 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness-Aware Online Personalization
Sep 06, 2020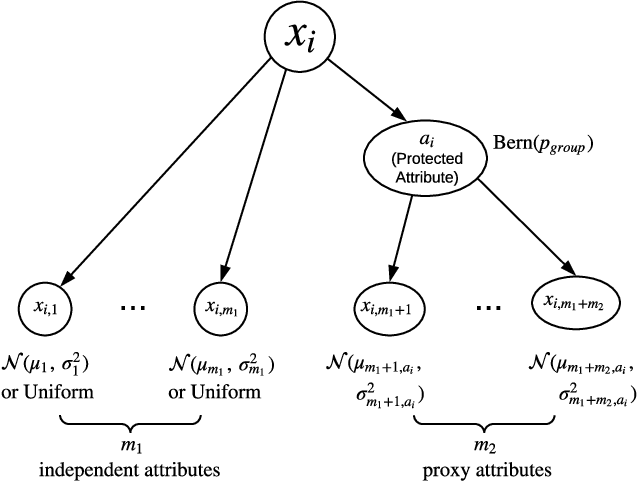
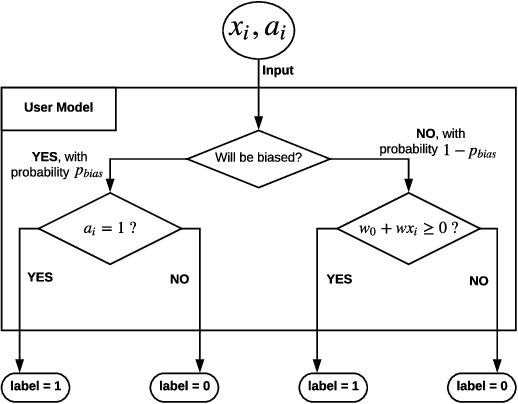
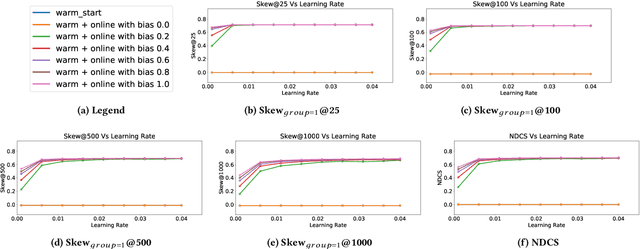
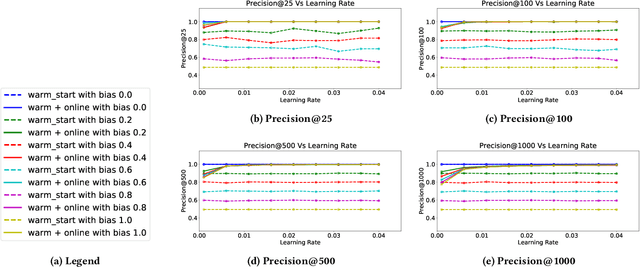
Decision making in crucial applications such as lending, hiring, and college admissions has witnessed increasing use of algorithmic models and techniques as a result of a confluence of factors such as ubiquitous connectivity, ability to collect, aggregate, and process large amounts of fine-grained data using cloud computing, and ease of access to applying sophisticated machine learning models. Quite often, such applications are powered by search and recommendation systems, which in turn make use of personalized ranking algorithms. At the same time, there is increasing awareness about the ethical and legal challenges posed by the use of such data-driven systems. Researchers and practitioners from different disciplines have recently highlighted the potential for such systems to discriminate against certain population groups, due to biases in the datasets utilized for learning their underlying recommendation models. We present a study of fairness in online personalization settings involving the ranking of individuals. Starting from a fair warm-start machine-learned model, we first demonstrate that online personalization can cause the model to learn to act in an unfair manner if the user is biased in his/her responses. For this purpose, we construct a stylized model for generating training data with potentially biased features as well as potentially biased labels and quantify the extent of bias that is learned by the model when the user responds in a biased manner as in many real-world scenarios. We then formulate the problem of learning personalized models under fairness constraints and present a regularization based approach for mitigating biases in machine learning. We demonstrate the efficacy of our approach through extensive simulations with different parameter settings. Code: https://github.com/groshanlal/Fairness-Aware-Online-Personalization
Fairness-Aware Ranking in Search & Recommendation Systems with Application to LinkedIn Talent Search
May 21, 2019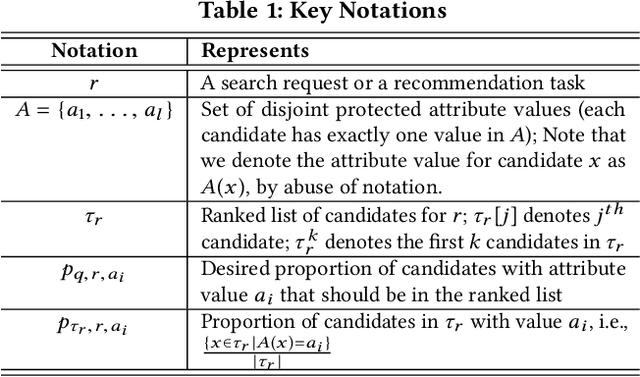
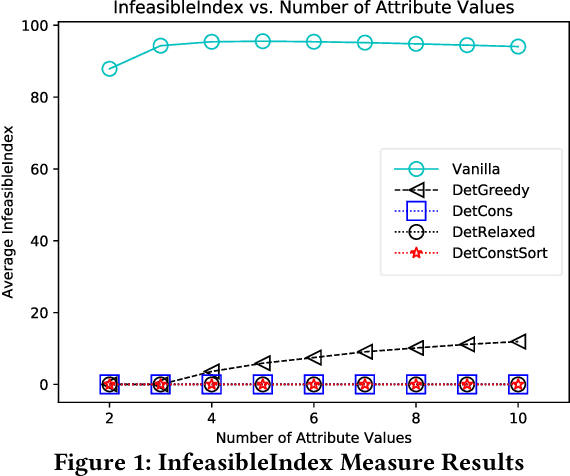

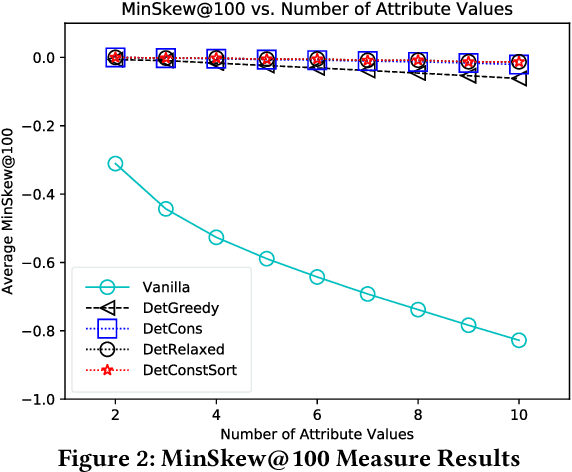
We present a framework for quantifying and mitigating algorithmic bias in mechanisms designed for ranking individuals, typically used as part of web-scale search and recommendation systems. We first propose complementary measures to quantify bias with respect to protected attributes such as gender and age. We then present algorithms for computing fairness-aware re-ranking of results. For a given search or recommendation task, our algorithms seek to achieve a desired distribution of top ranked results with respect to one or more protected attributes. We show that such a framework can be tailored to achieve fairness criteria such as equality of opportunity and demographic parity depending on the choice of the desired distribution. We evaluate the proposed algorithms via extensive simulations over different parameter choices, and study the effect of fairness-aware ranking on both bias and utility measures. We finally present the online A/B testing results from applying our framework towards representative ranking in LinkedIn Talent Search, and discuss the lessons learned in practice. Our approach resulted in tremendous improvement in the fairness metrics (nearly three fold increase in the number of search queries with representative results) without affecting the business metrics, which paved the way for deployment to 100% of LinkedIn Recruiter users worldwide. Ours is the first large-scale deployed framework for ensuring fairness in the hiring domain, with the potential positive impact for more than 630M LinkedIn members.
In-Session Personalization for Talent Search
Sep 18, 2018
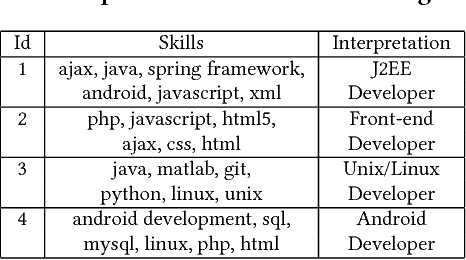

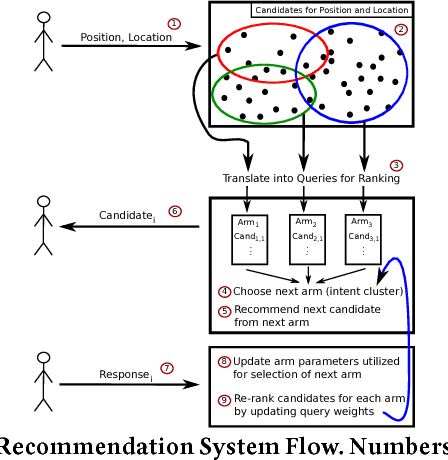
Previous efforts in recommendation of candidates for talent search followed the general pattern of receiving an initial search criteria and generating a set of candidates utilizing a pre-trained model. Traditionally, the generated recommendations are final, that is, the list of potential candidates is not modified unless the user explicitly changes his/her search criteria. In this paper, we are proposing a candidate recommendation model which takes into account the immediate feedback of the user, and updates the candidate recommendations at each step. This setting also allows for very uninformative initial search queries, since we pinpoint the user's intent due to the feedback during the search session. To achieve our goal, we employ an intent clustering method based on topic modeling which separates the candidate space into meaningful, possibly overlapping, subsets (which we call intent clusters) for each position. On top of the candidate segments, we apply a multi-armed bandit approach to choose which intent cluster is more appropriate for the current session. We also present an online learning scheme which updates the intent clusters within the session, due to user feedback, to achieve further personalization. Our offline experiments as well as the results from the online deployment of our solution demonstrate the benefits of our proposed methodology.
Talent Search and Recommendation Systems at LinkedIn: Practical Challenges and Lessons Learned
Sep 18, 2018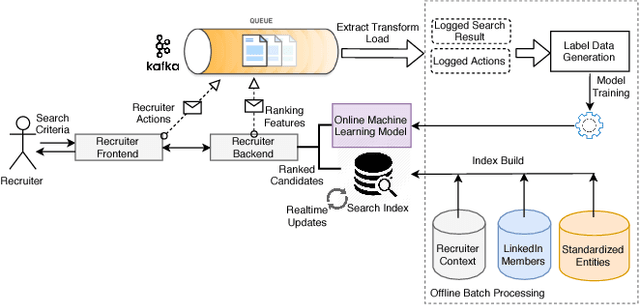
LinkedIn Talent Solutions business contributes to around 65% of LinkedIn's annual revenue, and provides tools for job providers to reach out to potential candidates and for job seekers to find suitable career opportunities. LinkedIn's job ecosystem has been designed as a platform to connect job providers and job seekers, and to serve as a marketplace for efficient matching between potential candidates and job openings. A key mechanism to help achieve these goals is the LinkedIn Recruiter product, which enables recruiters to search for relevant candidates and obtain candidate recommendations for their job postings. In this work, we highlight a set of unique information retrieval, system, and modeling challenges associated with talent search and recommendation systems.
Towards Deep and Representation Learning for Talent Search at LinkedIn
Sep 17, 2018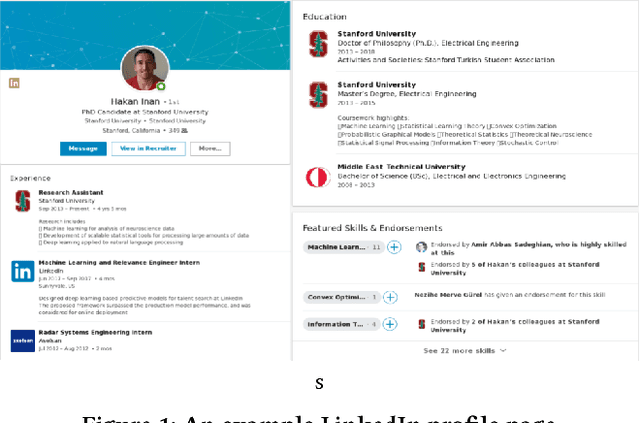
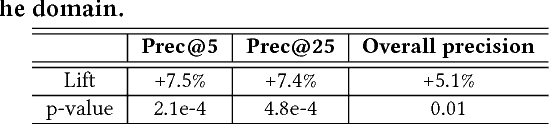
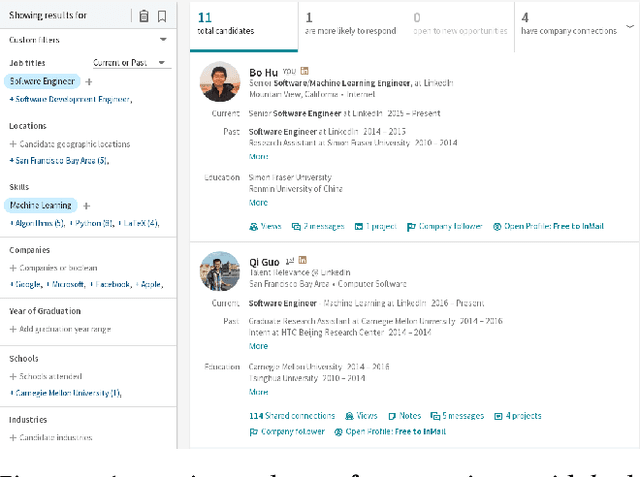
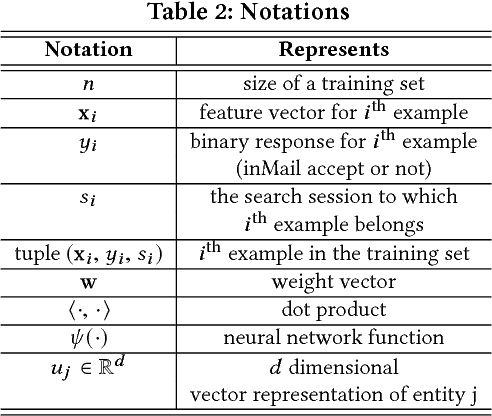
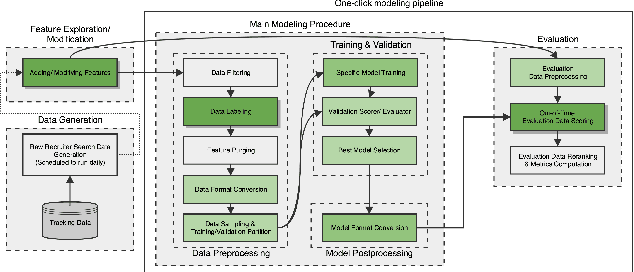
Talent search and recommendation systems at LinkedIn strive to match the potential candidates to the hiring needs of a recruiter or a hiring manager expressed in terms of a search query or a job posting. Recent work in this domain has mainly focused on linear models, which do not take complex relationships between features into account, as well as ensemble tree models, which introduce non-linearity but are still insufficient for exploring all the potential feature interactions, and strictly separate feature generation from modeling. In this paper, we present the results of our application of deep and representation learning models on LinkedIn Recruiter. Our key contributions include: (i) Learning semantic representations of sparse entities within the talent search domain, such as recruiter ids, candidate ids, and skill entity ids, for which we utilize neural network models that take advantage of LinkedIn Economic Graph, and (ii) Deep models for learning recruiter engagement and candidate response in talent search applications. We also explore learning to rank approaches applied to deep models, and show the benefits for the talent search use case. Finally, we present offline and online evaluation results for LinkedIn talent search and recommendation systems, and discuss potential challenges along the path to a fully deep model architecture. The challenges and approaches discussed generalize to any multi-faceted search engine.
Towards Data Quality Assessment in Online Advertising
Nov 30, 2017
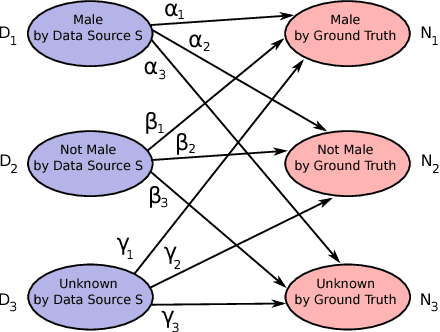
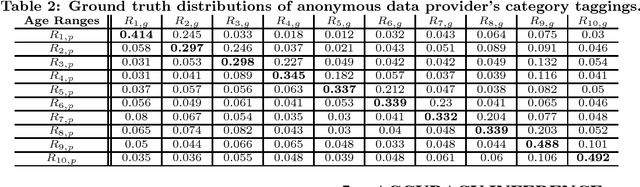
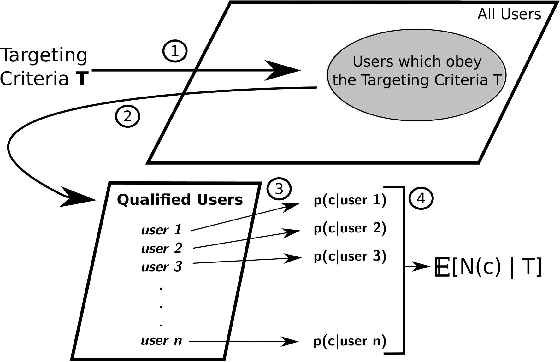
In online advertising, our aim is to match the advertisers with the most relevant users to optimize the campaign performance. In the pursuit of achieving this goal, multiple data sources provided by the advertisers or third-party data providers are utilized to choose the set of users according to the advertisers' targeting criteria. In this paper, we present a framework that can be applied to assess the quality of such data sources in large scale. This framework efficiently evaluates the similarity of a specific data source categorization to that of the ground truth, especially for those cases when the ground truth is accessible only in aggregate, and the user-level information is anonymized or unavailable due to privacy reasons. We propose multiple methodologies within this framework, present some preliminary assessment results, and evaluate how the methodologies compare to each other. We also present two use cases where we can utilize the data quality assessment results: the first use case is targeting specific user categories, and the second one is forecasting the desirable audiences we can reach for an online advertising campaign with pre-set targeting criteria.
* 10 pages, 7 Figures. This work has been presented in the KDD 2016 Workshop on Enterprise Intelligence
User Clustering in Online Advertising via Topic Models
Feb 24, 2015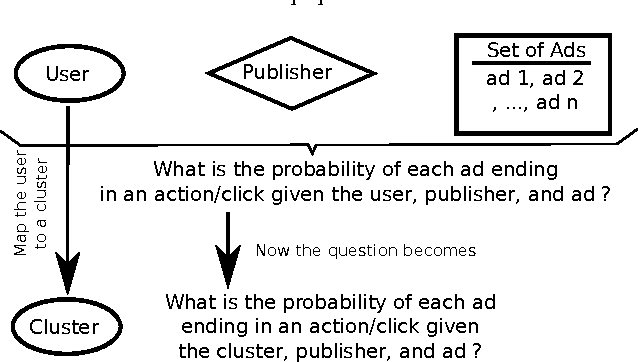
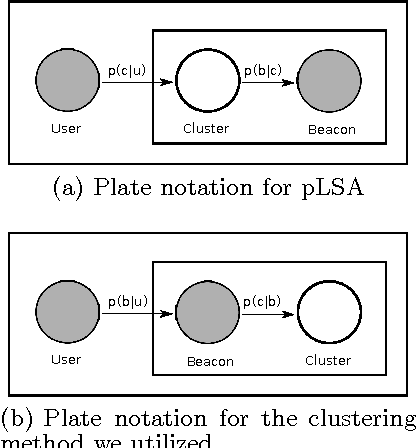


In the domain of online advertising, our aim is to serve the best ad to a user who visits a certain webpage, to maximize the chance of a desired action to be performed by this user after seeing the ad. While it is possible to generate a different prediction model for each user to tell if he/she will act on a given ad, the prediction result typically will be quite unreliable with huge variance, since the desired actions are extremely sparse, and the set of users is huge (hundreds of millions) and extremely volatile, i.e., a lot of new users are introduced everyday, or are no longer valid. In this paper we aim to improve the accuracy in finding users who will perform the desired action, by assigning each user to a cluster, where the number of clusters is much smaller than the number of users (in the order of hundreds). Each user will fall into the same cluster with another user if their event history are similar. For this purpose, we modify the probabilistic latent semantic analysis (pLSA) model by assuming the independence of the user and the cluster id, given the history of events. This assumption helps us to identify a cluster of a new user without re-clustering all the users. We present the details of the algorithm we employed as well as the distributed implementation on Hadoop, and some initial results on the clusters that were generated by the algorithm.
Multi-Touch Attribution Based Budget Allocation in Online Advertising
Feb 24, 2015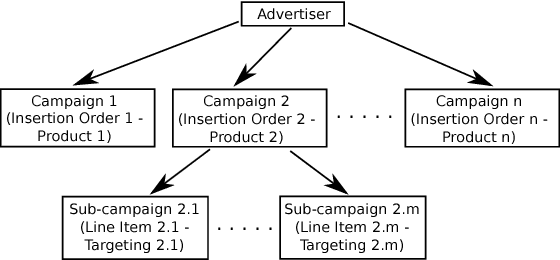
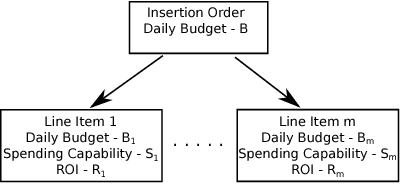
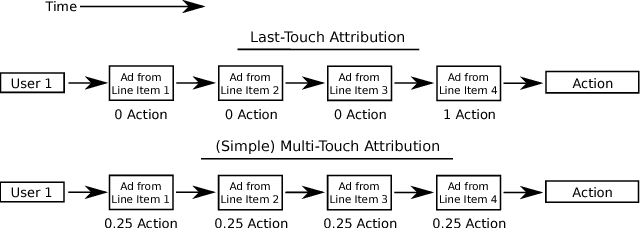
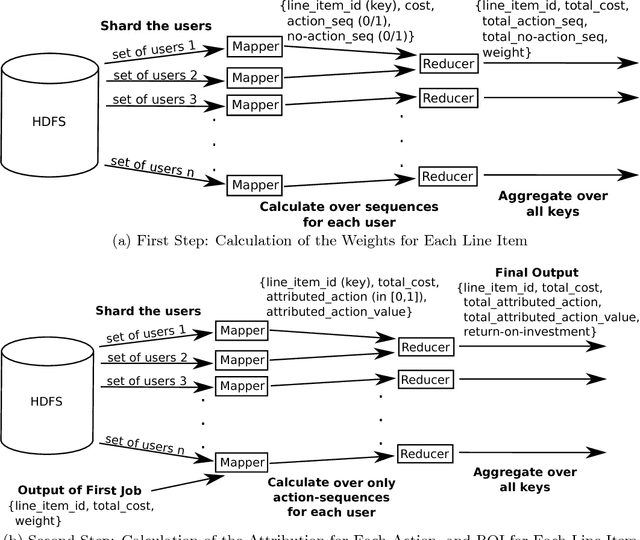
Budget allocation in online advertising deals with distributing the campaign (insertion order) level budgets to different sub-campaigns which employ different targeting criteria and may perform differently in terms of return-on-investment (ROI). In this paper, we present the efforts at Turn on how to best allocate campaign budget so that the advertiser or campaign-level ROI is maximized. To do this, it is crucial to be able to correctly determine the performance of sub-campaigns. This determination is highly related to the action-attribution problem, i.e. to be able to find out the set of ads, and hence the sub-campaigns that provided them to a user, that an action should be attributed to. For this purpose, we employ both last-touch (last ad gets all credit) and multi-touch (many ads share the credit) attribution methodologies. We present the algorithms deployed at Turn for the attribution problem, as well as their parallel implementation on the large advertiser performance datasets. We conclude the paper with our empirical comparison of last-touch and multi-touch attribution-based budget allocation in a real online advertising setting.