 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Semantic Matching of Queries to Ads in Sponsored Search Advertising
Jul 07, 2016
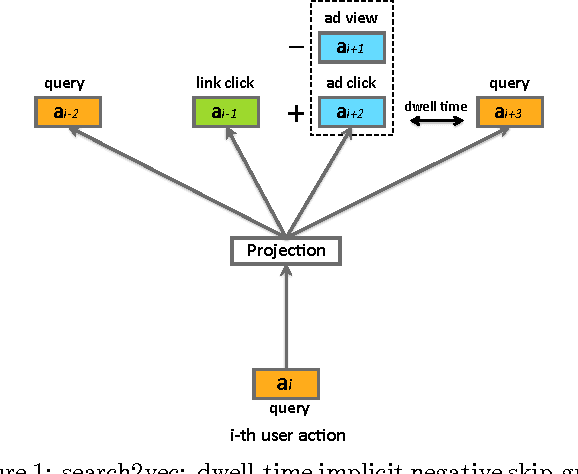

Sponsored search represents a major source of revenue for web search engines. This popular advertising model brings a unique possibility for advertisers to target users' immediate intent communicated through a search query, usually by displaying their ads alongside organic search results for queries deemed relevant to their products or services. However, due to a large number of unique queries it is challenging for advertisers to identify all such relevant queries. For this reason search engines often provide a service of advanced matching, which automatically finds additional relevant queries for advertisers to bid on. We present a novel advanced matching approach based on the idea of semantic embeddings of queries and ads. The embeddings were learned using a large data set of user search sessions, consisting of search queries, clicked ads and search links, while utilizing contextual information such as dwell time and skipped ads. To address the large-scale nature of our problem, both in terms of data and vocabulary size, we propose a novel distributed algorithm for training of the embeddings. Finally, we present an approach for overcoming a cold-start problem associated with new ads and queries. We report results of editorial evaluation and online tests on actual search traffic. The results show that our approach significantly outperforms baselines in terms of relevance, coverage, and incremental revenue. Lastly, we open-source learned query embeddings to be used by researchers in computational advertising and related fields.
* 10 pages, 4 figures, 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2016, Pisa, Italy
Network-Efficient Distributed Word2vec Training System for Large Vocabularies
Jun 27, 2016


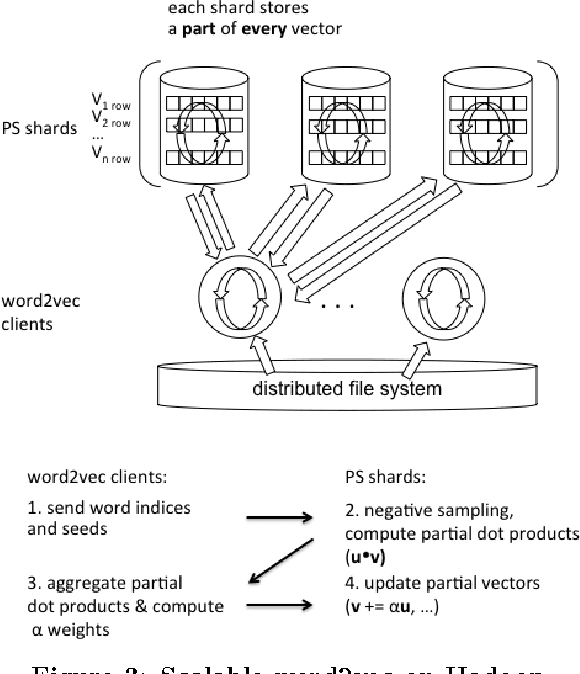
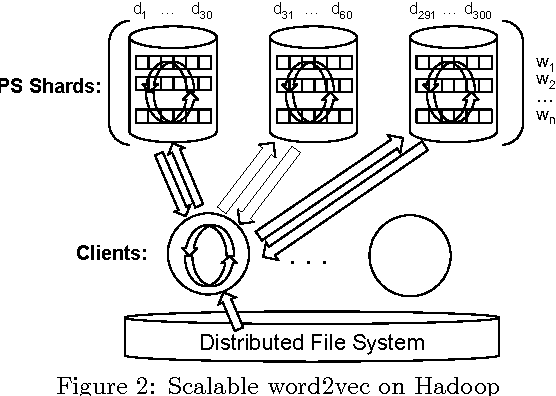
Word2vec is a popular family of algorithms for unsupervised training of dense vector representations of words on large text corpuses. The resulting vectors have been shown to capture semantic relationships among their corresponding words, and have shown promise in reducing a number of natural language processing (NLP) tasks to mathematical operations on these vectors. While heretofore applications of word2vec have centered around vocabularies with a few million words, wherein the vocabulary is the set of words for which vectors are simultaneously trained, novel applications are emerging in areas outside of NLP with vocabularies comprising several 100 million words. Existing word2vec training systems are impractical for training such large vocabularies as they either require that the vectors of all vocabulary words be stored in the memory of a single server or suffer unacceptable training latency due to massive network data transfer. In this paper, we present a novel distributed, parallel training system that enables unprecedented practical training of vectors for vocabularies with several 100 million words on a shared cluster of commodity servers, using far less network traffic than the existing solutions. We evaluate the proposed system on a benchmark dataset, showing that the quality of vectors does not degrade relative to non-distributed training. Finally, for several quarters, the system has been deployed for the purpose of matching queries to ads in Gemini, the sponsored search advertising platform at Yahoo, resulting in significant improvement of business metrics.