 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmented Reality based Simulated Data (ARSim) with multi-view consistency for AV perception networks
Mar 22, 2024



Detecting a diverse range of objects under various driving scenarios is essential for the effectiveness of autonomous driving systems. However, the real-world data collected often lacks the necessary diversity presenting a long-tail distribution. Although synthetic data has been utilized to overcome this issue by generating virtual scenes, it faces hurdles such as a significant domain gap and the substantial efforts required from 3D artists to create realistic environments. To overcome these challenges, we present ARSim, a fully automated, comprehensive, modular framework designed to enhance real multi-view image data with 3D synthetic objects of interest. The proposed method integrates domain adaptation and randomization strategies to address covariate shift between real and simulated data by inferring essential domain attributes from real data and employing simulation-based randomization for other attributes. We construct a simplified virtual scene using real data and strategically place 3D synthetic assets within it. Illumination is achieved by estimating light distribution from multiple images capturing the surroundings of the vehicle. Camera parameters from real data are employed to render synthetic assets in each frame. The resulting augmented multi-view consistent dataset is used to train a multi-camera perception network for autonomous vehicles. Experimental results on various AV perception tasks demonstrate the superior performance of networks trained on the augmented dataset.
HazardNet: Road Debris Detection by Augmentation of Synthetic Models
Mar 14, 2023



We present an algorithm to detect unseen road debris using a small set of synthetic models. Early detection of road debris is critical for safe autonomous or assisted driving, yet the development of a robust road debris detection model has not been widely discussed. There are two main challenges to building a road debris detector: first, data collection of road debris is challenging since hazardous objects on the road are rare to encounter in real driving scenarios; second, the variability of road debris is broad, ranging from a very small brick to a large fallen tree. To overcome these challenges, we propose a novel approach to few-shot learning of road debris that uses semantic augmentation and domain randomization to augment real road images with synthetic models. We constrain the problem domain to uncommon objects on the road and allow the deep neural network, HazardNet, to learn the semantic meaning of road debris to eventually detect unseen road debris. Our results demonstrate that HazardNet is able to accurately detect real road debris when only trained on synthetic objects in augmented images.
Gen-LaneNet: A Generalized and Scalable Approach for 3D Lane Detection
Mar 24, 2020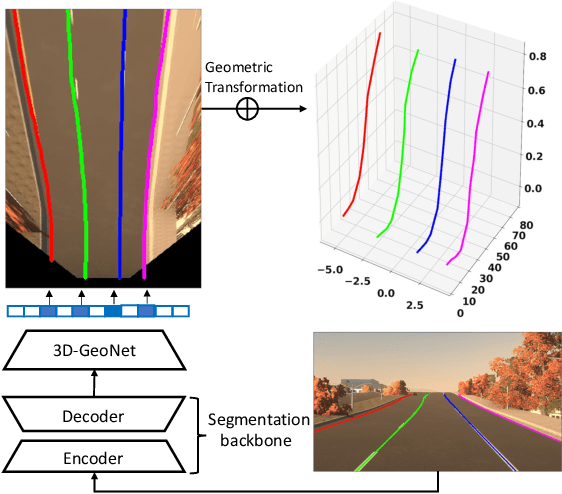
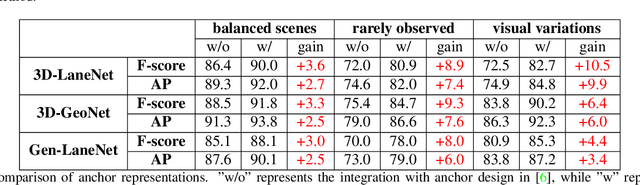
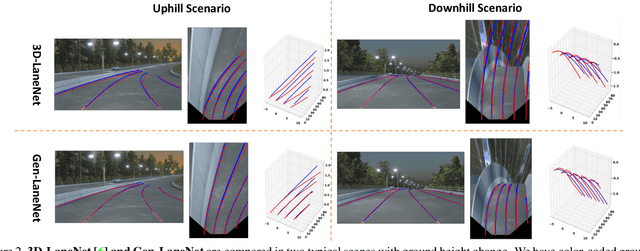
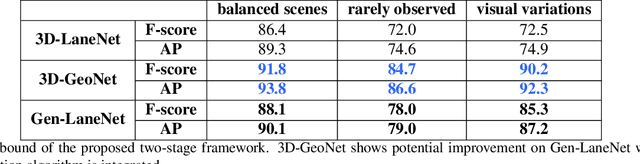
We present a generalized and scalable method, called Gen-LaneNet, to detect 3D lanes from a single image. The method, inspired by the latest state-of-the-art 3D-LaneNet, is a unified framework solving image encoding, spatial transform of features and 3D lane prediction in a single network. However, we propose unique designs for Gen-LaneNet in two folds. First, we introduce a new geometry-guided lane anchor representation in a new coordinate frame and apply a specific geometric transformation to directly calculate real 3D lane points from the network output. We demonstrate that aligning the lane points with the underlying top-view features in the new coordinate frame is critical towards a generalized method in handling unfamiliar scenes. Second, we present a scalable two-stage framework that decouples the learning of image segmentation subnetwork and geometry encoding subnetwork. Compared to 3D-LaneNet, the proposed Gen-LaneNet drastically reduces the amount of 3D lane labels required to achieve a robust solution in real-world application. Moreover, we release a new synthetic dataset and its construction strategy to encourage the development and evaluation of 3D lane detection methods. In experiments, we conduct extensive ablation study to substantiate the proposed Gen-LaneNet significantly outperforms 3D-LaneNet in average precision(AP) and F-score.
Complex Events Recognition under Uncertainty in a Sensor Network
Nov 01, 2014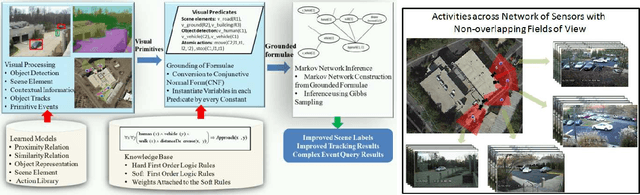
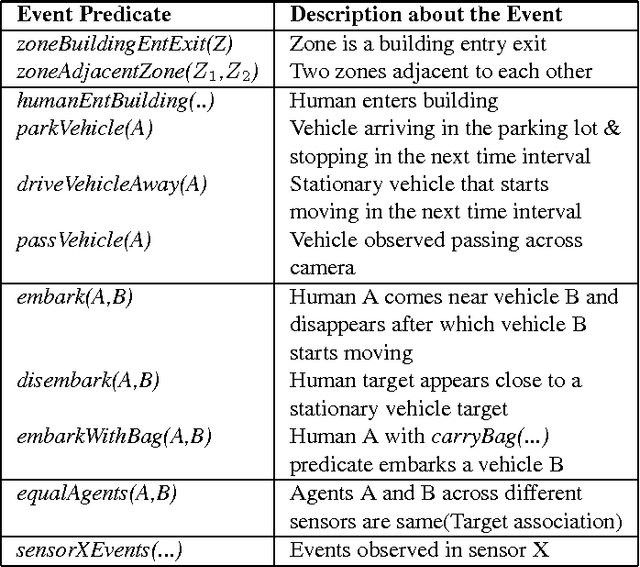


Automated extraction of semantic information from a network of sensors for cognitive analysis and human-like reasoning is a desired capability in future ground surveillance systems. We tackle the problem of complex decision making under uncertainty in network information environment, where lack of effective visual processing tools, incomplete domain knowledge frequently cause uncertainty in the visual primitives, leading to sub-optimal decisions. While state-of-the-art vision techniques exist in detecting visual entities (humans, vehicles and scene elements) in an image, a missing functionality is the ability to merge the information to reveal meaningful information for high level inference. In this work, we develop a probabilistic first order predicate logic(FOPL) based reasoning system for recognizing complex events in synchronized stream of videos, acquired from sensors with non-overlapping fields of view. We adopt Markov Logic Network(MLN) as a tool to model uncertainty in observations, and fuse information extracted from heterogeneous data in a probabilistically consistent way. MLN overcomes strong dependence on pure empirical learning by incorporating domain knowledge, in the form of user-defined rules and confidences associated with them. This work demonstrates that the MLN based decision control system can be made scalable to model statistical relations between a variety of entities and over long video sequences. Experiments with real-world data, under a variety of settings, illustrate the mathematical soundness and wide-ranging applicability of our approach.
Joint Video and Text Parsing for Understanding Events and Answering Queries
Feb 21, 2014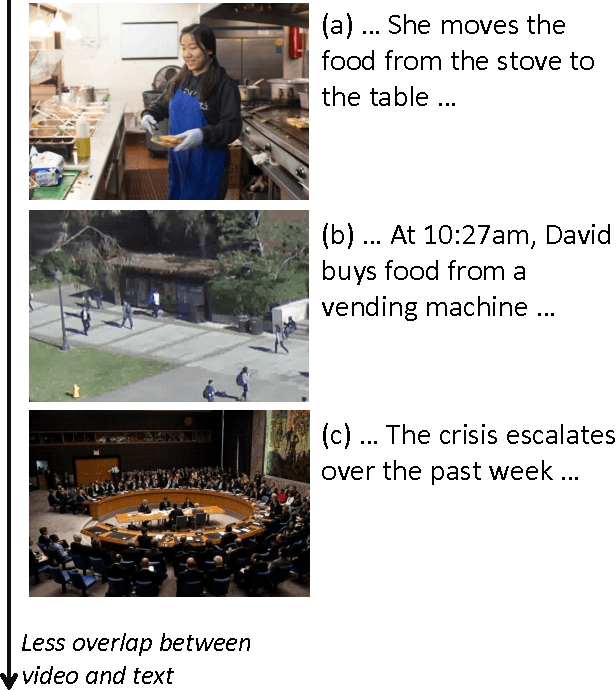
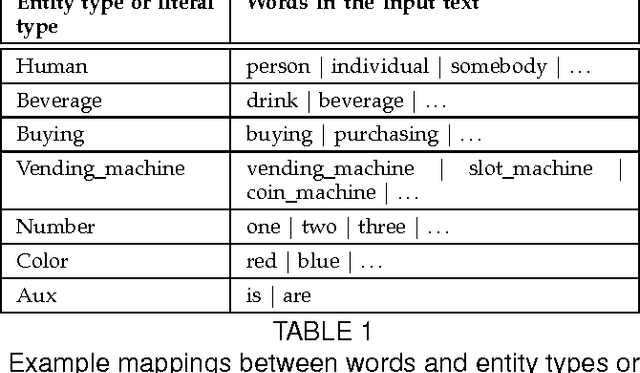
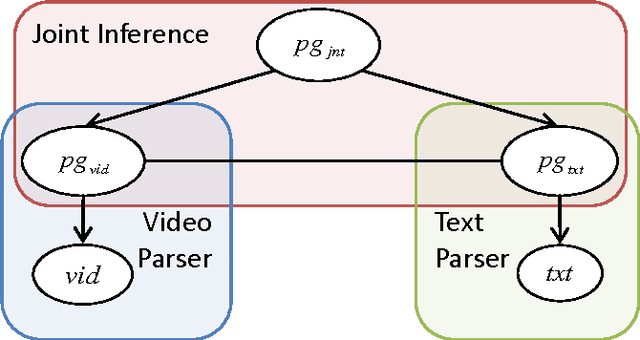

We propose a framework for parsing video and text jointly for understanding events and answering user queries. Our framework produces a parse graph that represents the compositional structures of spatial information (objects and scenes), temporal information (actions and events) and causal information (causalities between events and fluents) in the video and text. The knowledge representation of our framework is based on a spatial-temporal-causal And-Or graph (S/T/C-AOG), which jointly models possible hierarchical compositions of objects, scenes and events as well as their interactions and mutual contexts, and specifies the prior probabilistic distribution of the parse graphs. We present a probabilistic generative model for joint parsing that captures the relations between the input video/text, their corresponding parse graphs and the joint parse graph. Based on the probabilistic model, we propose a joint parsing system consisting of three modules: video parsing, text parsing and joint inference. Video parsing and text parsing produce two parse graphs from the input video and text respectively. The joint inference module produces a joint parse graph by performing matching, deduction and revision on the video and text parse graphs. The proposed framework has the following objectives: Firstly, we aim at deep semantic parsing of video and text that goes beyond the traditional bag-of-words approaches; Secondly, we perform parsing and reasoning across the spatial, temporal and causal dimensions based on the joint S/T/C-AOG representation; Thirdly, we show that deep joint parsing facilitates subsequent applications such as generating narrative text descriptions and answering queries in the forms of who, what, when, where and why. We empirically evaluated our system based on comparison against ground-truth as well as accuracy of query answering and obtained satisfactory results.