 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetry-Aware Steering of Equivariant Diffusion Policies: Benefits and Limits
Dec 12, 2025Equivariant diffusion policies (EDPs) combine the generative expressivity of diffusion models with the strong generalization and sample efficiency afforded by geometric symmetries. While steering these policies with reinforcement learning (RL) offers a promising mechanism for fine-tuning beyond demonstration data, directly applying standard (non-equivariant) RL can be sample-inefficient and unstable, as it ignores the symmetries that EDPs are designed to exploit. In this paper, we theoretically establish that the diffusion process of an EDP is equivariant, which in turn induces a group-invariant latent-noise MDP that is well-suited for equivariant diffusion steering. Building on this theory, we introduce a principled symmetry-aware steering framework and compare standard, equivariant, and approximately equivariant RL strategies through comprehensive experiments across tasks with varying degrees of symmetry. While we identify the practical boundaries of strict equivariance under symmetry breaking, we show that exploiting symmetry during the steering process yields substantial benefits-enhancing sample efficiency, preventing value divergence, and achieving strong policy improvements even when EDPs are trained from extremely limited demonstrations.
Scale-invariant and View-relational Representation Learning for Full Surround Monocular Depth
Dec 09, 2025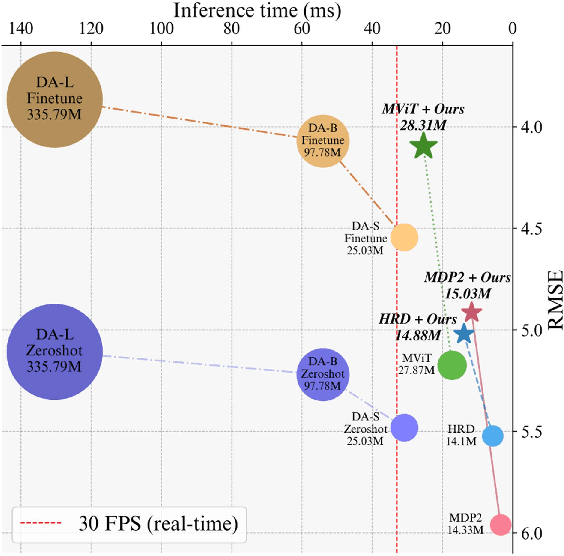
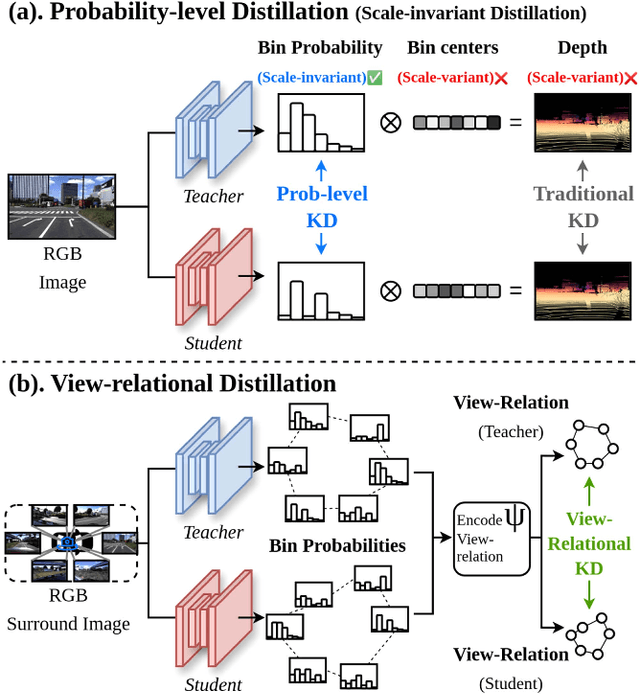
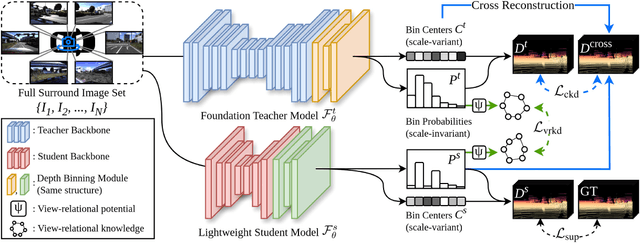

Recent foundation models demonstrate strong generalization capabilities in monocular depth estimation. However, directly applying these models to Full Surround Monocular Depth Estimation (FSMDE) presents two major challenges: (1) high computational cost, which limits real-time performance, and (2) difficulty in estimating metric-scale depth, as these models are typically trained to predict only relative depth. To address these limitations, we propose a novel knowledge distillation strategy that transfers robust depth knowledge from a foundation model to a lightweight FSMDE network. Our approach leverages a hybrid regression framework combining the knowledge distillation scheme--traditionally used in classification--with a depth binning module to enhance scale consistency. Specifically, we introduce a cross-interaction knowledge distillation scheme that distills the scale-invariant depth bin probabilities of a foundation model into the student network while guiding it to infer metric-scale depth bin centers from ground-truth depth. Furthermore, we propose view-relational knowledge distillation, which encodes structural relationships among adjacent camera views and transfers them to enhance cross-view depth consistency. Experiments on DDAD and nuScenes demonstrate the effectiveness of our method compared to conventional supervised methods and existing knowledge distillation approaches. Moreover, our method achieves a favorable trade-off between performance and efficiency, meeting real-time requirements.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Augmented Reality based Simulated Data (ARSim) with multi-view consistency for AV perception networks
Mar 22, 2024



Detecting a diverse range of objects under various driving scenarios is essential for the effectiveness of autonomous driving systems. However, the real-world data collected often lacks the necessary diversity presenting a long-tail distribution. Although synthetic data has been utilized to overcome this issue by generating virtual scenes, it faces hurdles such as a significant domain gap and the substantial efforts required from 3D artists to create realistic environments. To overcome these challenges, we present ARSim, a fully automated, comprehensive, modular framework designed to enhance real multi-view image data with 3D synthetic objects of interest. The proposed method integrates domain adaptation and randomization strategies to address covariate shift between real and simulated data by inferring essential domain attributes from real data and employing simulation-based randomization for other attributes. We construct a simplified virtual scene using real data and strategically place 3D synthetic assets within it. Illumination is achieved by estimating light distribution from multiple images capturing the surroundings of the vehicle. Camera parameters from real data are employed to render synthetic assets in each frame. The resulting augmented multi-view consistent dataset is used to train a multi-camera perception network for autonomous vehicles. Experimental results on various AV perception tasks demonstrate the superior performance of networks trained on the augmented dataset.
DPPD: Deformable Polar Polygon Object Detection
Apr 05, 2023Regular object detection methods output rectangle bounding boxes, which are unable to accurately describe the actual object shapes. Instance segmentation methods output pixel-level labels, which are computationally expensive for real-time applications. Therefore, a polygon representation is needed to achieve precise shape alignment, while retaining low computation cost. We develop a novel Deformable Polar Polygon Object Detection method (DPPD) to detect objects in polygon shapes. In particular, our network predicts, for each object, a sparse set of flexible vertices to construct the polygon, where each vertex is represented by a pair of angle and distance in the Polar coordinate system. To enable training, both ground truth and predicted polygons are densely resampled to have the same number of vertices with equal-spaced raypoints. The resampling operation is fully differentable, allowing gradient back-propagation. Sparse polygon predicton ensures high-speed runtime inference while dense resampling allows the network to learn object shapes with high precision. The polygon detection head is established on top of an anchor-free and NMS-free network architecture. DPPD has been demonstrated successfully in various object detection tasks for autonomous driving such as traffic-sign, crosswalk, vehicle and pedestrian objects.
NVAutoNet: Fast and Accurate 360$^{\circ}$ 3D Visual Perception For Self Driving
Mar 30, 2023

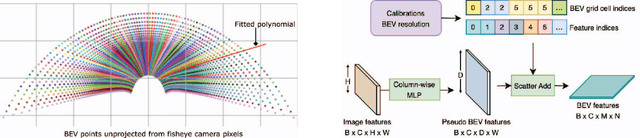

Robust real-time perception of 3D world is essential to the autonomous vehicle. We introduce an end-to-end surround camera perception system for self-driving. Our perception system is a novel multi-task, multi-camera network which takes a variable set of time-synced camera images as input and produces a rich collection of 3D signals such as sizes, orientations, locations of obstacles, parking spaces and free-spaces, etc. Our perception network is modular and end-to-end: 1) the outputs can be consumed directly by downstream modules without any post-processing such as clustering and fusion -- improving speed of model deployment and in-car testing 2) the whole network training is done in one single stage -- improving speed of model improvement and iterations. The network is well designed to have high accuracy while running at 53 fps on NVIDIA Orin SoC (system-on-a-chip). The network is robust to sensor mounting variations (within some tolerances) and can be quickly customized for different vehicle types via efficient model fine-tuning thanks of its capability of taking calibration parameters as additional inputs during training and testing. Most importantly, our network has been successfully deployed and being tested on real roads.
HazardNet: Road Debris Detection by Augmentation of Synthetic Models
Mar 14, 2023



We present an algorithm to detect unseen road debris using a small set of synthetic models. Early detection of road debris is critical for safe autonomous or assisted driving, yet the development of a robust road debris detection model has not been widely discussed. There are two main challenges to building a road debris detector: first, data collection of road debris is challenging since hazardous objects on the road are rare to encounter in real driving scenarios; second, the variability of road debris is broad, ranging from a very small brick to a large fallen tree. To overcome these challenges, we propose a novel approach to few-shot learning of road debris that uses semantic augmentation and domain randomization to augment real road images with synthetic models. We constrain the problem domain to uncommon objects on the road and allow the deep neural network, HazardNet, to learn the semantic meaning of road debris to eventually detect unseen road debris. Our results demonstrate that HazardNet is able to accurately detect real road debris when only trained on synthetic objects in augmented images.