 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBorderless Long Speech Synthesis
Mar 20, 2026Most existing text-to-speech (TTS) systems either synthesize speech sentence by sentence and stitch the results together, or drive synthesis from plain-text dialogues alone. Both approaches leave models with little understanding of global context or paralinguistic cues, making it hard to capture real-world phenomena such as multi-speaker interactions (interruptions, overlapping speech), evolving emotional arcs, and varied acoustic environments. We introduce the Borderless Long Speech Synthesis framework for agent-centric, borderless long audio synthesis. Rather than targeting a single narrow task, the system is designed as a unified capability set spanning VoiceDesigner, multi-speaker synthesis, Instruct TTS, and long-form text synthesis. On the data side, we propose a "Labeling over filtering/cleaning" strategy and design a top-down, multi-level annotation schema we call Global-Sentence-Token. On the model side, we adopt a backbone with a continuous tokenizer and add Chain-of-Thought (CoT) reasoning together with Dimension Dropout, both of which markedly improve instruction following under complex conditions. We further show that the system is Native Agentic by design: the hierarchical annotation doubles as a Structured Semantic Interface between the LLM Agent and the synthesis engine, creating a layered control protocol stack that spans from scene semantics down to phonetic detail. Text thereby becomes an information-complete, wide-band control channel, enabling a front-end LLM to convert inputs of any modality into structured generation commands, extending the paradigm from Text2Speech to borderless long speech synthesis.
Pareto-guided Pipeline for Distilling Featherweight AI Agents in Mobile MOBA Games
Feb 07, 2026Recent advances in game AI have demonstrated the feasibility of training agents that surpass top-tier human professionals in complex environments such as Honor of Kings (HoK), a leading mobile multiplayer online battle arena (MOBA) game. However, deploying such powerful agents on mobile devices remains a major challenge. On one hand, the intricate multi-modal state representation and hierarchical action space of HoK demand large, sophisticated policy networks that are inherently difficult to compress into lightweight forms. On the other hand, production deployment requires high-frequency inference under strict energy and latency constraints on mobile platform. To the best of our knowledge, bridging large-scale game AI and practical on-device deployment has not been systematically studied. In this work, we propose a Pareto optimality guided pipeline and design a high-efficiency student architecture search space tailored for mobile execution, enabling systematic exploration of the trade-off between performance and efficiency. Experimental results demonstrate that the distilled model achieves remarkable efficiency, including an $12.4\times$ faster inference speed (under 0.5ms per frame) and a $15.6\times$ improvement in energy efficiency (under 0.5mAh per game), while retaining a 40.32% win rate against the original teacher model.
One Ring to Rule Them All: Unifying Group-Based RL via Dynamic Power-Mean Geometry
Jan 30, 2026Group-based reinforcement learning has evolved from the arithmetic mean of GRPO to the geometric mean of GMPO. While GMPO improves stability by constraining a conservative objective, it shares a fundamental limitation with GRPO: reliance on a fixed aggregation geometry that ignores the evolving and heterogeneous nature of each trajectory. In this work, we unify these approaches under Power-Mean Policy Optimization (PMPO), a generalized framework that parameterizes the aggregation geometry via the power-mean geometry exponent p. Within this framework, GRPO and GMPO are recovered as special cases. Theoretically, we demonstrate that adjusting p modulates the concentration of gradient updates, effectively reweighting tokens based on their advantage contribution. To determine p adaptively, we introduce a Clip-aware Effective Sample Size (ESS) mechanism. Specifically, we propose a deterministic rule that maps a trajectory clipping fraction to a target ESS. Then, we solve for the specific p to align the trajectory induced ESS with this target one. This allows PMPO to dynamically transition between the aggressive arithmetic mean for reliable trajectories and the conservative geometric mean for unstable ones. Experiments on multiple mathematical reasoning benchmarks demonstrate that PMPO outperforms strong baselines.
AdaTooler-V: Adaptive Tool-Use for Images and Videos
Dec 19, 2025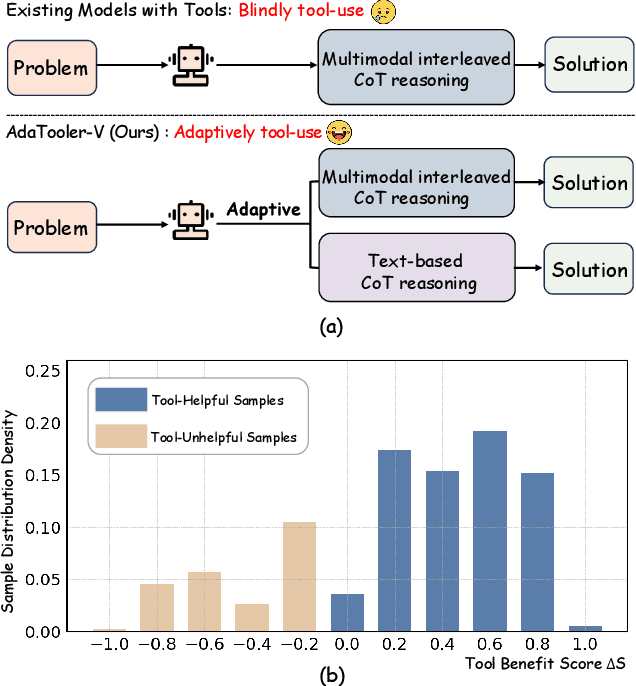
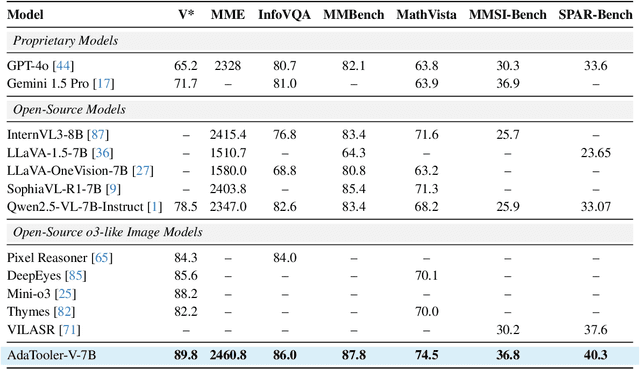
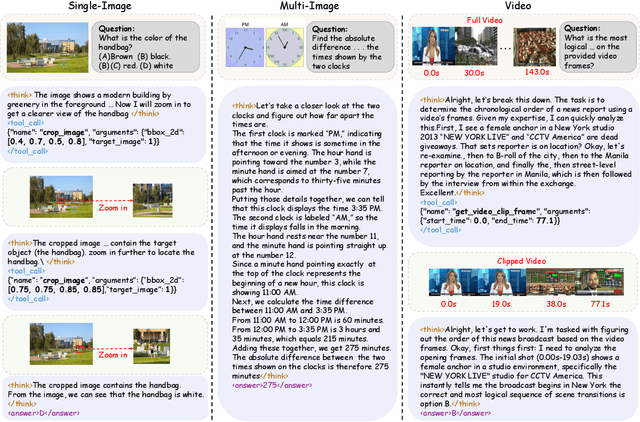
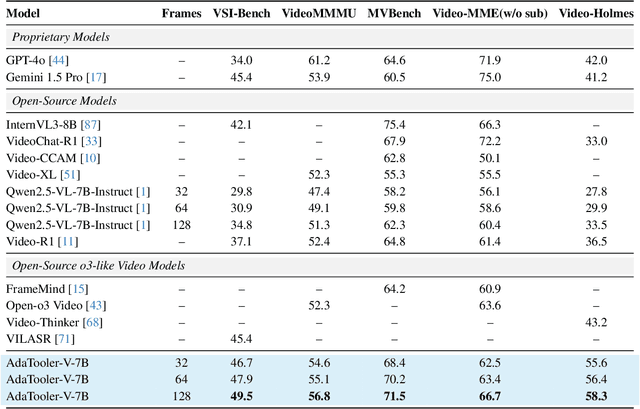
Recent advances have shown that multimodal large language models (MLLMs) benefit from multimodal interleaved chain-of-thought (CoT) with vision tool interactions. However, existing open-source models often exhibit blind tool-use reasoning patterns, invoking vision tools even when they are unnecessary, which significantly increases inference overhead and degrades model performance. To this end, we propose AdaTooler-V, an MLLM that performs adaptive tool-use by determining whether a visual problem truly requires tools. First, we introduce AT-GRPO, a reinforcement learning algorithm that adaptively adjusts reward scales based on the Tool Benefit Score of each sample, encouraging the model to invoke tools only when they provide genuine improvements. Moreover, we construct two datasets to support training: AdaTooler-V-CoT-100k for SFT cold start and AdaTooler-V-300k for RL with verifiable rewards across single-image, multi-image, and video data. Experiments across twelve benchmarks demonstrate the strong reasoning capability of AdaTooler-V, outperforming existing methods in diverse visual reasoning tasks. Notably, AdaTooler-V-7B achieves an accuracy of 89.8\% on the high-resolution benchmark V*, surpassing the commercial proprietary model GPT-4o and Gemini 1.5 Pro. All code, models, and data are released.
DiffRhythm 2: Efficient and High Fidelity Song Generation via Block Flow Matching
Oct 27, 2025Generating full-length, high-quality songs is challenging, as it requires maintaining long-term coherence both across text and music modalities and within the music modality itself. Existing non-autoregressive (NAR) frameworks, while capable of producing high-quality songs, often struggle with the alignment between lyrics and vocal. Concurrently, catering to diverse musical preferences necessitates reinforcement learning from human feedback (RLHF). However, existing methods often rely on merging multiple models during multi-preference optimization, which results in significant performance degradation. To address these challenges, we introduce DiffRhythm 2, an end-to-end framework designed for high-fidelity, controllable song generation. To tackle the lyric alignment problem, DiffRhythm 2 employs a semi-autoregressive architecture based on block flow matching. This design enables faithful alignment of lyrics to singing vocals without relying on external labels and constraints, all while preserving the high generation quality and efficiency of NAR models. To make this framework computationally tractable for long sequences, we implement a music variational autoencoder (VAE) that achieves a low frame rate of 5 Hz while still enabling high-fidelity audio reconstruction. In addition, to overcome the limitations of multi-preference optimization in RLHF, we propose cross-pair preference optimization. This method effectively mitigates the performance drop typically associated with model merging, allowing for more robust optimization across diverse human preferences. We further enhance musicality and structural coherence by introducing stochastic block representation alignment loss.
Towards Expressive Zero-Shot Speech Synthesis with Hierarchical Prosody Modeling
Jun 11, 2024



Recent research in zero-shot speech synthesis has made significant progress in speaker similarity. However, current efforts focus on timbre generalization rather than prosody modeling, which results in limited naturalness and expressiveness. To address this, we introduce a novel speech synthesis model trained on large-scale datasets, including both timbre and hierarchical prosody modeling. As timbre is a global attribute closely linked to expressiveness, we adopt a global vector to model speaker timbre while guiding prosody modeling. Besides, given that prosody contains both global consistency and local variations, we introduce a diffusion model as the pitch predictor and employ a prosody adaptor to model prosody hierarchically, further enhancing the prosody quality of the synthesized speech. Experimental results show that our model not only maintains comparable timbre quality to the baseline but also exhibits better naturalness and expressiveness.
Mini Honor of Kings: A Lightweight Environment for Multi-Agent Reinforcement Learning
Jun 06, 2024Games are widely used as research environments for multi-agent reinforcement learning (MARL), but they pose three significant challenges: limited customization, high computational demands, and oversimplification. To address these issues, we introduce the first publicly available map editor for the popular mobile game Honor of Kings and design a lightweight environment, Mini Honor of Kings (Mini HoK), for researchers to conduct experiments. Mini HoK is highly efficient, allowing experiments to be run on personal PCs or laptops while still presenting sufficient challenges for existing MARL algorithms. We have tested our environment on common MARL algorithms and demonstrated that these algorithms have yet to find optimal solutions within this environment. This facilitates the dissemination and advancement of MARL methods within the research community. Additionally, we hope that more researchers will leverage the Honor of Kings map editor to develop innovative and scientifically valuable new maps. Our code and user manual are available at: https://github.com/tencent-ailab/mini-hok.
In-Session Personalization for Talent Search
Sep 18, 2018
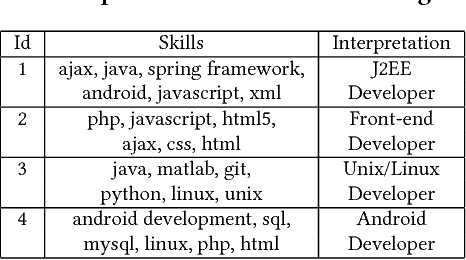

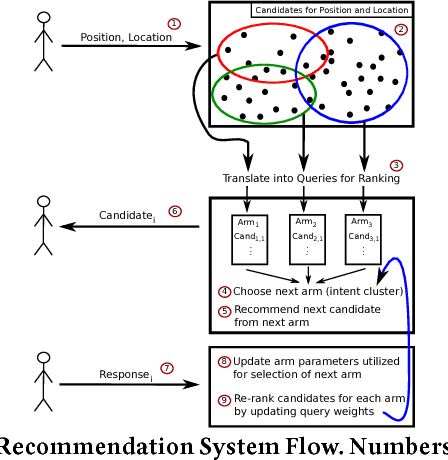
Previous efforts in recommendation of candidates for talent search followed the general pattern of receiving an initial search criteria and generating a set of candidates utilizing a pre-trained model. Traditionally, the generated recommendations are final, that is, the list of potential candidates is not modified unless the user explicitly changes his/her search criteria. In this paper, we are proposing a candidate recommendation model which takes into account the immediate feedback of the user, and updates the candidate recommendations at each step. This setting also allows for very uninformative initial search queries, since we pinpoint the user's intent due to the feedback during the search session. To achieve our goal, we employ an intent clustering method based on topic modeling which separates the candidate space into meaningful, possibly overlapping, subsets (which we call intent clusters) for each position. On top of the candidate segments, we apply a multi-armed bandit approach to choose which intent cluster is more appropriate for the current session. We also present an online learning scheme which updates the intent clusters within the session, due to user feedback, to achieve further personalization. Our offline experiments as well as the results from the online deployment of our solution demonstrate the benefits of our proposed methodology.
Joint Video and Text Parsing for Understanding Events and Answering Queries
Feb 21, 2014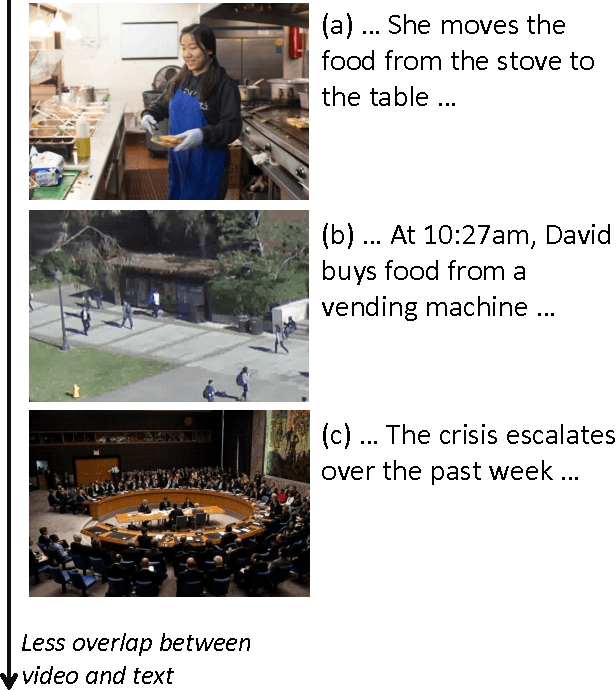
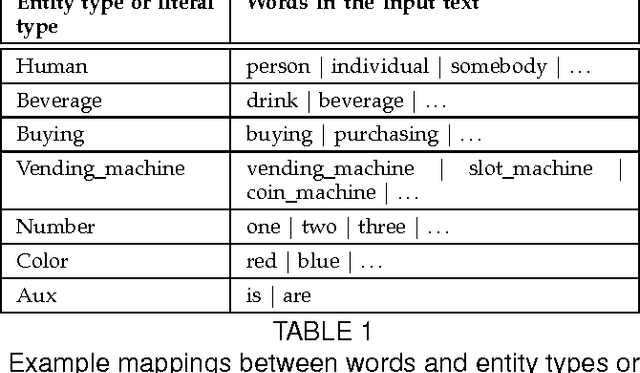
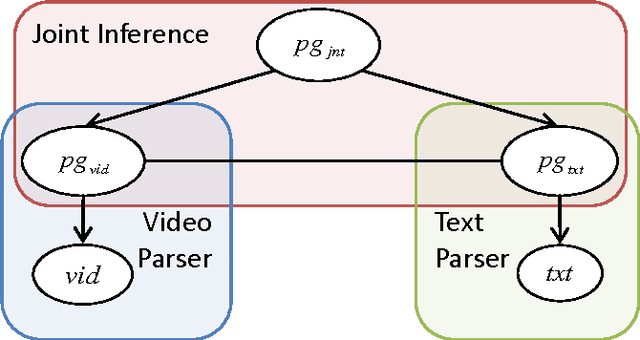

We propose a framework for parsing video and text jointly for understanding events and answering user queries. Our framework produces a parse graph that represents the compositional structures of spatial information (objects and scenes), temporal information (actions and events) and causal information (causalities between events and fluents) in the video and text. The knowledge representation of our framework is based on a spatial-temporal-causal And-Or graph (S/T/C-AOG), which jointly models possible hierarchical compositions of objects, scenes and events as well as their interactions and mutual contexts, and specifies the prior probabilistic distribution of the parse graphs. We present a probabilistic generative model for joint parsing that captures the relations between the input video/text, their corresponding parse graphs and the joint parse graph. Based on the probabilistic model, we propose a joint parsing system consisting of three modules: video parsing, text parsing and joint inference. Video parsing and text parsing produce two parse graphs from the input video and text respectively. The joint inference module produces a joint parse graph by performing matching, deduction and revision on the video and text parse graphs. The proposed framework has the following objectives: Firstly, we aim at deep semantic parsing of video and text that goes beyond the traditional bag-of-words approaches; Secondly, we perform parsing and reasoning across the spatial, temporal and causal dimensions based on the joint S/T/C-AOG representation; Thirdly, we show that deep joint parsing facilitates subsequent applications such as generating narrative text descriptions and answering queries in the forms of who, what, when, where and why. We empirically evaluated our system based on comparison against ground-truth as well as accuracy of query answering and obtained satisfactory results.