 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocation Aware Embedding for Geotargeting in Sponsored Search Advertising
Mar 14, 2026Web search has become an inevitable part of everyday life. Improving and monetizing web search has been a focus of major Internet players. Understanding the context of web search query is an important aspect of this task as it represents unobserved facts that add meaning to an otherwise incomplete query.The context of a query consists of user's location, local time, search history, behavioral segments, installed apps on their phone and so on. Queries that either explicitly use location context (eg: "best hotels in New York City") or implicitly refer to the user's physical location (e.g. "coffee shops near me") are becoming increasingly common on mobile devices. Understanding and representing the user's interest location and/or physical location is essential for providing a relevant user experience. In this study, we developed a simple and powerful neural embedding based framework to represent a user's query and their location in a single low-dimensional space. We show that this representation is able to capture the subtle interactions between the user's query intent and query/physical location, while improving the ad ranking and query-ad relevance scores over other location-unaware approaches and location-aware approaches.
Revenue Maximization of Airbnb Marketplace using Search Results
Nov 16, 2019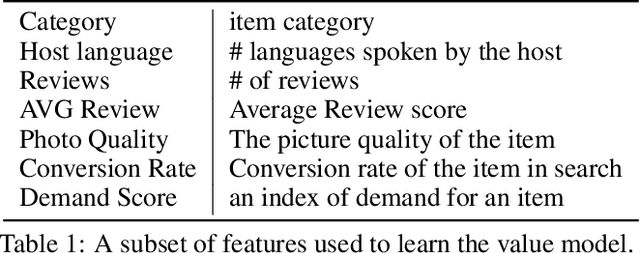
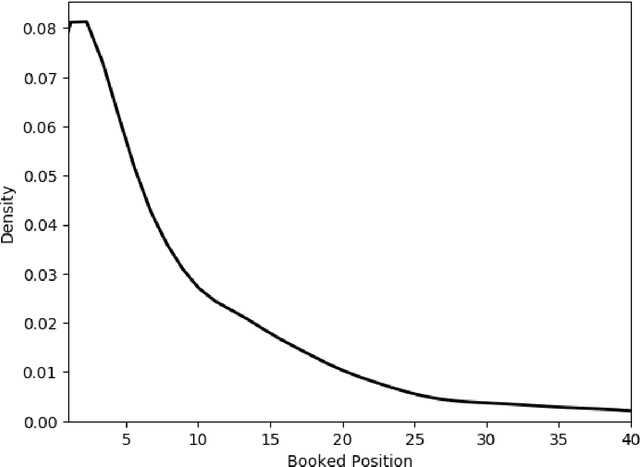

Correctly pricing products or services in an online marketplace presents a challenging problem and one of the critical factors for the success of the business. When users are looking to buy an item they typically search for it. Query relevance models are used at this stage to retrieve and rank the items on the search page from most relevant to least relevant. The presented items are naturally "competing" against each other for user purchases. We provide a practical two-stage model to price this set of retrieved items for which distributions of their values are learned. The initial output of the pricing strategy is a price vector for the top displayed items in one search event. We later aggregate these results over searches to provide the supplier with the optimal price for each item. We applied our solution to large-scale search data obtained from Airbnb Experiences marketplace. Offline evaluation results show that our strategy improves upon baseline pricing strategies on key metrics by at least +20% in terms of booking regret and +55% in terms of revenue potential.
Proceedings of the 2017 AdKDD & TargetAd Workshop
Jul 11, 2017Proceedings of the 2017 AdKDD and TargetAd Workshop held in conjunction with the 23rd ACM SIGKDD Conference on Knowledge Discovery and Data Mining Halifax, Nova Scotia, Canada.
Scalable Semantic Matching of Queries to Ads in Sponsored Search Advertising
Jul 07, 2016
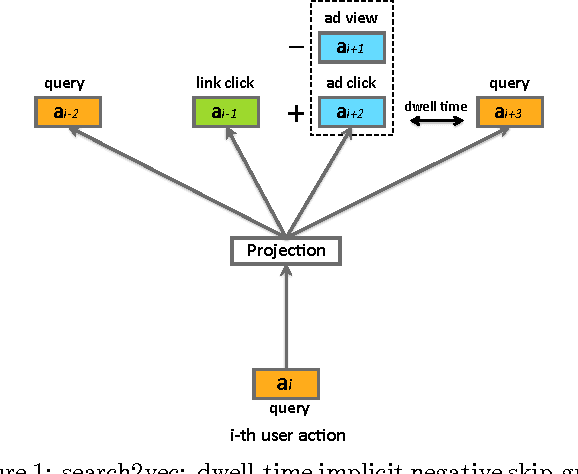

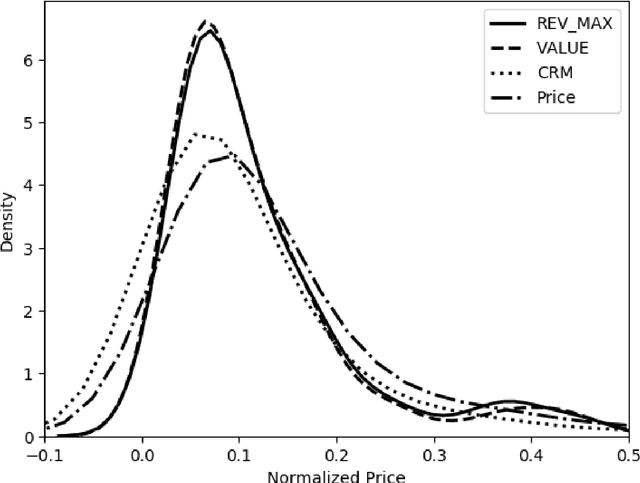
Sponsored search represents a major source of revenue for web search engines. This popular advertising model brings a unique possibility for advertisers to target users' immediate intent communicated through a search query, usually by displaying their ads alongside organic search results for queries deemed relevant to their products or services. However, due to a large number of unique queries it is challenging for advertisers to identify all such relevant queries. For this reason search engines often provide a service of advanced matching, which automatically finds additional relevant queries for advertisers to bid on. We present a novel advanced matching approach based on the idea of semantic embeddings of queries and ads. The embeddings were learned using a large data set of user search sessions, consisting of search queries, clicked ads and search links, while utilizing contextual information such as dwell time and skipped ads. To address the large-scale nature of our problem, both in terms of data and vocabulary size, we propose a novel distributed algorithm for training of the embeddings. Finally, we present an approach for overcoming a cold-start problem associated with new ads and queries. We report results of editorial evaluation and online tests on actual search traffic. The results show that our approach significantly outperforms baselines in terms of relevance, coverage, and incremental revenue. Lastly, we open-source learned query embeddings to be used by researchers in computational advertising and related fields.
* 10 pages, 4 figures, 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2016, Pisa, Italy
How Many Folders Do You Really Need?
Jun 29, 2016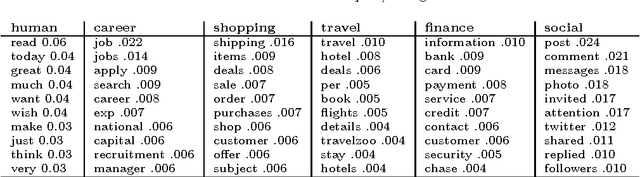
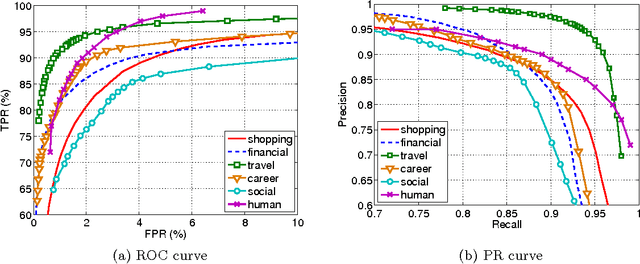
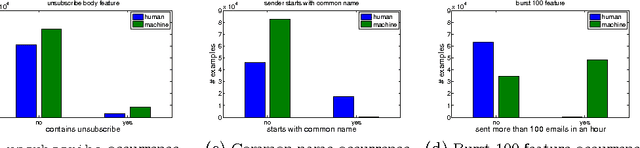

Email classification is still a mostly manual task. Consequently, most Web mail users never define a single folder. Recently however, automatic classification offering the same categories to all users has started to appear in some Web mail clients, such as AOL or Gmail. We adopt this approach, rather than previous (unsuccessful) personalized approaches because of the change in the nature of consumer email traffic, which is now dominated by (non-spam) machine-generated email. We propose here a novel approach for (1) automatically distinguishing between personal and machine-generated email and (2) classifying messages into latent categories, without requiring users to have defined any folder. We report how we have discovered that a set of 6 "latent" categories (one for human- and the others for machine-generated messages) can explain a significant portion of email traffic. We describe in details the steps involved in building a Web-scale email categorization system, from the collection of ground-truth labels, the selection of features to the training of models. Experimental evaluation was performed on more than 500 billion messages received during a period of six months by users of Yahoo mail service, who elected to be part of such research studies. Our system achieved precision and recall rates close to 90% and the latent categories we discovered were shown to cover 70% of both email traffic and email search queries. We believe that these results pave the way for a change of approach in the Web mail industry, and could support the invention of new large-scale email discovery paradigms that had not been possible before.
* 10 pages, 12 figures, Proceedings of the 23rd ACM International Conference on Information and Knowledge Management (CIKM 2014), Shanghai, China
Non-linear Label Ranking for Large-scale Prediction of Long-Term User Interests
Jun 29, 2016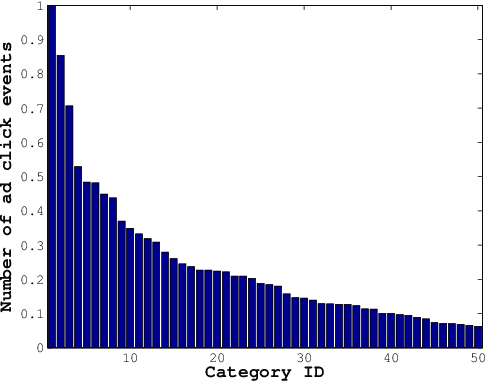
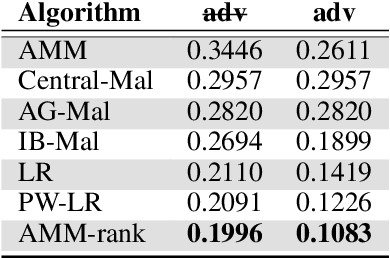

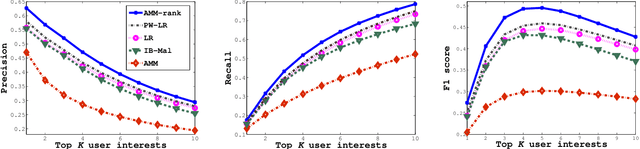
We consider the problem of personalization of online services from the viewpoint of ad targeting, where we seek to find the best ad categories to be shown to each user, resulting in improved user experience and increased advertisers' revenue. We propose to address this problem as a task of ranking the ad categories depending on a user's preference, and introduce a novel label ranking approach capable of efficiently learning non-linear, highly accurate models in large-scale settings. Experiments on a real-world advertising data set with more than 3.2 million users show that the proposed algorithm outperforms the existing solutions in terms of both rank loss and top-K retrieval performance, strongly suggesting the benefit of using the proposed model on large-scale ranking problems.
Hierarchical Neural Language Models for Joint Representation of Streaming Documents and their Content
Jun 28, 2016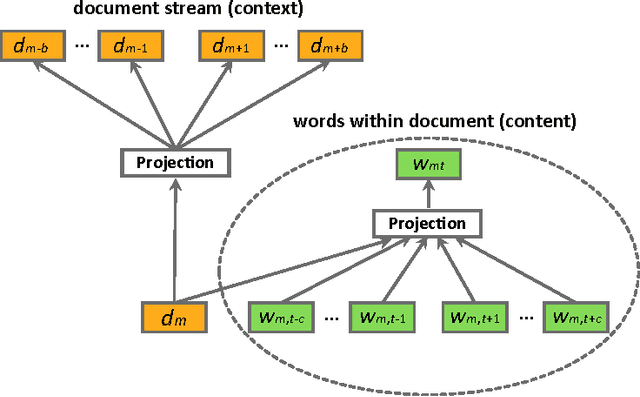

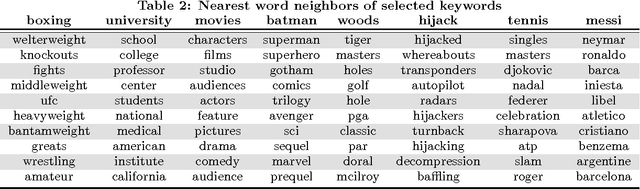
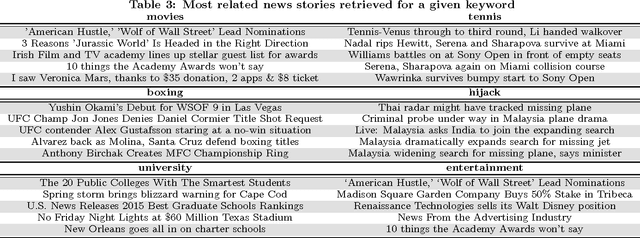
We consider the problem of learning distributed representations for documents in data streams. The documents are represented as low-dimensional vectors and are jointly learned with distributed vector representations of word tokens using a hierarchical framework with two embedded neural language models. In particular, we exploit the context of documents in streams and use one of the language models to model the document sequences, and the other to model word sequences within them. The models learn continuous vector representations for both word tokens and documents such that semantically similar documents and words are close in a common vector space. We discuss extensions to our model, which can be applied to personalized recommendation and social relationship mining by adding further user layers to the hierarchy, thus learning user-specific vectors to represent individual preferences. We validated the learned representations on a public movie rating data set from MovieLens, as well as on a large-scale Yahoo News data comprising three months of user activity logs collected on Yahoo servers. The results indicate that the proposed model can learn useful representations of both documents and word tokens, outperforming the current state-of-the-art by a large margin.
Network-Efficient Distributed Word2vec Training System for Large Vocabularies
Jun 27, 2016


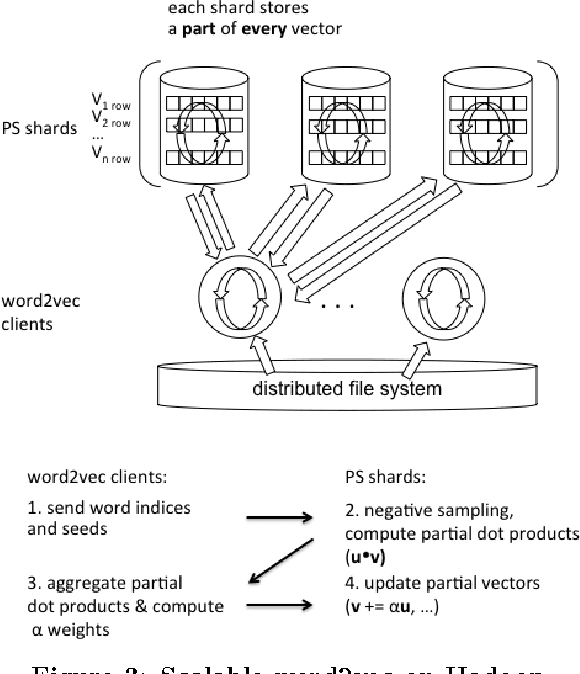
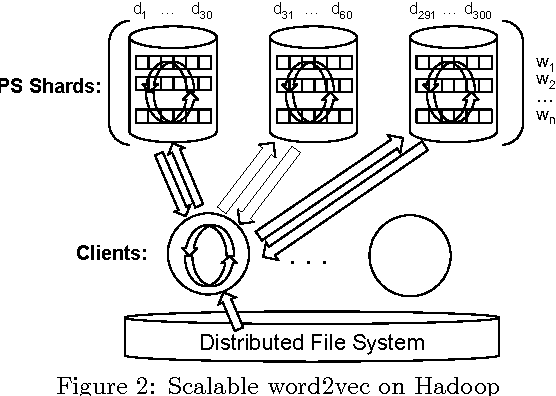
Word2vec is a popular family of algorithms for unsupervised training of dense vector representations of words on large text corpuses. The resulting vectors have been shown to capture semantic relationships among their corresponding words, and have shown promise in reducing a number of natural language processing (NLP) tasks to mathematical operations on these vectors. While heretofore applications of word2vec have centered around vocabularies with a few million words, wherein the vocabulary is the set of words for which vectors are simultaneously trained, novel applications are emerging in areas outside of NLP with vocabularies comprising several 100 million words. Existing word2vec training systems are impractical for training such large vocabularies as they either require that the vectors of all vocabulary words be stored in the memory of a single server or suffer unacceptable training latency due to massive network data transfer. In this paper, we present a novel distributed, parallel training system that enables unprecedented practical training of vectors for vocabularies with several 100 million words on a shared cluster of commodity servers, using far less network traffic than the existing solutions. We evaluate the proposed system on a benchmark dataset, showing that the quality of vectors does not degrade relative to non-distributed training. Finally, for several quarters, the system has been deployed for the purpose of matching queries to ads in Gemini, the sponsored search advertising platform at Yahoo, resulting in significant improvement of business metrics.
Gender and Interest Targeting for Sponsored Post Advertising at Tumblr
Jun 23, 2016

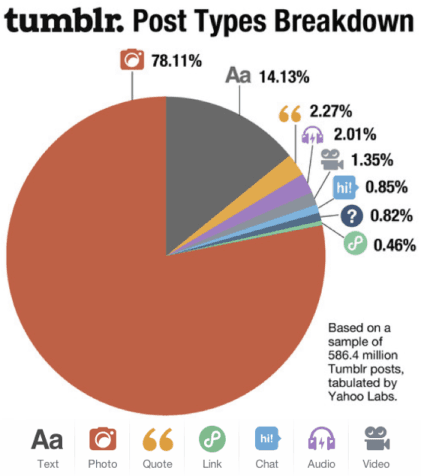

As one of the leading platforms for creative content, Tumblr offers advertisers a unique way of creating brand identity. Advertisers can tell their story through images, animation, text, music, video, and more, and promote that content by sponsoring it to appear as an advertisement in the streams of Tumblr users. In this paper we present a framework that enabled one of the key targeted advertising components for Tumblr, specifically gender and interest targeting. We describe the main challenges involved in development of the framework, which include creating the ground truth for training gender prediction models, as well as mapping Tumblr content to an interest taxonomy. For purposes of inferring user interests we propose a novel semi-supervised neural language model for categorization of Tumblr content (i.e., post tags and post keywords). The model was trained on a large-scale data set consisting of 6.8 billion user posts, with very limited amount of categorized keywords, and was shown to have superior performance over the bag-of-words model. We successfully deployed gender and interest targeting capability in Yahoo production systems, delivering inference for users that cover more than 90% of daily activities at Tumblr. Online performance results indicate advantages of the proposed approach, where we observed 20% lift in user engagement with sponsored posts as compared to untargeted campaigns.
* 10 pages, 9 figures, Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2015), Sydney, Australia
E-commerce in Your Inbox: Product Recommendations at Scale
Jun 23, 2016



In recent years online advertising has become increasingly ubiquitous and effective. Advertisements shown to visitors fund sites and apps that publish digital content, manage social networks, and operate e-mail services. Given such large variety of internet resources, determining an appropriate type of advertising for a given platform has become critical to financial success. Native advertisements, namely ads that are similar in look and feel to content, have had great success in news and social feeds. However, to date there has not been a winning formula for ads in e-mail clients. In this paper we describe a system that leverages user purchase history determined from e-mail receipts to deliver highly personalized product ads to Yahoo Mail users. We propose to use a novel neural language-based algorithm specifically tailored for delivering effective product recommendations, which was evaluated against baselines that included showing popular products and products predicted based on co-occurrence. We conducted rigorous offline testing using a large-scale product purchase data set, covering purchases of more than 29 million users from 172 e-commerce websites. Ads in the form of product recommendations were successfully tested on online traffic, where we observed a steady 9% lift in click-through rates over other ad formats in mail, as well as comparable lift in conversion rates. Following successful tests, the system was launched into production during the holiday season of 2014.
* 10 pages, 12 figures, Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2015), Sydney, Australia