 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying Semantic ID-based Generative Retrieval for Large-Scale Podcast Discovery at Spotify
Mar 18, 2026Podcast listening is often grounded in a set of favorite shows, while listener intent can evolve over time. This combination of stable preferences and changing intent motivates recommendation approaches that support both familiarity and exploration. Traditional recommender systems typically emphasize long-term interaction patterns, and are less explicitly designed to incorporate rich contextual signals or flexible, intent-aware discovery objectives. In this setting, models that can jointly reason over semantics, context, and user state offer a promising direction. Large Language Models (LLMs) provide strong semantic reasoning and contextual conditioning for discovery-oriented recommendation, but deploying them in production introduces challenges in catalog grounding, user-level personalization, and latency-critical serving. We address these challenges with GLIDE, a production-scale generative recommender for podcast discovery at Spotify. GLIDE formulates recommendation as an instruction-following task over a discretized catalog using Semantic IDs, enabling grounded generation over a large inventory. The model conditions on recent listening history and lightweight user context, while injecting long-term user embeddings as soft prompts to capture stable preferences under strict inference constraints. We evaluate GLIDE using offline retrieval metrics, human judgments, and LLM-based evaluation, and validate its impact through large-scale online A/B testing. Across experiments involving millions of users, GLIDE increases non-habitual podcast streaming on Spotify home surface by up to 5.4% and new-show discovery by up to 14.3%, while meeting production cost and latency constraints.
A Unified Language Model for Large Scale Search, Recommendation, and Reasoning
Mar 18, 2026LLMs are increasingly applied to recommendation, retrieval, and reasoning, yet deploying a single end-to-end model that can jointly support these behaviors over large, heterogeneous catalogs remains challenging. Such systems must generate unambiguous references to real items, handle multiple entity types, and operate under strict latency and reliability constraints requirements that are difficult to satisfy with text-only generation. While tool-augmented recommender systems address parts of this problem, they introduce orchestration complexity and limit end-to-end optimization. We view this setting as an instance of a broader research problem: how to adapt LLMs to reason jointly over multiple-domain entities, users, and language in a fully self-contained manner. To this end, we introduce NEO, a framework that adapts a pre-trained decoder-only LLM into a tool-free, catalog-grounded generator. NEO represents items as SIDs and trains a single model to interleave natural language and typed item identifiers within a shared sequence. Text prompts control the task, target entity type, and output format (IDs, text, or mixed), while constrained decoding guarantees catalog-valid item generation without restricting free-form text. We refer to this instruction-conditioned controllability as language-steerability. We treat SIDs as a distinct modality and study design choices for integrating discrete entity representations into LLMs via staged alignment and instruction tuning. We evaluate NEO at scale on a real-world catalog of over 10M items across multiple media types and discovery tasks, including recommendation, search, and user understanding. In offline experiments, NEO consistently outperforms strong task-specific baselines and exhibits cross-task transfer, demonstrating a practical path toward consolidating large-scale discovery capabilities into a single language-steerable generative model.
Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
Mar 08, 2024In the ever-evolving digital audio landscape, Spotify, well-known for its music and talk content, has recently introduced audiobooks to its vast user base. While promising, this move presents significant challenges for personalized recommendations. Unlike music and podcasts, audiobooks, initially available for a fee, cannot be easily skimmed before purchase, posing higher stakes for the relevance of recommendations. Furthermore, introducing a new content type into an existing platform confronts extreme data sparsity, as most users are unfamiliar with this new content type. Lastly, recommending content to millions of users requires the model to react fast and be scalable. To address these challenges, we leverage podcast and music user preferences and introduce 2T-HGNN, a scalable recommendation system comprising Heterogeneous Graph Neural Networks (HGNNs) and a Two Tower (2T) model. This novel approach uncovers nuanced item relationships while ensuring low latency and complexity. We decouple users from the HGNN graph and propose an innovative multi-link neighbor sampler. These choices, together with the 2T component, significantly reduce the complexity of the HGNN model. Empirical evaluations involving millions of users show significant improvement in the quality of personalized recommendations, resulting in a +46% increase in new audiobooks start rate and a +23% boost in streaming rates. Intriguingly, our model's impact extends beyond audiobooks, benefiting established products like podcasts.
Multi-Modal Trajectory Prediction of NBA Players
Aug 18, 2020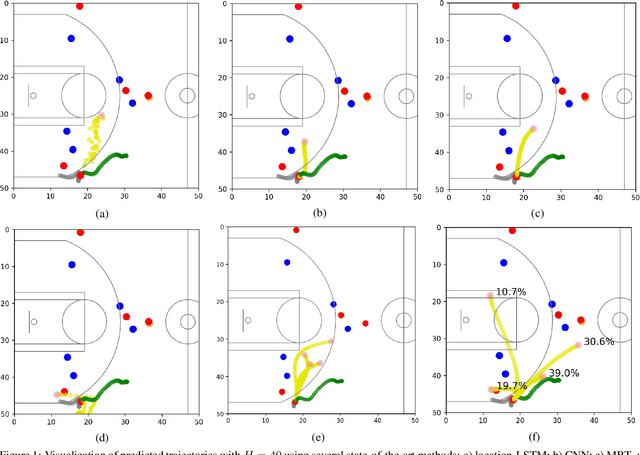
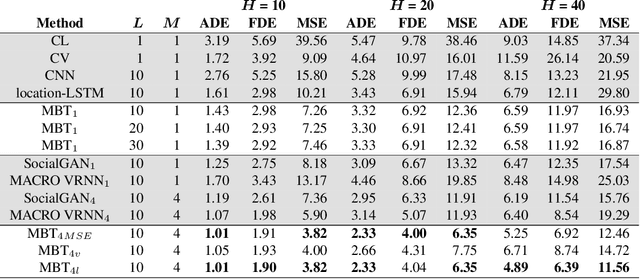
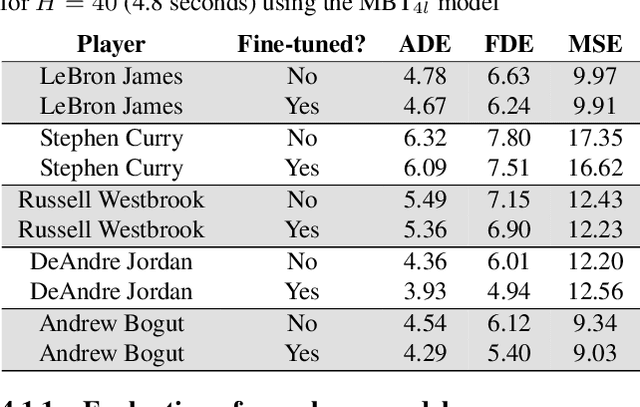
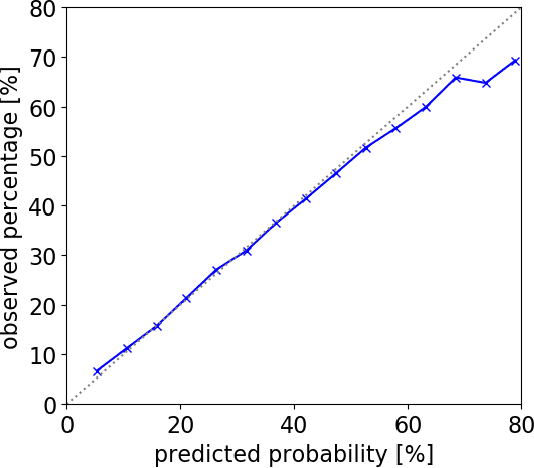
National Basketball Association (NBA) players are highly motivated and skilled experts that solve complex decision making problems at every time point during a game. As a step towards understanding how players make their decisions, we focus on their movement trajectories during games. We propose a method that captures the multi-modal behavior of players, where they might consider multiple trajectories and select the most advantageous one. The method is built on an LSTM-based architecture predicting multiple trajectories and their probabilities, trained by a multi-modal loss function that updates the best trajectories. Experiments on large, fine-grained NBA tracking data show that the proposed method outperforms the state-of-the-art. In addition, the results indicate that the approach generates more realistic trajectories and that it can learn individual playing styles of specific players.
Predicting Motion of Vulnerable Road Users using High-Definition Maps and Efficient ConvNets
Jun 20, 2019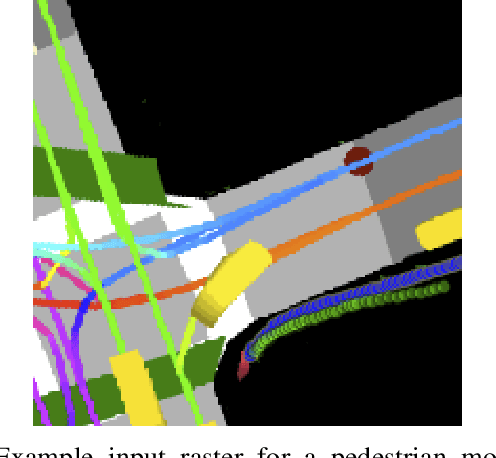
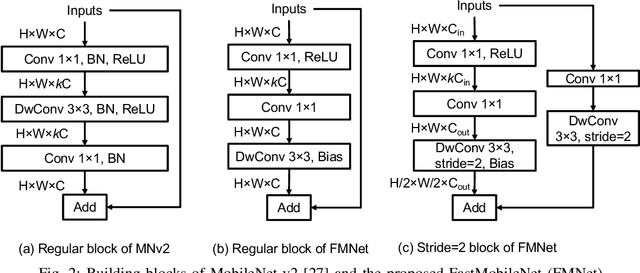
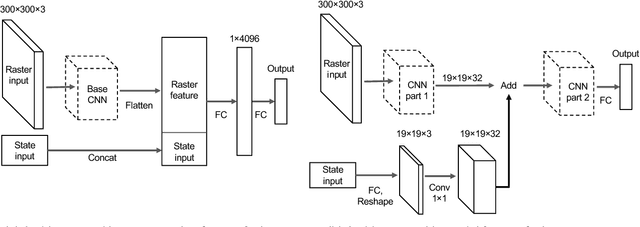
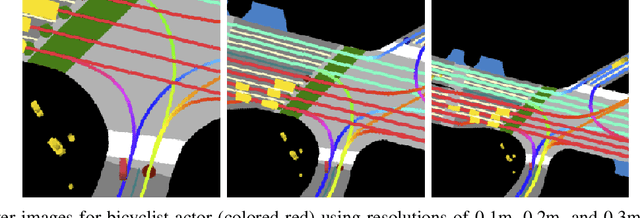
Following detection and tracking of traffic actors, prediction of their future motion is the next critical component of a self-driving vehicle (SDV) technology, allowing the SDV to operate safely and efficiently in its environment. This is particularly important when it comes to vulnerable road users (VRUs), such as pedestrians and bicyclists. These actors need to be handled with special care due to an increased risk of injury, as well as the fact that their behavior is less predictable than that of motorized actors. To address this issue, in this paper we present a deep learning-based method for predicting VRU movement, where we rasterize high-definition maps and actor's surroundings into bird's-eye view image used as an input to deep convolutional networks. In addition, we propose a fast architecture suitable for real-time inference, and present a detailed ablation study of various rasterization choices. The results strongly indicate benefits of using the proposed approach for motion prediction of VRUs, both in terms of accuracy and latency.
Multimodal Trajectory Predictions for Autonomous Driving using Deep Convolutional Networks
Mar 01, 2019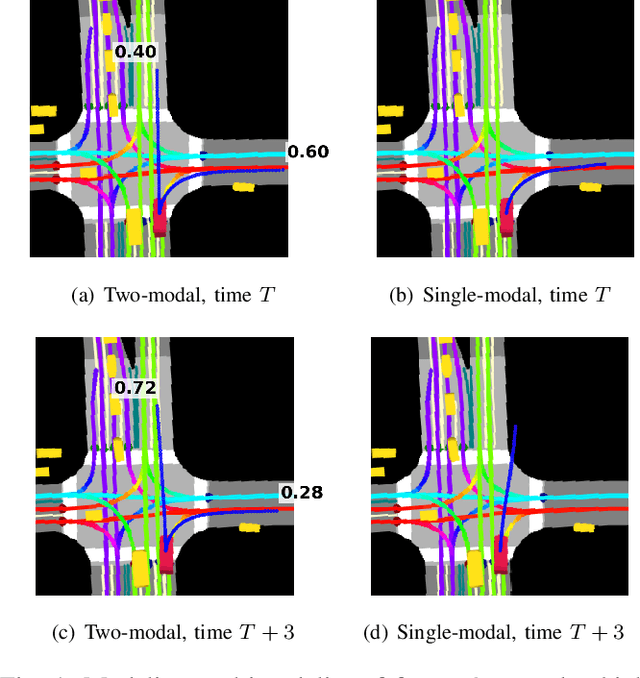
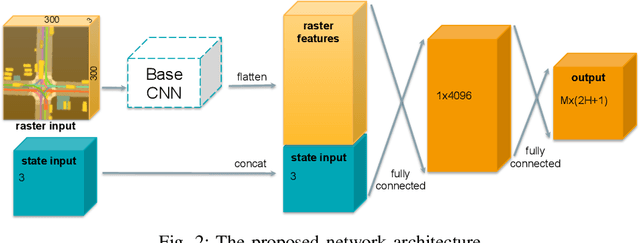
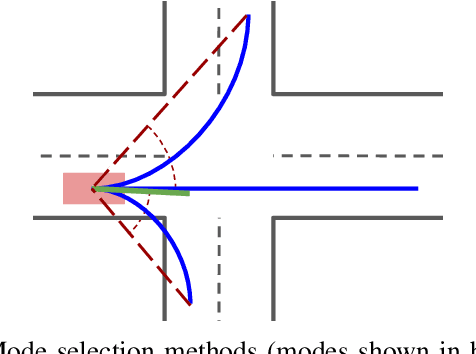
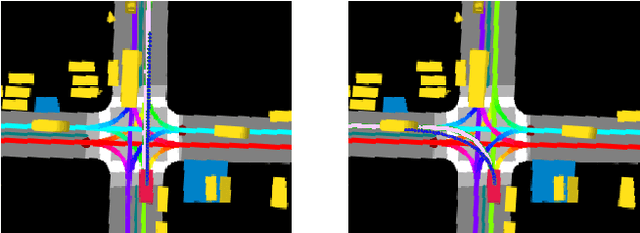
Autonomous driving presents one of the largest problems that the robotics and artificial intelligence communities are facing at the moment, both in terms of difficulty and potential societal impact. Self-driving vehicles (SDVs) are expected to prevent road accidents and save millions of lives while improving the livelihood and life quality of many more. However, despite large interest and a number of industry players working in the autonomous domain, there still remains more to be done in order to develop a system capable of operating at a level comparable to best human drivers. One reason for this is high uncertainty of traffic behavior and large number of situations that an SDV may encounter on the roads, making it very difficult to create a fully generalizable system. To ensure safe and efficient operations, an autonomous vehicle is required to account for this uncertainty and to anticipate a multitude of possible behaviors of traffic actors in its surrounding. We address this critical problem and present a method to predict multiple possible trajectories of actors while also estimating their probabilities. The method encodes each actor's surrounding context into a raster image, used as input by deep convolutional networks to automatically derive relevant features for the task. Following extensive offline evaluation and comparison to state-of-the-art baselines, the method was successfully tested on SDVs in closed-course tests.
Short-term Motion Prediction of Traffic Actors for Autonomous Driving using Deep Convolutional Networks
Sep 16, 2018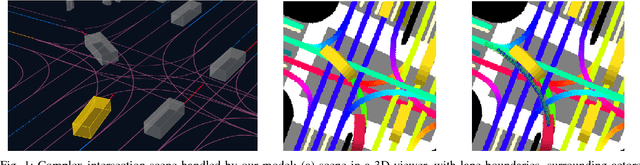
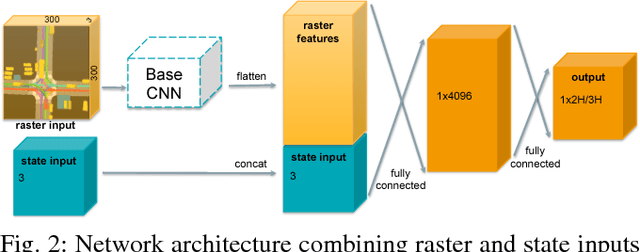
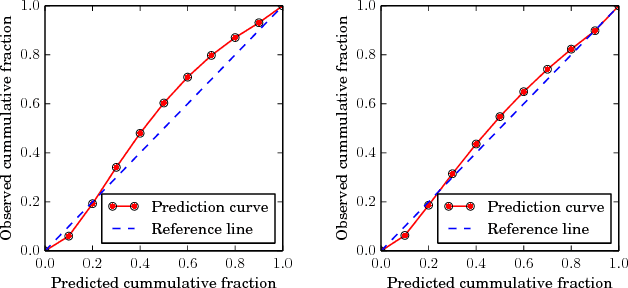
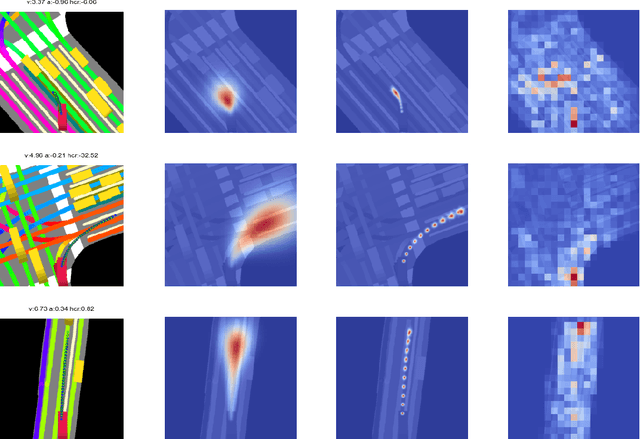
Despite its ubiquity in our daily lives, AI is only just starting to make advances in what may arguably have the largest societal impact thus far, the nascent field of autonomous driving. In this work we discuss this important topic and address one of crucial aspects of the emerging area, the problem of predicting future state of autonomous vehicle's surrounding necessary for safe and efficient operations. We introduce a deep learning-based approach that takes into account current world state and produces rasterized representations of each actor's vicinity. The raster images are then used by deep convolutional models to infer future movement of actors while accounting for inherent uncertainty of the prediction task. Extensive experiments on real-world data strongly suggest benefits of the proposed approach. Moreover, following successful tests the system was deployed to a fleet of autonomous vehicles.
Proceedings of the 2017 AdKDD & TargetAd Workshop
Jul 11, 2017Proceedings of the 2017 AdKDD and TargetAd Workshop held in conjunction with the 23rd ACM SIGKDD Conference on Knowledge Discovery and Data Mining Halifax, Nova Scotia, Canada.
Scalable Semantic Matching of Queries to Ads in Sponsored Search Advertising
Jul 07, 2016
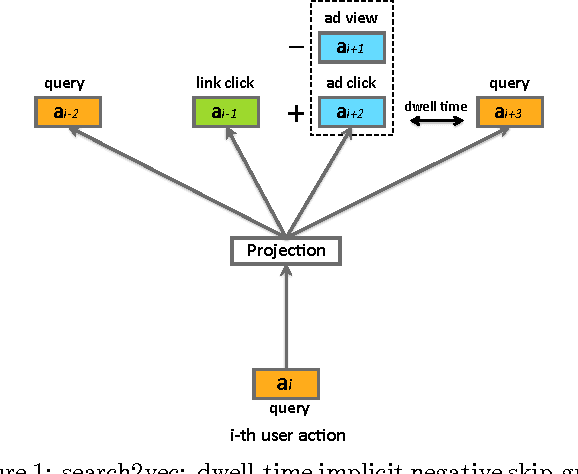
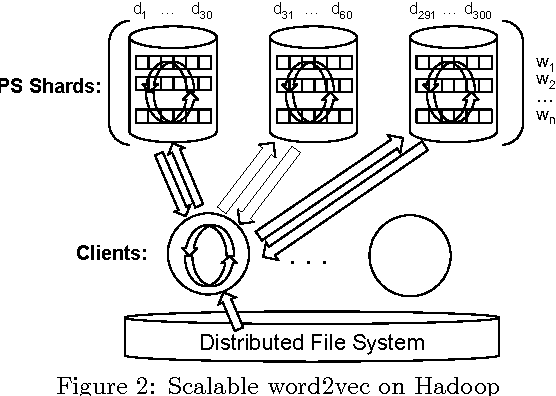

Sponsored search represents a major source of revenue for web search engines. This popular advertising model brings a unique possibility for advertisers to target users' immediate intent communicated through a search query, usually by displaying their ads alongside organic search results for queries deemed relevant to their products or services. However, due to a large number of unique queries it is challenging for advertisers to identify all such relevant queries. For this reason search engines often provide a service of advanced matching, which automatically finds additional relevant queries for advertisers to bid on. We present a novel advanced matching approach based on the idea of semantic embeddings of queries and ads. The embeddings were learned using a large data set of user search sessions, consisting of search queries, clicked ads and search links, while utilizing contextual information such as dwell time and skipped ads. To address the large-scale nature of our problem, both in terms of data and vocabulary size, we propose a novel distributed algorithm for training of the embeddings. Finally, we present an approach for overcoming a cold-start problem associated with new ads and queries. We report results of editorial evaluation and online tests on actual search traffic. The results show that our approach significantly outperforms baselines in terms of relevance, coverage, and incremental revenue. Lastly, we open-source learned query embeddings to be used by researchers in computational advertising and related fields.
* 10 pages, 4 figures, 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2016, Pisa, Italy
Non-linear Label Ranking for Large-scale Prediction of Long-Term User Interests
Jun 29, 2016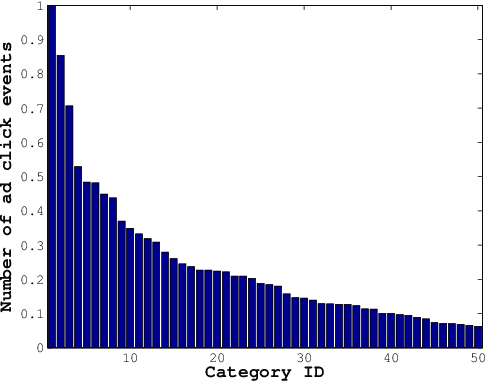
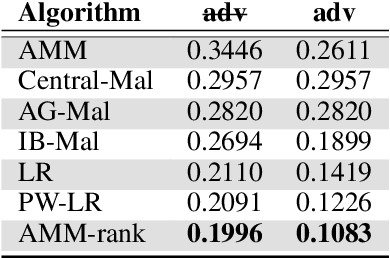

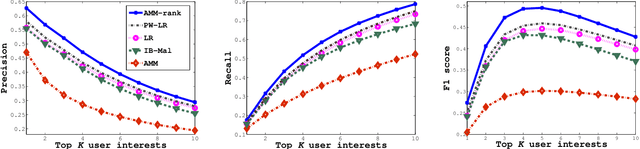
We consider the problem of personalization of online services from the viewpoint of ad targeting, where we seek to find the best ad categories to be shown to each user, resulting in improved user experience and increased advertisers' revenue. We propose to address this problem as a task of ranking the ad categories depending on a user's preference, and introduce a novel label ranking approach capable of efficiently learning non-linear, highly accurate models in large-scale settings. Experiments on a real-world advertising data set with more than 3.2 million users show that the proposed algorithm outperforms the existing solutions in terms of both rank loss and top-K retrieval performance, strongly suggesting the benefit of using the proposed model on large-scale ranking problems.