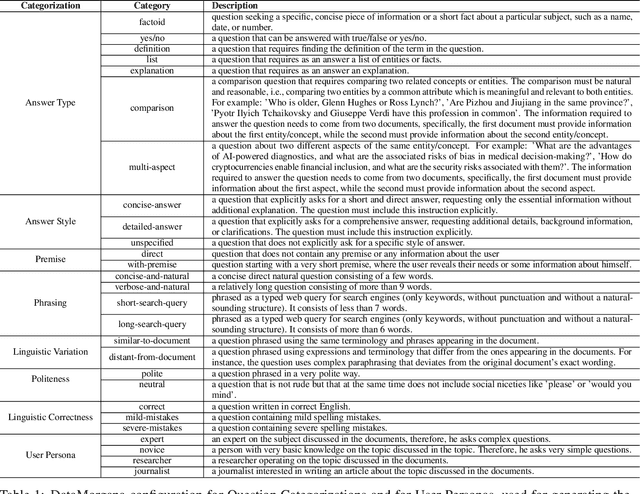
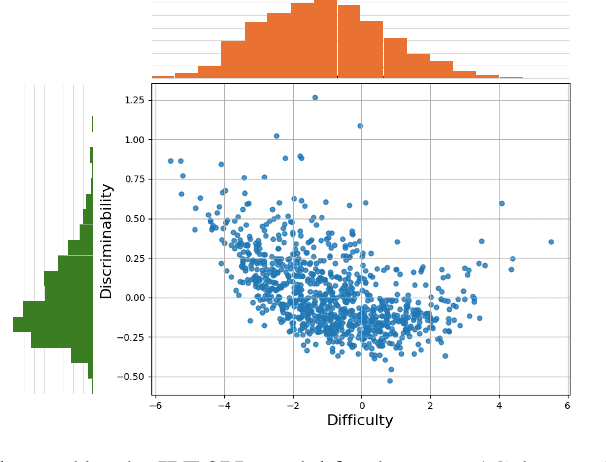
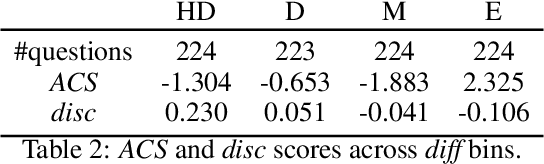
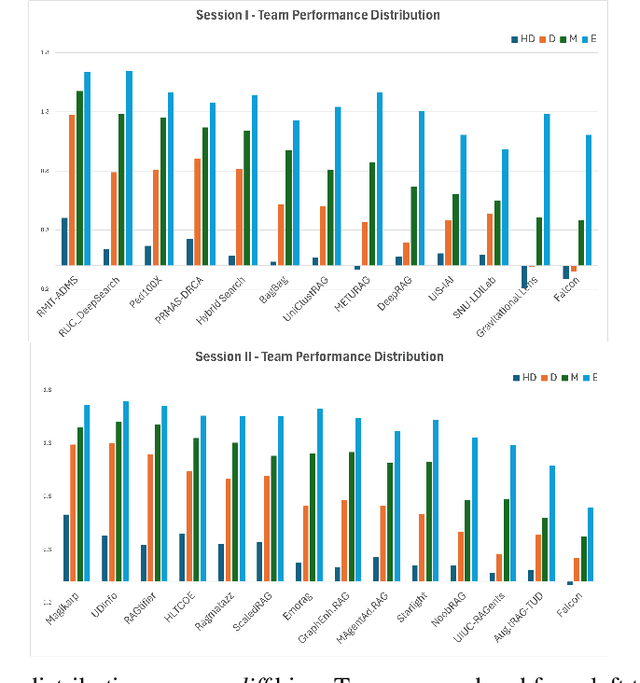
With Retrieval Augmented Generation (RAG) becoming more and more prominent in generative AI solutions, there is an emerging need for systematically evaluating their effectiveness. We introduce the LiveRAG benchmark, a publicly available dataset of 895 synthetic questions and answers designed to support systematic evaluation of RAG-based Q&A systems. This synthetic benchmark is derived from the one used during the SIGIR'2025 LiveRAG Challenge, where competitors were evaluated under strict time constraints. It is augmented with information that was not made available to competitors during the Challenge, such as the ground-truth answers, together with their associated supporting claims which were used for evaluating competitors' answers. In addition, each question is associated with estimated difficulty and discriminability scores, derived from applying an Item Response Theory model to competitors' responses. Our analysis highlights the benchmark's questions diversity, the wide range of their difficulty levels, and their usefulness in differentiating between system capabilities. The LiveRAG benchmark will hopefully help the community advance RAG research, conduct systematic evaluation, and develop more robust Q&A systems.
Redefining Retrieval Evaluation in the Era of LLMs
Oct 24, 2025Traditional Information Retrieval (IR) metrics, such as nDCG, MAP, and MRR, assume that human users sequentially examine documents with diminishing attention to lower ranks. This assumption breaks down in Retrieval Augmented Generation (RAG) systems, where search results are consumed by Large Language Models (LLMs), which, unlike humans, process all retrieved documents as a whole rather than sequentially. Additionally, traditional IR metrics do not account for related but irrelevant documents that actively degrade generation quality, rather than merely being ignored. Due to these two major misalignments, namely human vs. machine position discount and human relevance vs. machine utility, classical IR metrics do not accurately predict RAG performance. We introduce a utility-based annotation schema that quantifies both the positive contribution of relevant passages and the negative impact of distracting ones. Building on this foundation, we propose UDCG (Utility and Distraction-aware Cumulative Gain), a metric using an LLM-oriented positional discount to directly optimize the correlation with the end-to-end answer accuracy. Experiments on five datasets and six LLMs demonstrate that UDCG improves correlation by up to 36% compared to traditional metrics. Our work provides a critical step toward aligning IR evaluation with LLM consumers and enables more reliable assessment of RAG components
Do RAG Systems Suffer From Positional Bias?
May 21, 2025Retrieval Augmented Generation enhances LLM accuracy by adding passages retrieved from an external corpus to the LLM prompt. This paper investigates how positional bias - the tendency of LLMs to weight information differently based on its position in the prompt - affects not only the LLM's capability to capitalize on relevant passages, but also its susceptibility to distracting passages. Through extensive experiments on three benchmarks, we show how state-of-the-art retrieval pipelines, while attempting to retrieve relevant passages, systematically bring highly distracting ones to the top ranks, with over 60% of queries containing at least one highly distracting passage among the top-10 retrieved passages. As a result, the impact of the LLM positional bias, which in controlled settings is often reported as very prominent by related works, is actually marginal in real scenarios since both relevant and distracting passages are, in turn, penalized. Indeed, our findings reveal that sophisticated strategies that attempt to rearrange the passages based on LLM positional preferences do not perform better than random shuffling.
The Power of Noise: Redefining Retrieval for RAG Systems
Jan 29, 2024



Retrieval-Augmented Generation (RAG) systems represent a significant advancement over traditional Large Language Models (LLMs). RAG systems enhance their generation ability by incorporating external data retrieved through an Information Retrieval (IR) phase, overcoming the limitations of standard LLMs, which are restricted to their pre-trained knowledge and limited context window. Most research in this area has predominantly concentrated on the generative aspect of LLMs within RAG systems. Our study fills this gap by thoroughly and critically analyzing the influence of IR components on RAG systems. This paper analyzes which characteristics a retriever should possess for an effective RAG's prompt formulation, focusing on the type of documents that should be retrieved. We evaluate various elements, such as the relevance of the documents to the prompt, their position, and the number included in the context. Our findings reveal, among other insights, that including irrelevant documents can unexpectedly enhance performance by more than 30% in accuracy, contradicting our initial assumption of diminished quality. These results underscore the need for developing specialized strategies to integrate retrieval with language generation models, thereby laying the groundwork for future research in this field.
Alexa, Let's Work Together: Introducing the First Alexa Prize TaskBot Challenge on Conversational Task Assistance
Sep 13, 2022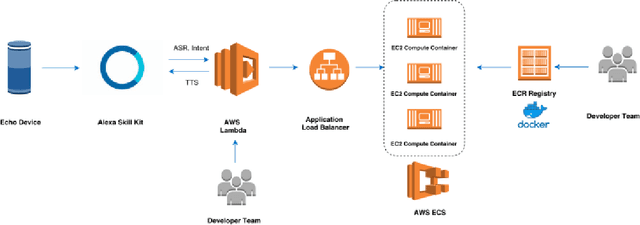
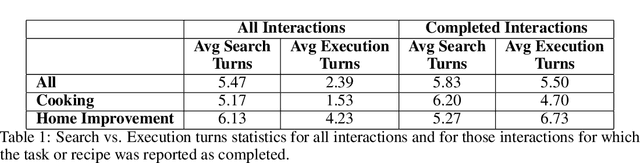
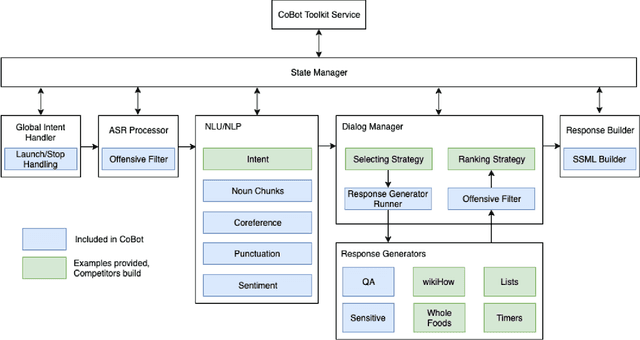

Since its inception in 2016, the Alexa Prize program has enabled hundreds of university students to explore and compete to develop conversational agents through the SocialBot Grand Challenge. The goal of the challenge is to build agents capable of conversing coherently and engagingly with humans on popular topics for 20 minutes, while achieving an average rating of at least 4.0/5.0. However, as conversational agents attempt to assist users with increasingly complex tasks, new conversational AI techniques and evaluation platforms are needed. The Alexa Prize TaskBot challenge, established in 2021, builds on the success of the SocialBot challenge by introducing the requirements of interactively assisting humans with real-world Cooking and Do-It-Yourself tasks, while making use of both voice and visual modalities. This challenge requires the TaskBots to identify and understand the user's need, identify and integrate task and domain knowledge into the interaction, and develop new ways of engaging the user without distracting them from the task at hand, among other challenges. This paper provides an overview of the TaskBot challenge, describes the infrastructure support provided to the teams with the CoBot Toolkit, and summarizes the approaches the participating teams took to overcome the research challenges. Finally, it analyzes the performance of the competing TaskBots during the first year of the competition.
"Alexa, what do you do for fun?" Characterizing playful requests with virtual assistants
May 12, 2021

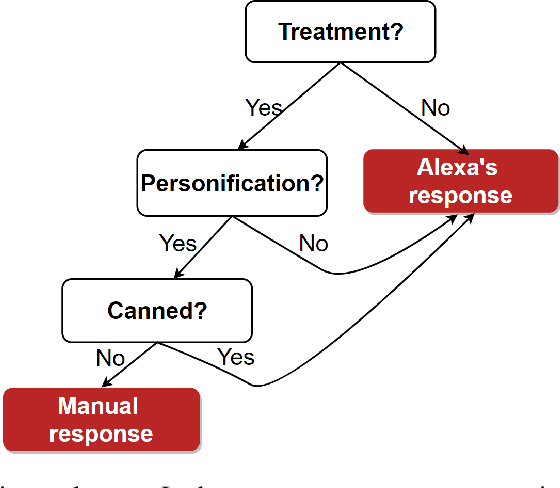

Virtual assistants such as Amazon's Alexa, Apple's Siri, Google Home, and Microsoft's Cortana, are becoming ubiquitous in our daily lives and successfully help users in various daily tasks, such as making phone calls or playing music. Yet, they still struggle with playful utterances, which are not meant to be interpreted literally. Examples include jokes or absurd requests or questions such as, "Are you afraid of the dark?", "Who let the dogs out?", or "Order a zillion gummy bears". Today, virtual assistants often return irrelevant answers to such utterances, except for hard-coded ones addressed by canned replies. To address the challenge of automatically detecting playful utterances, we first characterize the different types of playful human-virtual assistant interaction. We introduce a taxonomy of playful requests rooted in theories of humor and refined by analyzing real-world traffic from Alexa. We then focus on one node, personification, where users refer to the virtual assistant as a person ("What do you do for fun?"). Our conjecture is that understanding such utterances will improve user experience with virtual assistants. We conducted a Wizard-of-Oz user study and showed that endowing virtual assistant s with the ability to identify humorous opportunities indeed has the potential to increase user satisfaction. We hope this work will contribute to the understanding of the landscape of the problem and inspire novel ideas and techniques towards the vision of giving virtual assistants a sense of humor.
Leveraging Crowdsourcing Data For Deep Active Learning - An Application: Learning Intents in Alexa
Mar 12, 2018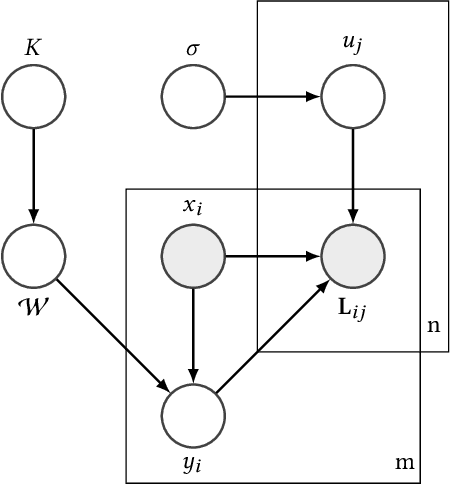

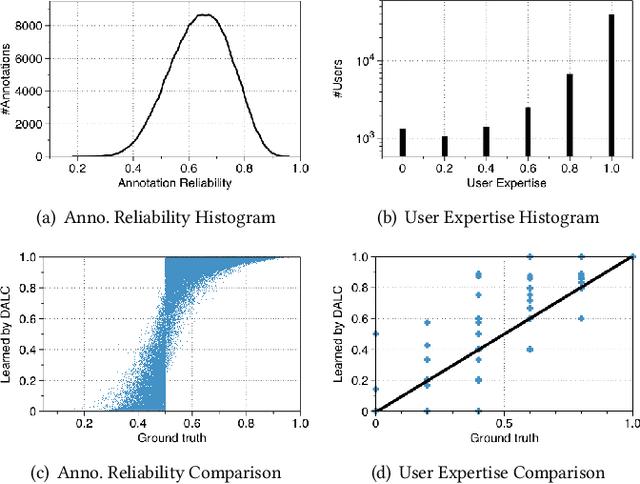

This paper presents a generic Bayesian framework that enables any deep learning model to actively learn from targeted crowds. Our framework inherits from recent advances in Bayesian deep learning, and extends existing work by considering the targeted crowdsourcing approach, where multiple annotators with unknown expertise contribute an uncontrolled amount (often limited) of annotations. Our framework leverages the low-rank structure in annotations to learn individual annotator expertise, which then helps to infer the true labels from noisy and sparse annotations. It provides a unified Bayesian model to simultaneously infer the true labels and train the deep learning model in order to reach an optimal learning efficacy. Finally, our framework exploits the uncertainty of the deep learning model during prediction as well as the annotators' estimated expertise to minimize the number of required annotations and annotators for optimally training the deep learning model. We evaluate the effectiveness of our framework for intent classification in Alexa (Amazon's personal assistant), using both synthetic and real-world datasets. Experiments show that our framework can accurately learn annotator expertise, infer true labels, and effectively reduce the amount of annotations in model training as compared to state-of-the-art approaches. We further discuss the potential of our proposed framework in bridging machine learning and crowdsourcing towards improved human-in-the-loop systems.
How Many Folders Do You Really Need?
Jun 29, 2016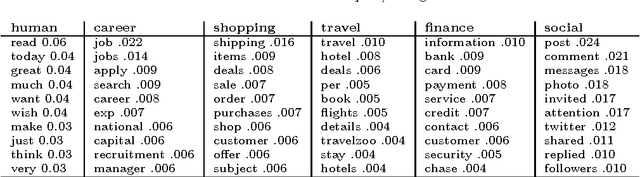
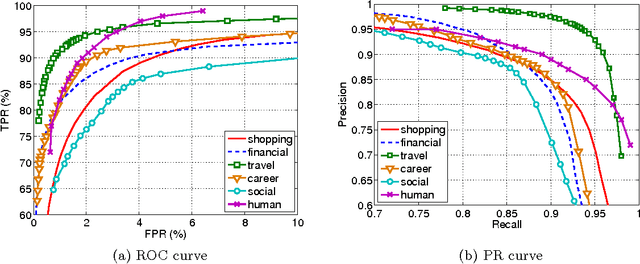
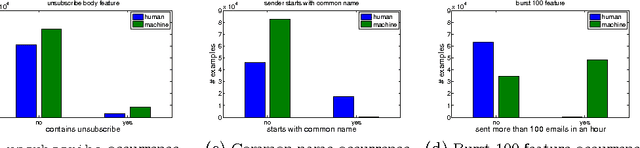

Email classification is still a mostly manual task. Consequently, most Web mail users never define a single folder. Recently however, automatic classification offering the same categories to all users has started to appear in some Web mail clients, such as AOL or Gmail. We adopt this approach, rather than previous (unsuccessful) personalized approaches because of the change in the nature of consumer email traffic, which is now dominated by (non-spam) machine-generated email. We propose here a novel approach for (1) automatically distinguishing between personal and machine-generated email and (2) classifying messages into latent categories, without requiring users to have defined any folder. We report how we have discovered that a set of 6 "latent" categories (one for human- and the others for machine-generated messages) can explain a significant portion of email traffic. We describe in details the steps involved in building a Web-scale email categorization system, from the collection of ground-truth labels, the selection of features to the training of models. Experimental evaluation was performed on more than 500 billion messages received during a period of six months by users of Yahoo mail service, who elected to be part of such research studies. Our system achieved precision and recall rates close to 90% and the latent categories we discovered were shown to cover 70% of both email traffic and email search queries. We believe that these results pave the way for a change of approach in the Web mail industry, and could support the invention of new large-scale email discovery paradigms that had not been possible before.
* 10 pages, 12 figures, Proceedings of the 23rd ACM International Conference on Information and Knowledge Management (CIKM 2014), Shanghai, China