 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVAutoNet: Fast and Accurate 360$^{\circ}$ 3D Visual Perception For Self Driving
Mar 30, 2023

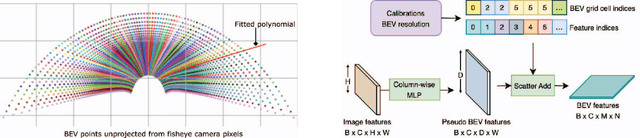

Robust real-time perception of 3D world is essential to the autonomous vehicle. We introduce an end-to-end surround camera perception system for self-driving. Our perception system is a novel multi-task, multi-camera network which takes a variable set of time-synced camera images as input and produces a rich collection of 3D signals such as sizes, orientations, locations of obstacles, parking spaces and free-spaces, etc. Our perception network is modular and end-to-end: 1) the outputs can be consumed directly by downstream modules without any post-processing such as clustering and fusion -- improving speed of model deployment and in-car testing 2) the whole network training is done in one single stage -- improving speed of model improvement and iterations. The network is well designed to have high accuracy while running at 53 fps on NVIDIA Orin SoC (system-on-a-chip). The network is robust to sensor mounting variations (within some tolerances) and can be quickly customized for different vehicle types via efficient model fine-tuning thanks of its capability of taking calibration parameters as additional inputs during training and testing. Most importantly, our network has been successfully deployed and being tested on real roads.
SHREC 2021: Track on Skeleton-based Hand Gesture Recognition in the Wild
Jun 21, 2021
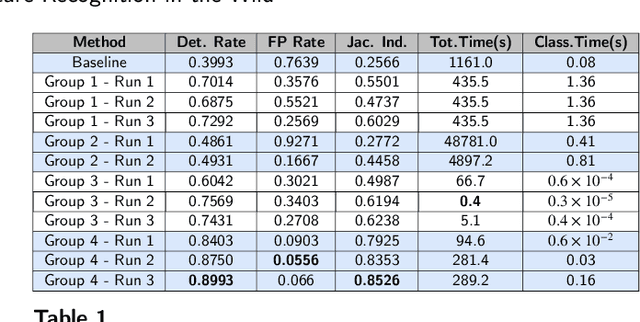

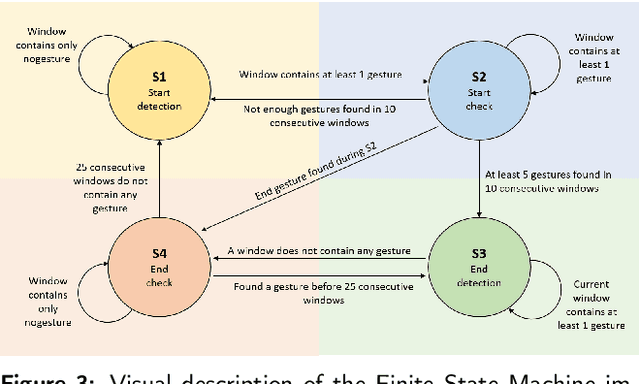
Gesture recognition is a fundamental tool to enable novel interaction paradigms in a variety of application scenarios like Mixed Reality environments, touchless public kiosks, entertainment systems, and more. Recognition of hand gestures can be nowadays performed directly from the stream of hand skeletons estimated by software provided by low-cost trackers (Ultraleap) and MR headsets (Hololens, Oculus Quest) or by video processing software modules (e.g. Google Mediapipe). Despite the recent advancements in gesture and action recognition from skeletons, it is unclear how well the current state-of-the-art techniques can perform in a real-world scenario for the recognition of a wide set of heterogeneous gestures, as many benchmarks do not test online recognition and use limited dictionaries. This motivated the proposal of the SHREC 2021: Track on Skeleton-based Hand Gesture Recognition in the Wild. For this contest, we created a novel dataset with heterogeneous gestures featuring different types and duration. These gestures have to be found inside sequences in an online recognition scenario. This paper presents the result of the contest, showing the performances of the techniques proposed by four research groups on the challenging task compared with a simple baseline method.
DeepNAG: Deep Non-Adversarial Gesture Generation
Nov 18, 2020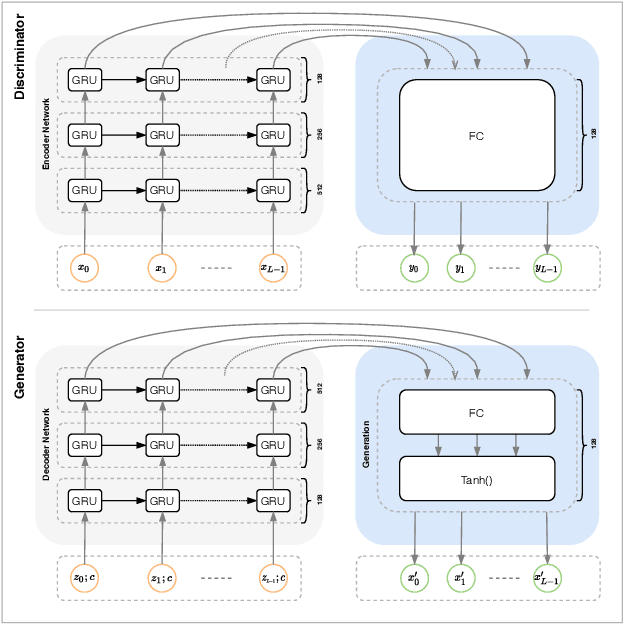
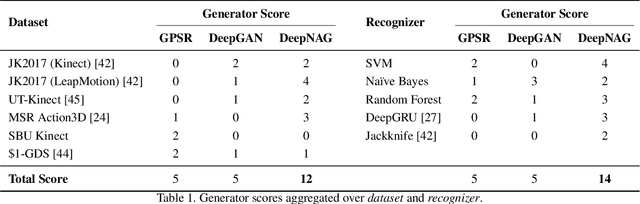
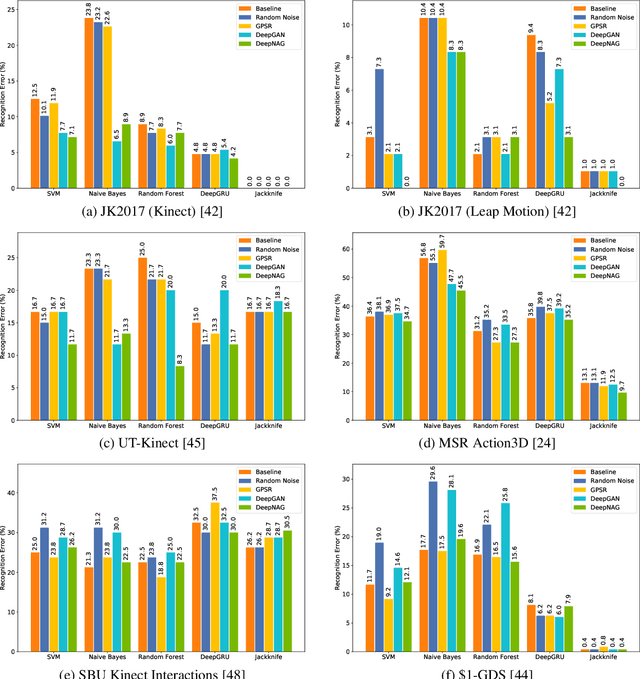

Synthetic data generation to improve classification performance (data augmentation) is a well-studied problem. Recently, generative adversarial networks (GAN) have shown superior image data augmentation performance, but their suitability in gesture synthesis has received inadequate attention. Further, GANs prohibitively require simultaneous generator and discriminator network training. We tackle both issues in this work. We first discuss a novel, device-agnostic GAN model for gesture synthesis called DeepGAN. Thereafter, we formulate DeepNAG by introducing a new differentiable loss function based on dynamic time warping and the average Hausdorff distance, which allows us to train DeepGAN's generator without requiring a discriminator. Through evaluations, we compare the utility of DeepGAN and DeepNAG against two alternative techniques for training five recognizers using data augmentation over six datasets. We further investigate the perceived quality of synthesized samples via an Amazon Mechanical Turk user study based on the HYPE benchmark. We find that DeepNAG outperforms DeepGAN in accuracy, training time (up to 17x faster), and realism, thereby opening the door to a new line of research in generator network design and training for gesture synthesis. Our source code is available at https://www.deepnag.com.
DeepGRU: Deep Gesture Recognition Utility
Oct 30, 2018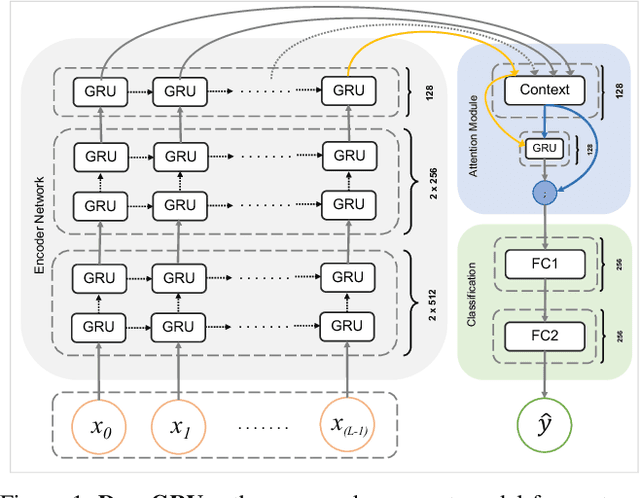
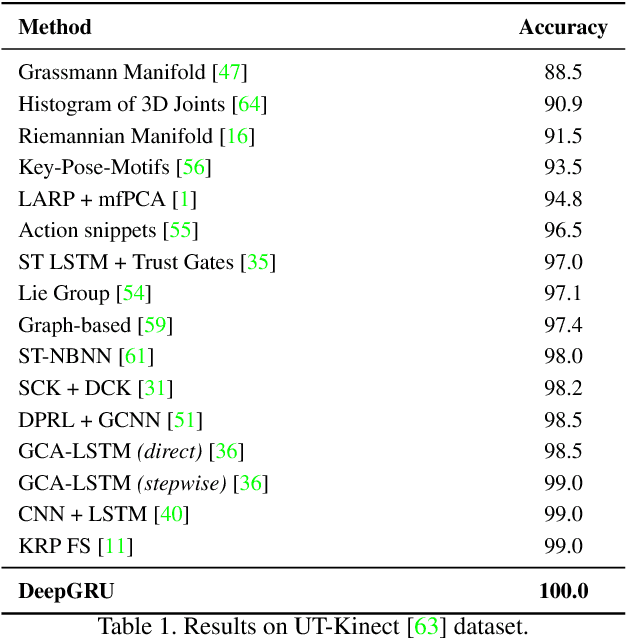
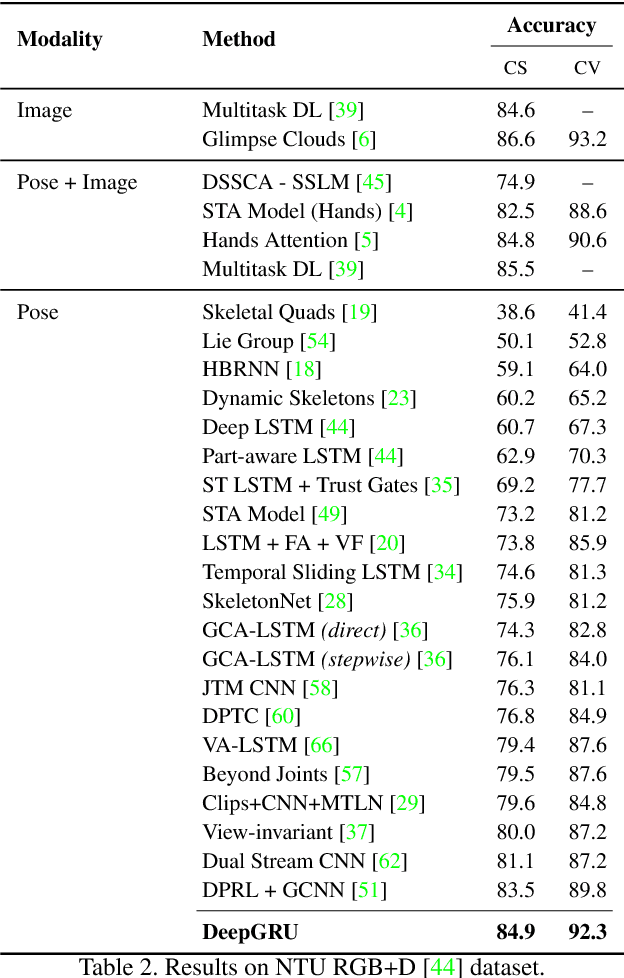

We introduce DeepGRU, a deep learning based gesture and action recognizer. Our method is deceptively simple, yet versatile for various application scenarios. Using only raw pose and vector data, DeepGRU can achieve high recognition accuracy results regardless of the dataset size, the number of training samples or the choice of the input device. At the heart of our method lies a set of stacked GRUs, two fully connected layers and a global attention model. We demonstrate that in the absence of powerful hardware, and using only the CPU, our method can still be trained in a short period of time, making it suitable for rapid prototyping and development scenarios. We evaluate our proposed method on 7 publicly available datasets, spanning over a broad range of interactions as well as dataset sizes. In most cases, we outperform the state-of-the-art pose-based methods. We achieve a recognition accuracy of 84.9% and 92.3% on cross-subject and cross-view tests of the NTU RGB+D dataset respectively, and also 100% recognition accuracy on the UT-Kinect dataset.