 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepGRU: Deep Gesture Recognition Utility
Paper and Code
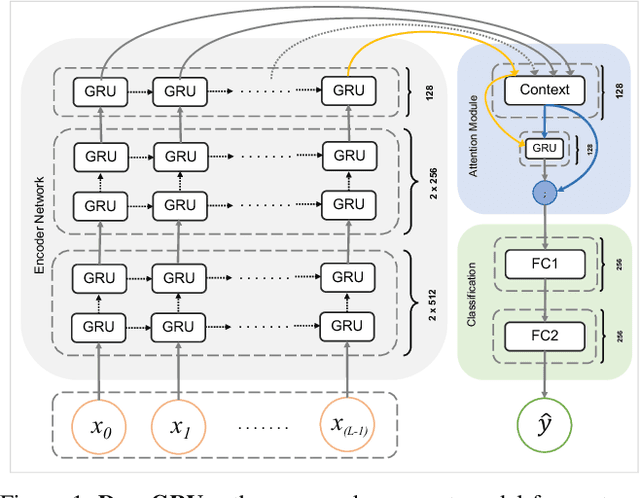
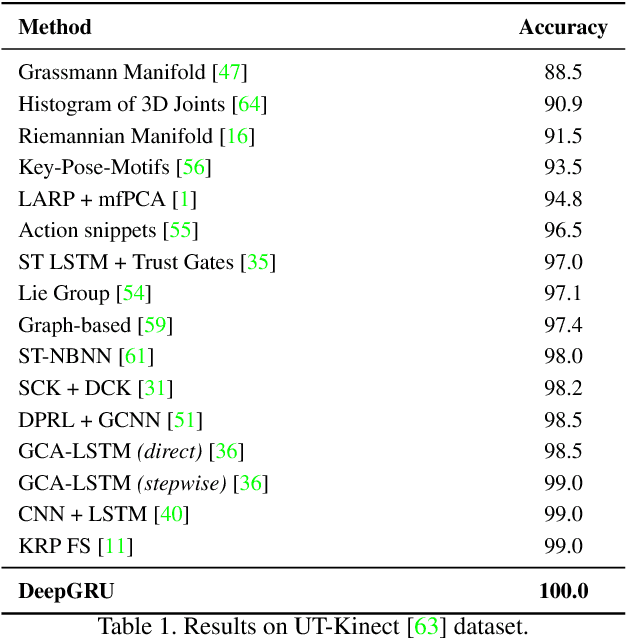
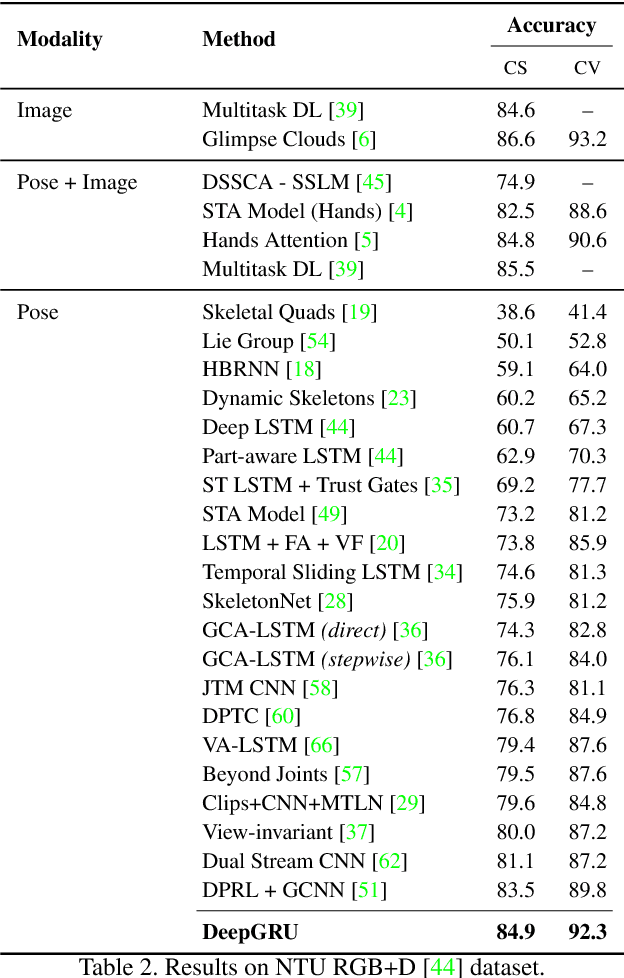

We introduce DeepGRU, a deep learning based gesture and action recognizer. Our method is deceptively simple, yet versatile for various application scenarios. Using only raw pose and vector data, DeepGRU can achieve high recognition accuracy results regardless of the dataset size, the number of training samples or the choice of the input device. At the heart of our method lies a set of stacked GRUs, two fully connected layers and a global attention model. We demonstrate that in the absence of powerful hardware, and using only the CPU, our method can still be trained in a short period of time, making it suitable for rapid prototyping and development scenarios. We evaluate our proposed method on 7 publicly available datasets, spanning over a broad range of interactions as well as dataset sizes. In most cases, we outperform the state-of-the-art pose-based methods. We achieve a recognition accuracy of 84.9% and 92.3% on cross-subject and cross-view tests of the NTU RGB+D dataset respectively, and also 100% recognition accuracy on the UT-Kinect dataset.