 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecommending Themes for Ad Creative Design via Visual-Linguistic Representations
Feb 27, 2020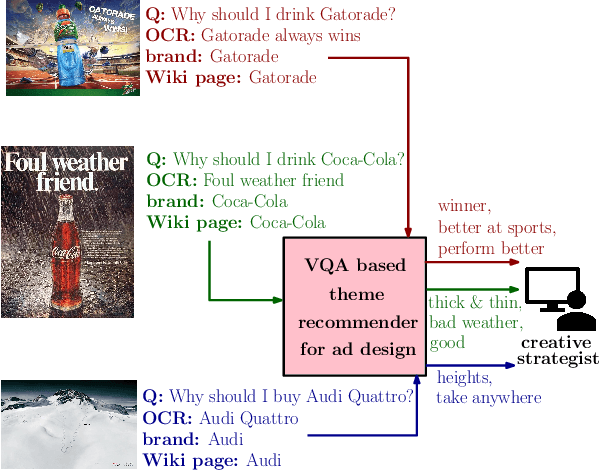
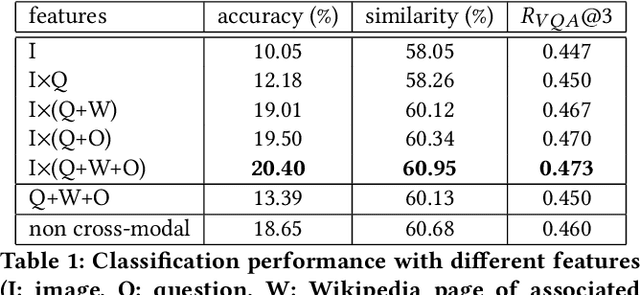
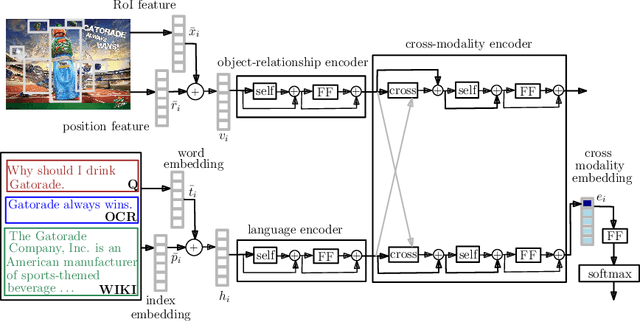
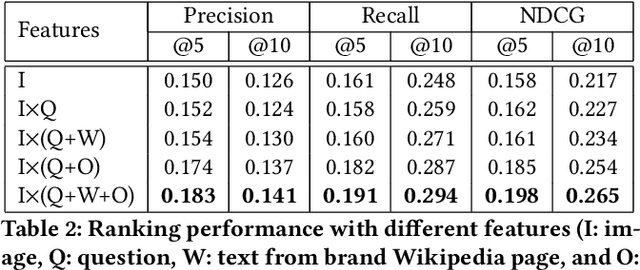
There is a perennial need in the online advertising industry to refresh ad creatives, i.e., images and text used for enticing online users towards a brand. Such refreshes are required to reduce the likelihood of ad fatigue among online users, and to incorporate insights from other successful campaigns in related product categories. Given a brand, to come up with themes for a new ad is a painstaking and time consuming process for creative strategists. Strategists typically draw inspiration from the images and text used for past ad campaigns, as well as world knowledge on the brands. To automatically infer ad themes via such multimodal sources of information in past ad campaigns, we propose a theme (keyphrase) recommender system for ad creative strategists. The theme recommender is based on aggregating results from a visual question answering (VQA) task, which ingests the following: (i) ad images, (ii) text associated with the ads as well as Wikipedia pages on the brands in the ads, and (iii) questions around the ad. We leverage transformer based cross-modality encoders to train visual-linguistic representations for our VQA task. We study two formulations for the VQA task along the lines of classification and ranking; via experiments on a public dataset, we show that cross-modal representations lead to significantly better classification accuracy and ranking precision-recall metrics. Cross-modal representations show better performance compared to separate image and text representations. In addition, the use of multimodal information shows a significant lift over using only textual or visual information.
Learning from Multi-User Activity Trails for B2B Ad Targeting
Aug 29, 2019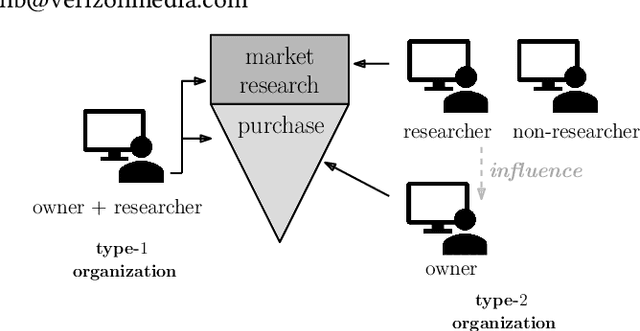
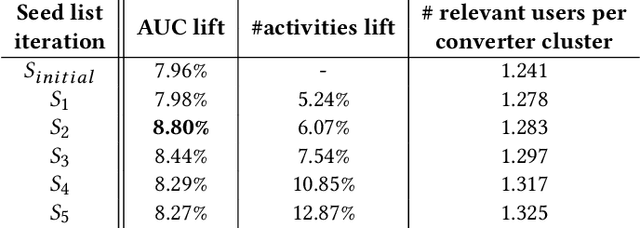
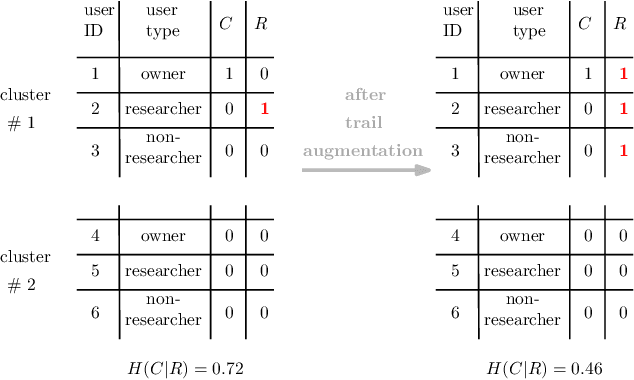
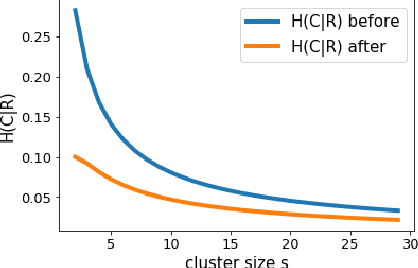
Online purchase decisions in organizations can go through a complex journey with multiple agents involved in the decision making process. Depending on the product being purchased, and the organizational structure, the process may involve employees who first conduct market research, and then influence decision makers who place the online purchase order. In such cases, the online activity trail of a single individual in the organization may only provide partial information for predicting purchases (conversions). To refine conversion prediction for business-to-business (B2B) products using online activity trails, we introduce the notion of relevant users in an organization with respect to a given B2B advertiser, and leverage the collective activity trails of such relevant users to predict conversions. In particular, our notion of relevant users is tied to a seed list of relevant activities for a B2B advertiser, and we propose a method using distributed activity representations to build such a seed list. Experiments using data from Yahoo Gemini demonstrate that the proposed methods can improve conversion prediction AUC by 8.8%, and provide an interpretable advertiser specific list of activities useful for B2B ad targeting.
Managing App Install Ad Campaigns in RTB: A Q-Learning Approach
Nov 11, 2018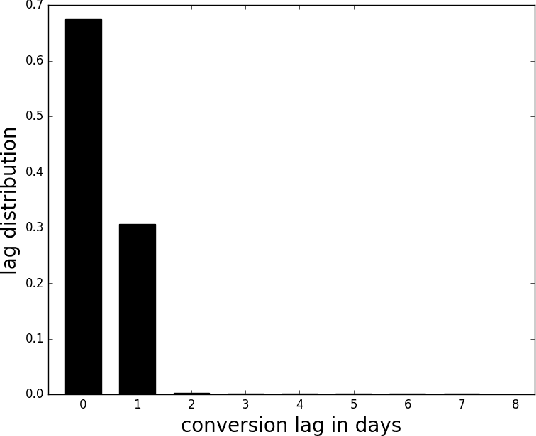
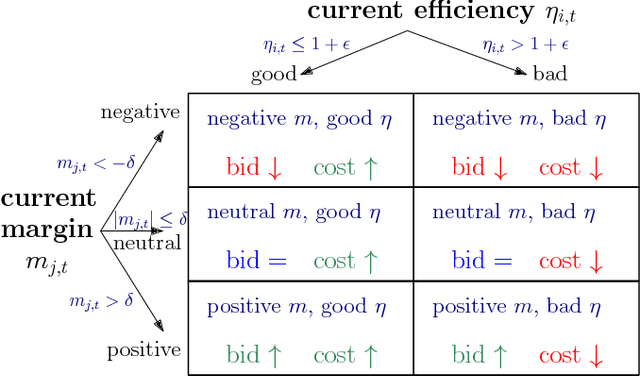
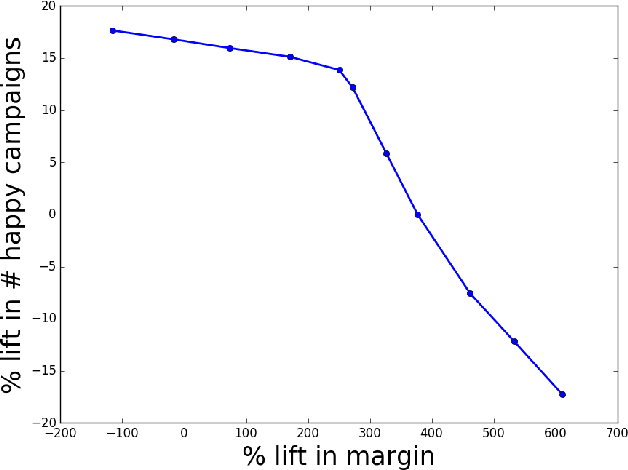

Real time bidding (RTB) enables demand side platforms (bidders) to scale ad campaigns across multiple publishers affiliated to an RTB ad exchange. While driving multiple campaigns for mobile app install ads via RTB, the bidder typically has to: (i) maintain each campaign's efficiency (i.e., meet advertiser's target cost-per-install), (ii) be sensitive to advertiser's budget, and (iii) make profit after payouts to the ad exchange. In this process, there is a sense of delayed rewards for the bidder's actions; the exchange charges the bidder right after the ad is shown, but the bidder gets to know about resultant installs after considerable delay. This makes it challenging for the bidder to decide beforehand the bid (and corresponding cost charged to advertiser) for each ad display opportunity. To jointly handle the objectives mentioned above, we propose a state space based policy which decides the exchange bid and advertiser cost for each opportunity. The state space captures the current efficiency, budget utilization and profit. The policy based on this state space is trained on past decisions and outcomes via a novel Q-learning algorithm which accounts for the delay in install notifications. In our experiments based on data from app install campaigns managed by Yahoo's Gemini advertising platform, the Q-learning based policy led to a significant increase in the profit and number of efficient campaigns.
Non-linear Label Ranking for Large-scale Prediction of Long-Term User Interests
Jun 29, 2016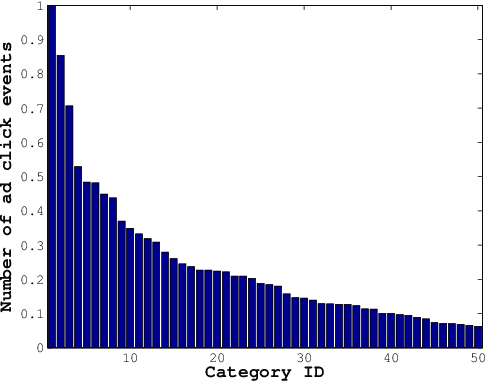
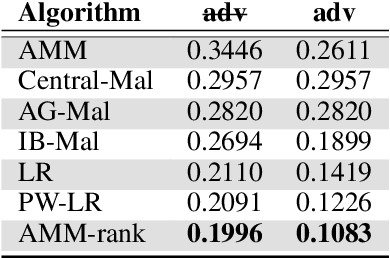

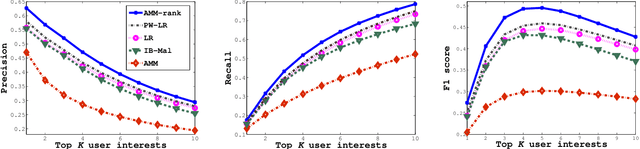
We consider the problem of personalization of online services from the viewpoint of ad targeting, where we seek to find the best ad categories to be shown to each user, resulting in improved user experience and increased advertisers' revenue. We propose to address this problem as a task of ranking the ad categories depending on a user's preference, and introduce a novel label ranking approach capable of efficiently learning non-linear, highly accurate models in large-scale settings. Experiments on a real-world advertising data set with more than 3.2 million users show that the proposed algorithm outperforms the existing solutions in terms of both rank loss and top-K retrieval performance, strongly suggesting the benefit of using the proposed model on large-scale ranking problems.
Hierarchical Neural Language Models for Joint Representation of Streaming Documents and their Content
Jun 28, 2016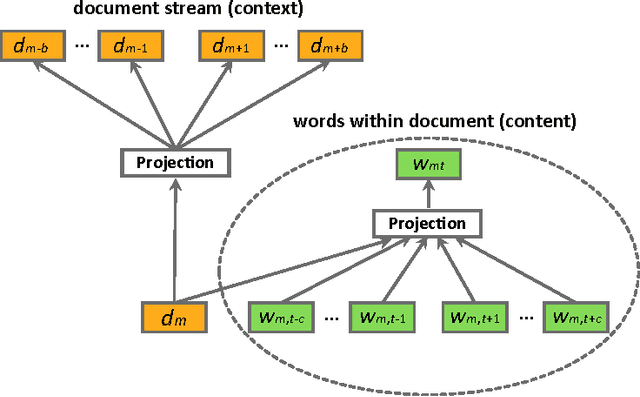

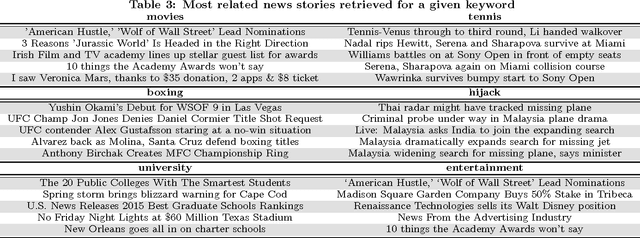
We consider the problem of learning distributed representations for documents in data streams. The documents are represented as low-dimensional vectors and are jointly learned with distributed vector representations of word tokens using a hierarchical framework with two embedded neural language models. In particular, we exploit the context of documents in streams and use one of the language models to model the document sequences, and the other to model word sequences within them. The models learn continuous vector representations for both word tokens and documents such that semantically similar documents and words are close in a common vector space. We discuss extensions to our model, which can be applied to personalized recommendation and social relationship mining by adding further user layers to the hierarchy, thus learning user-specific vectors to represent individual preferences. We validated the learned representations on a public movie rating data set from MovieLens, as well as on a large-scale Yahoo News data comprising three months of user activity logs collected on Yahoo servers. The results indicate that the proposed model can learn useful representations of both documents and word tokens, outperforming the current state-of-the-art by a large margin.
Gender and Interest Targeting for Sponsored Post Advertising at Tumblr
Jun 23, 2016

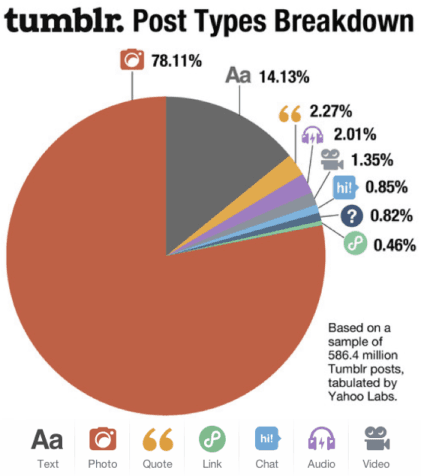

As one of the leading platforms for creative content, Tumblr offers advertisers a unique way of creating brand identity. Advertisers can tell their story through images, animation, text, music, video, and more, and promote that content by sponsoring it to appear as an advertisement in the streams of Tumblr users. In this paper we present a framework that enabled one of the key targeted advertising components for Tumblr, specifically gender and interest targeting. We describe the main challenges involved in development of the framework, which include creating the ground truth for training gender prediction models, as well as mapping Tumblr content to an interest taxonomy. For purposes of inferring user interests we propose a novel semi-supervised neural language model for categorization of Tumblr content (i.e., post tags and post keywords). The model was trained on a large-scale data set consisting of 6.8 billion user posts, with very limited amount of categorized keywords, and was shown to have superior performance over the bag-of-words model. We successfully deployed gender and interest targeting capability in Yahoo production systems, delivering inference for users that cover more than 90% of daily activities at Tumblr. Online performance results indicate advantages of the proposed approach, where we observed 20% lift in user engagement with sponsored posts as compared to untargeted campaigns.
* 10 pages, 9 figures, Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2015), Sydney, Australia
E-commerce in Your Inbox: Product Recommendations at Scale
Jun 23, 2016



In recent years online advertising has become increasingly ubiquitous and effective. Advertisements shown to visitors fund sites and apps that publish digital content, manage social networks, and operate e-mail services. Given such large variety of internet resources, determining an appropriate type of advertising for a given platform has become critical to financial success. Native advertisements, namely ads that are similar in look and feel to content, have had great success in news and social feeds. However, to date there has not been a winning formula for ads in e-mail clients. In this paper we describe a system that leverages user purchase history determined from e-mail receipts to deliver highly personalized product ads to Yahoo Mail users. We propose to use a novel neural language-based algorithm specifically tailored for delivering effective product recommendations, which was evaluated against baselines that included showing popular products and products predicted based on co-occurrence. We conducted rigorous offline testing using a large-scale product purchase data set, covering purchases of more than 29 million users from 172 e-commerce websites. Ads in the form of product recommendations were successfully tested on online traffic, where we observed a steady 9% lift in click-through rates over other ad formats in mail, as well as comparable lift in conversion rates. Following successful tests, the system was launched into production during the holiday season of 2014.
* 10 pages, 12 figures, Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2015), Sydney, Australia
Entity-Specific Sentiment Classification of Yahoo News Comments
Jun 11, 2015
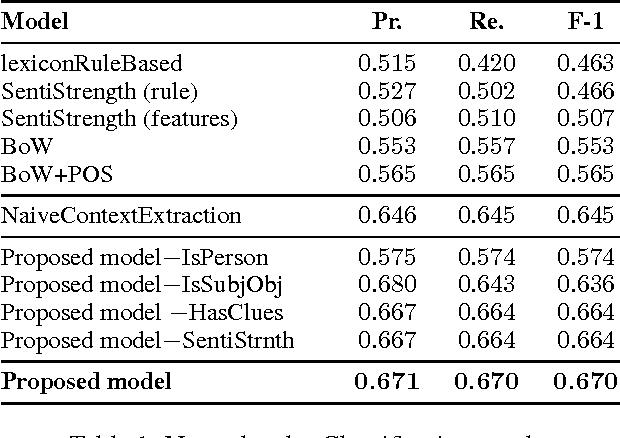
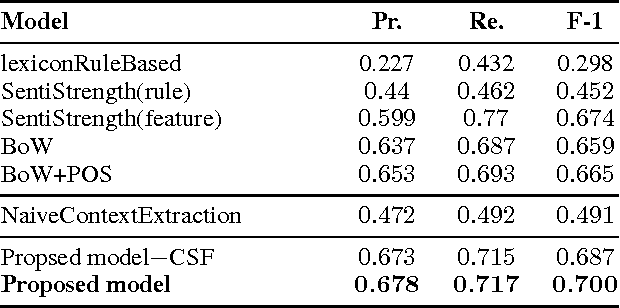
Sentiment classification is widely used for product reviews and in online social media such as forums, Twitter, and blogs. However, the problem of classifying the sentiment of user comments on news sites has not been addressed yet. News sites cover a wide range of domains including politics, sports, technology, and entertainment, in contrast to other online social sites such as forums and review sites, which are specific to a particular domain. A user associated with a news site is likely to post comments on diverse topics (e.g., politics, smartphones, and sports) or diverse entities (e.g., Obama, iPhone, or Google). Classifying the sentiment of users tied to various entities may help obtain a holistic view of their personality, which could be useful in applications such as online advertising, content personalization, and political campaign planning. In this paper, we formulate the problem of entity-specific sentiment classification of comments posted on news articles in Yahoo News and propose novel features that are specific to news comments. Experimental results show that our models outperform state-of-the-art baselines.