 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVAutoNet: Fast and Accurate 360$^{\circ}$ 3D Visual Perception For Self Driving
Mar 30, 2023

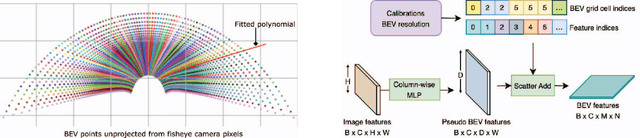

Robust real-time perception of 3D world is essential to the autonomous vehicle. We introduce an end-to-end surround camera perception system for self-driving. Our perception system is a novel multi-task, multi-camera network which takes a variable set of time-synced camera images as input and produces a rich collection of 3D signals such as sizes, orientations, locations of obstacles, parking spaces and free-spaces, etc. Our perception network is modular and end-to-end: 1) the outputs can be consumed directly by downstream modules without any post-processing such as clustering and fusion -- improving speed of model deployment and in-car testing 2) the whole network training is done in one single stage -- improving speed of model improvement and iterations. The network is well designed to have high accuracy while running at 53 fps on NVIDIA Orin SoC (system-on-a-chip). The network is robust to sensor mounting variations (within some tolerances) and can be quickly customized for different vehicle types via efficient model fine-tuning thanks of its capability of taking calibration parameters as additional inputs during training and testing. Most importantly, our network has been successfully deployed and being tested on real roads.
Explainable Object-induced Action Decision for Autonomous Vehicles
Mar 20, 2020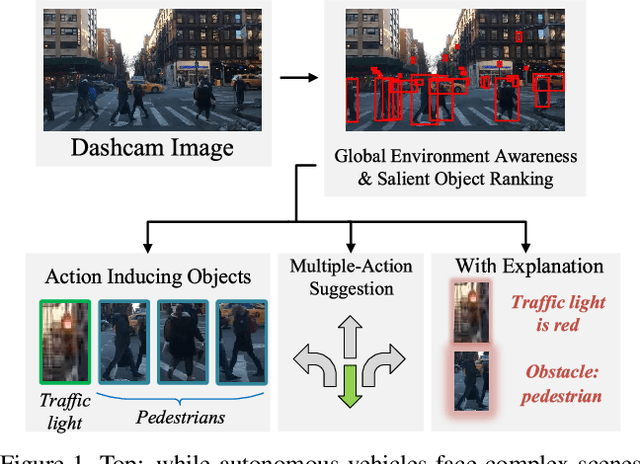
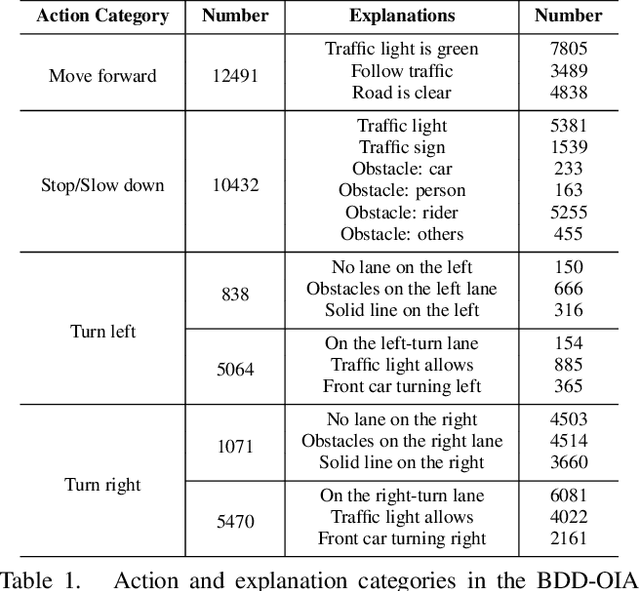
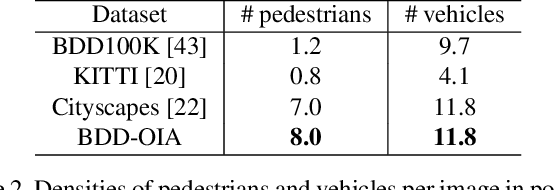

A new paradigm is proposed for autonomous driving. The new paradigm lies between the end-to-end and pipelined approaches, and is inspired by how humans solve the problem. While it relies on scene understanding, the latter only considers objects that could originate hazard. These are denoted as action-inducing, since changes in their state should trigger vehicle actions. They also define a set of explanations for these actions, which should be produced jointly with the latter. An extension of the BDD100K dataset, annotated for a set of 4 actions and 21 explanations, is proposed. A new multi-task formulation of the problem, which optimizes the accuracy of both action commands and explanations, is then introduced. A CNN architecture is finally proposed to solve this problem, by combining reasoning about action inducing objects and global scene context. Experimental results show that the requirement of explanations improves the recognition of action-inducing objects, which in turn leads to better action predictions.