 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Conformal Inference by Betting
Dec 26, 2024



Conformal prediction is a valuable tool for quantifying predictive uncertainty of machine learning models. However, its applicability relies on the assumption of data exchangeability, a condition which is often not met in real-world scenarios. In this paper, we consider the problem of adaptive conformal inference without any assumptions about the data generating process. Existing approaches for adaptive conformal inference are based on optimizing the pinball loss using variants of online gradient descent. A notable shortcoming of such approaches is in their explicit dependence on and sensitivity to the choice of the learning rates. In this paper, we propose a different approach for adaptive conformal inference that leverages parameter-free online convex optimization techniques. We prove that our method controls long-term miscoverage frequency at a nominal level and demonstrate its convincing empirical performance without any need of performing cumbersome parameter tuning.
Impression Allocation and Policy Search in Display Advertising
Mar 11, 2022
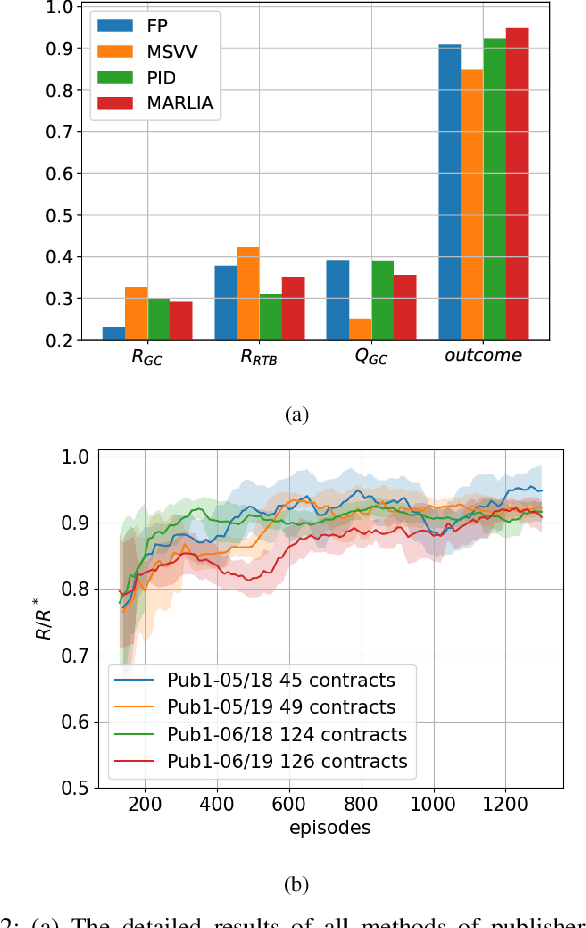
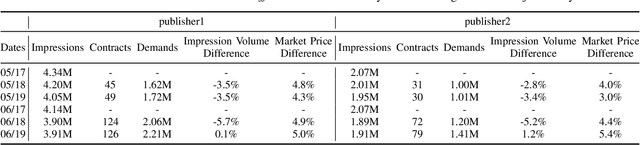
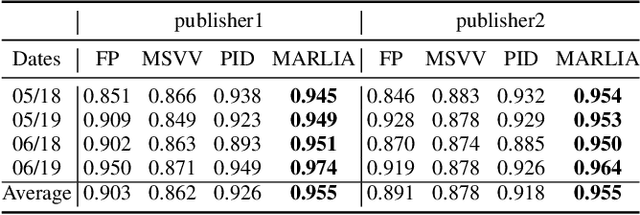
In online display advertising, guaranteed contracts and real-time bidding (RTB) are two major ways to sell impressions for a publisher. For large publishers, simultaneously selling impressions through both guaranteed contracts and in-house RTB has become a popular choice. Generally speaking, a publisher needs to derive an impression allocation strategy between guaranteed contracts and RTB to maximize its overall outcome (e.g., revenue and/or impression quality). However, deriving the optimal strategy is not a trivial task, e.g., the strategy should encourage incentive compatibility in RTB and tackle common challenges in real-world applications such as unstable traffic patterns (e.g., impression volume and bid landscape changing). In this paper, we formulate impression allocation as an auction problem where each guaranteed contract submits virtual bids for individual impressions. With this formulation, we derive the optimal bidding functions for the guaranteed contracts, which result in the optimal impression allocation. In order to address the unstable traffic pattern challenge and achieve the optimal overall outcome, we propose a multi-agent reinforcement learning method to adjust the bids from each guaranteed contract, which is simple, converging efficiently and scalable. The experiments conducted on real-world datasets demonstrate the effectiveness of our method.
Binary Code based Hash Embedding for Web-scale Applications
Aug 24, 2021

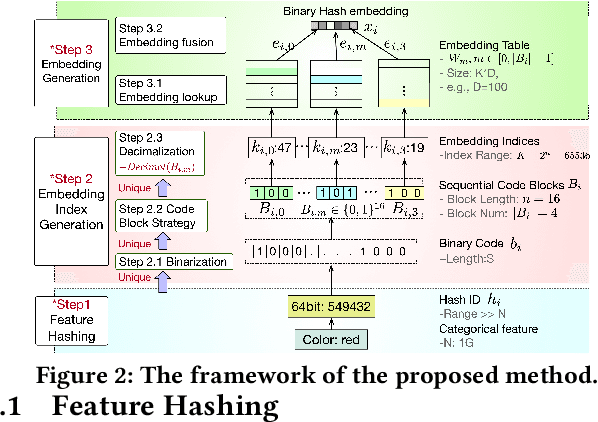

Nowadays, deep learning models are widely adopted in web-scale applications such as recommender systems, and online advertising. In these applications, embedding learning of categorical features is crucial to the success of deep learning models. In these models, a standard method is that each categorical feature value is assigned a unique embedding vector which can be learned and optimized. Although this method can well capture the characteristics of the categorical features and promise good performance, it can incur a huge memory cost to store the embedding table, especially for those web-scale applications. Such a huge memory cost significantly holds back the effectiveness and usability of EDRMs. In this paper, we propose a binary code based hash embedding method which allows the size of the embedding table to be reduced in arbitrary scale without compromising too much performance. Experimental evaluation results show that one can still achieve 99\% performance even if the embedding table size is reduced 1000$\times$ smaller than the original one with our proposed method.
Learning Effective and Efficient Embedding via an Adaptively-Masked Twins-based Layer
Aug 24, 2021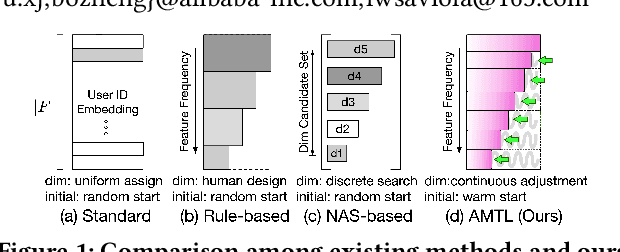
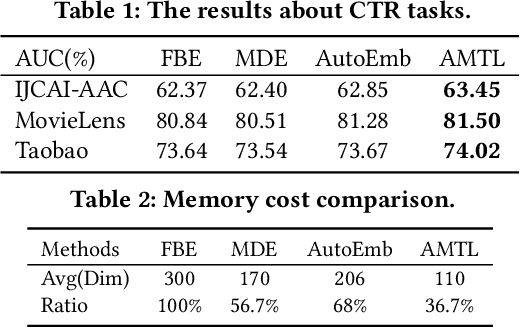

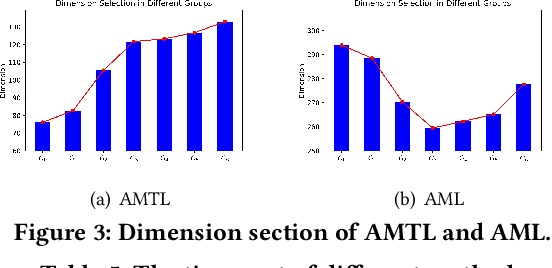
Embedding learning for categorical features is crucial for the deep learning-based recommendation models (DLRMs). Each feature value is mapped to an embedding vector via an embedding learning process. Conventional methods configure a fixed and uniform embedding size to all feature values from the same feature field. However, such a configuration is not only sub-optimal for embedding learning but also memory costly. Existing methods that attempt to resolve these problems, either rule-based or neural architecture search (NAS)-based, need extensive efforts on the human design or network training. They are also not flexible in embedding size selection or in warm-start-based applications. In this paper, we propose a novel and effective embedding size selection scheme. Specifically, we design an Adaptively-Masked Twins-based Layer (AMTL) behind the standard embedding layer. AMTL generates a mask vector to mask the undesired dimensions for each embedding vector. The mask vector brings flexibility in selecting the dimensions and the proposed layer can be easily added to either untrained or trained DLRMs. Extensive experimental evaluations show that the proposed scheme outperforms competitive baselines on all the benchmark tasks, and is also memory-efficient, saving 60\% memory usage without compromising any performance metrics.
Towards a Better Tradeoff between Effectiveness and Efficiency in Pre-Ranking: A Learnable Feature Selection based Approach
May 17, 2021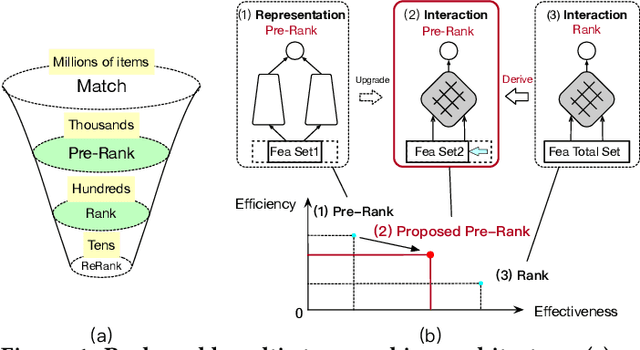



In real-world search, recommendation, and advertising systems, the multi-stage ranking architecture is commonly adopted. Such architecture usually consists of matching, pre-ranking, ranking, and re-ranking stages. In the pre-ranking stage, vector-product based models with representation-focused architecture are commonly adopted to account for system efficiency. However, it brings a significant loss to the effectiveness of the system. In this paper, a novel pre-ranking approach is proposed which supports complicated models with interaction-focused architecture. It achieves a better tradeoff between effectiveness and efficiency by utilizing the proposed learnable Feature Selection method based on feature Complexity and variational Dropout (FSCD). Evaluations in a real-world e-commerce sponsored search system for a search engine demonstrate that utilizing the proposed pre-ranking, the effectiveness of the system is significantly improved. Moreover, compared to the systems with conventional pre-ranking models, an identical amount of computational resource is consumed.
Large scale classification in deep neural network with Label Mapping
Jun 07, 2018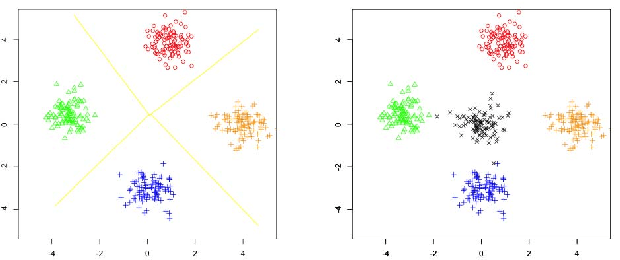
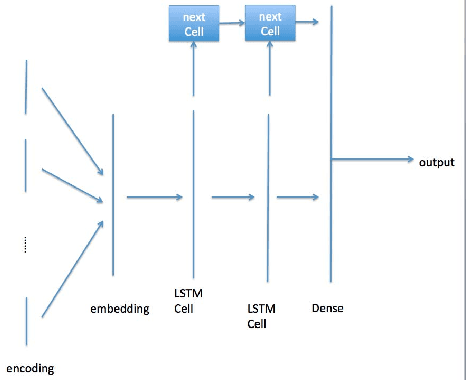
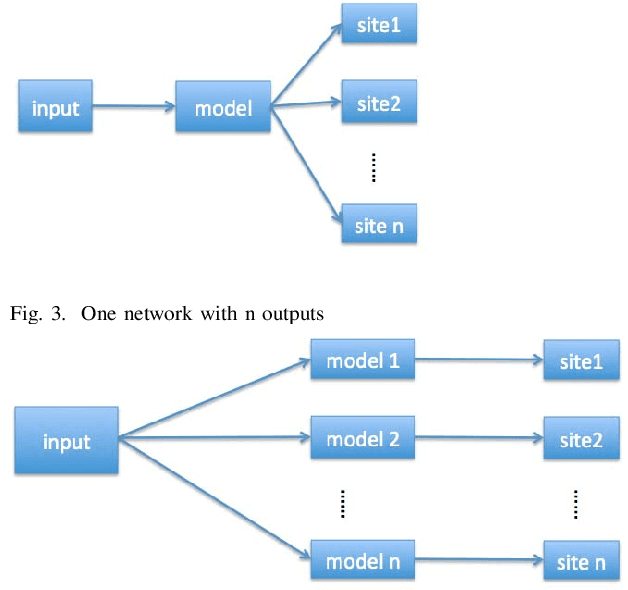
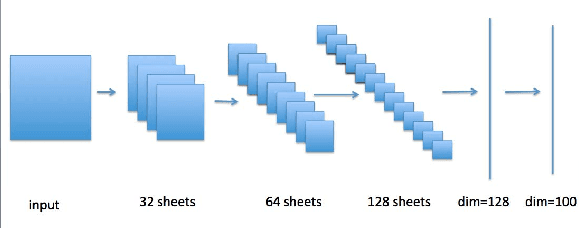
In recent years, deep neural network is widely used in machine learning. The multi-class classification problem is a class of important problem in machine learning. However, in order to solve those types of multi-class classification problems effectively, the required network size should have hyper-linear growth with respect to the number of classes. Therefore, it is infeasible to solve the multi-class classification problem using deep neural network when the number of classes are huge. This paper presents a method, so called Label Mapping (LM), to solve this problem by decomposing the original classification problem to several smaller sub-problems which are solvable theoretically. Our method is an ensemble method like error-correcting output codes (ECOC), but it allows base learners to be multi-class classifiers with different number of class labels. We propose two design principles for LM, one is to maximize the number of base classifier which can separate two different classes, and the other is to keep all base learners to be independent as possible in order to reduce the redundant information. Based on these principles, two different LM algorithms are derived using number theory and information theory. Since each base learner can be trained independently, it is easy to scale our method into a large scale training system. Experiments show that our proposed method outperforms the standard one-hot encoding and ECOC significantly in terms of accuracy and model complexity.
Proceedings of the 2017 AdKDD & TargetAd Workshop
Jul 11, 2017Proceedings of the 2017 AdKDD and TargetAd Workshop held in conjunction with the 23rd ACM SIGKDD Conference on Knowledge Discovery and Data Mining Halifax, Nova Scotia, Canada.
User Clustering in Online Advertising via Topic Models
Feb 24, 2015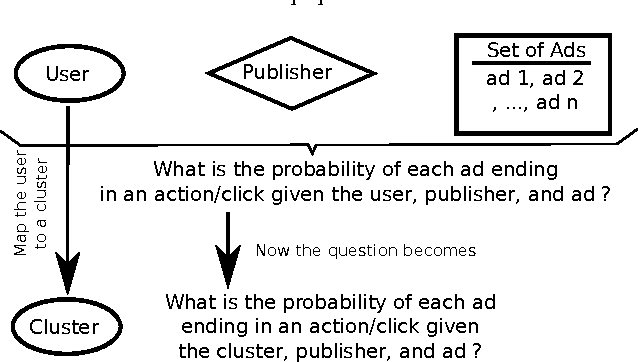
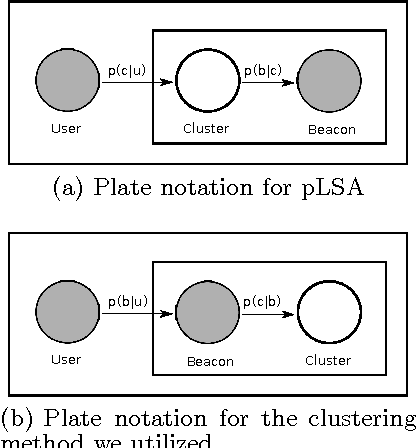


In the domain of online advertising, our aim is to serve the best ad to a user who visits a certain webpage, to maximize the chance of a desired action to be performed by this user after seeing the ad. While it is possible to generate a different prediction model for each user to tell if he/she will act on a given ad, the prediction result typically will be quite unreliable with huge variance, since the desired actions are extremely sparse, and the set of users is huge (hundreds of millions) and extremely volatile, i.e., a lot of new users are introduced everyday, or are no longer valid. In this paper we aim to improve the accuracy in finding users who will perform the desired action, by assigning each user to a cluster, where the number of clusters is much smaller than the number of users (in the order of hundreds). Each user will fall into the same cluster with another user if their event history are similar. For this purpose, we modify the probabilistic latent semantic analysis (pLSA) model by assuming the independence of the user and the cluster id, given the history of events. This assumption helps us to identify a cluster of a new user without re-clustering all the users. We present the details of the algorithm we employed as well as the distributed implementation on Hadoop, and some initial results on the clusters that were generated by the algorithm.
Visual Sentiment Prediction with Deep Convolutional Neural Networks
Nov 21, 2014
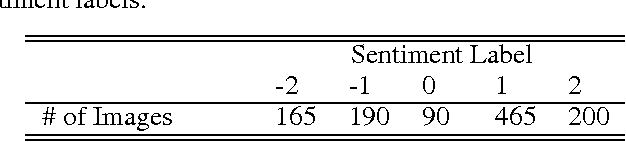
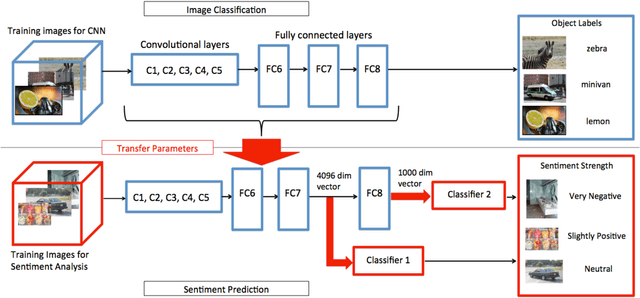

Images have become one of the most popular types of media through which users convey their emotions within online social networks. Although vast amount of research is devoted to sentiment analysis of textual data, there has been very limited work that focuses on analyzing sentiment of image data. In this work, we propose a novel visual sentiment prediction framework that performs image understanding with Deep Convolutional Neural Networks (CNN). Specifically, the proposed sentiment prediction framework performs transfer learning from a CNN with millions of parameters, which is pre-trained on large-scale data for object recognition. Experiments conducted on two real-world datasets from Twitter and Tumblr demonstrate the effectiveness of the proposed visual sentiment analysis framework.
Real Time Bid Optimization with Smooth Budget Delivery in Online Advertising
May 14, 2013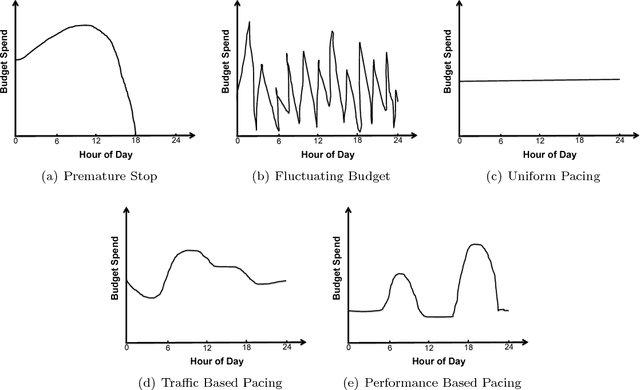

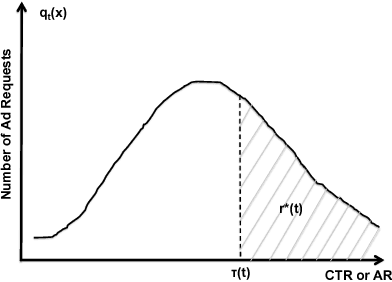
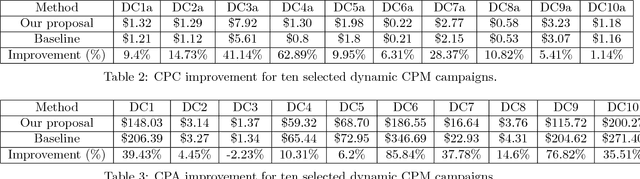
Today, billions of display ad impressions are purchased on a daily basis through a public auction hosted by real time bidding (RTB) exchanges. A decision has to be made for advertisers to submit a bid for each selected RTB ad request in milliseconds. Restricted by the budget, the goal is to buy a set of ad impressions to reach as many targeted users as possible. A desired action (conversion), advertiser specific, includes purchasing a product, filling out a form, signing up for emails, etc. In addition, advertisers typically prefer to spend their budget smoothly over the time in order to reach a wider range of audience accessible throughout a day and have a sustainable impact. However, since the conversions occur rarely and the occurrence feedback is normally delayed, it is very challenging to achieve both budget and performance goals at the same time. In this paper, we present an online approach to the smooth budget delivery while optimizing for the conversion performance. Our algorithm tries to select high quality impressions and adjust the bid price based on the prior performance distribution in an adaptive manner by distributing the budget optimally across time. Our experimental results from real advertising campaigns demonstrate the effectiveness of our proposed approach.