 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Events Recognition under Uncertainty in a Sensor Network
Nov 01, 2014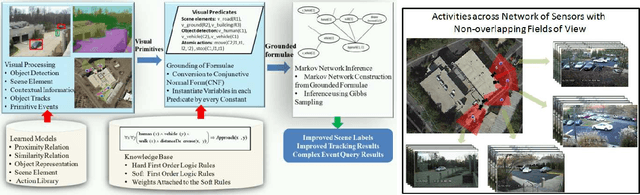
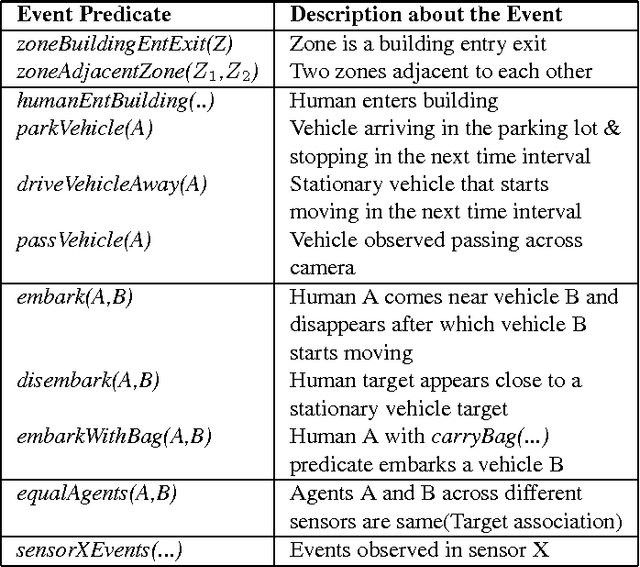


Automated extraction of semantic information from a network of sensors for cognitive analysis and human-like reasoning is a desired capability in future ground surveillance systems. We tackle the problem of complex decision making under uncertainty in network information environment, where lack of effective visual processing tools, incomplete domain knowledge frequently cause uncertainty in the visual primitives, leading to sub-optimal decisions. While state-of-the-art vision techniques exist in detecting visual entities (humans, vehicles and scene elements) in an image, a missing functionality is the ability to merge the information to reveal meaningful information for high level inference. In this work, we develop a probabilistic first order predicate logic(FOPL) based reasoning system for recognizing complex events in synchronized stream of videos, acquired from sensors with non-overlapping fields of view. We adopt Markov Logic Network(MLN) as a tool to model uncertainty in observations, and fuse information extracted from heterogeneous data in a probabilistically consistent way. MLN overcomes strong dependence on pure empirical learning by incorporating domain knowledge, in the form of user-defined rules and confidences associated with them. This work demonstrates that the MLN based decision control system can be made scalable to model statistical relations between a variety of entities and over long video sequences. Experiments with real-world data, under a variety of settings, illustrate the mathematical soundness and wide-ranging applicability of our approach.
Coupling Top-down and Bottom-up Methods for 3D Human Pose and Shape Estimation from Monocular Image Sequences
Oct 06, 2014



Until recently Intelligence, Surveillance, and Reconnaissance (ISR) focused on acquiring behavioral information of the targets and their activities. Continuous evolution of intelligence being gathered of the human centric activities has put increased focus on the humans, especially inferring their innate characteristics - size, shapes and physiology. These bio-signatures extracted from the surveillance sensors can be used to deduce age, ethnicity, gender and actions, and further characterize human actions in unseen scenarios. However, recovery of pose and shape of humans in such monocular videos is inherently an ill-posed problem, marked by frequent depth and view based ambiguities due to self-occlusion, foreshortening and misalignment. The likelihood function often yields a highly multimodal posterior that is difficult to propagate even using the most advanced particle filtering(PF) algorithms. Motivated by the recent success of the discriminative approaches to efficiently predict 3D poses directly from the 2D images, we present several principled approaches to integrate predictive cues using learned regression models to sustain multimodality of the posterior during tracking. Additionally, these learned priors can be actively adapted to the test data using a likelihood based feedback mechanism. Estimated 3D poses are then used to fit 3D human shape model to each frame independently for inferring anthropometric bio-signatures. The proposed system is fully automated, robust to noisy test data and has ability to swiftly recover from tracking failures even after confronting with significant errors. We evaluate the system on a large number of monocular human motion sequences.