 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Aware-Predictive Control Barrier Functions: Safer Human Robot Interaction through Probabilistic Motion Forecasting
Aug 28, 2025To enable flexible, high-throughput automation in settings where people and robots share workspaces, collaborative robotic cells must reconcile stringent safety guarantees with the need for responsive and effective behavior. A dynamic obstacle is the stochastic, task-dependent variability of human motion: when robots fall back on purely reactive or worst-case envelopes, they brake unnecessarily, stall task progress, and tamper with the fluidity that true Human-Robot Interaction demands. In recent years, learning-based human-motion prediction has rapidly advanced, although most approaches produce worst-case scenario forecasts that often do not treat prediction uncertainty in a well-structured way, resulting in over-conservative planning algorithms, limiting their flexibility. We introduce Uncertainty-Aware Predictive Control Barrier Functions (UA-PCBFs), a unified framework that fuses probabilistic human hand motion forecasting with the formal safety guarantees of Control Barrier Functions. In contrast to other variants, our framework allows for dynamic adjustment of the safety margin thanks to the human motion uncertainty estimation provided by a forecasting module. Thanks to uncertainty estimation, UA-PCBFs empower collaborative robots with a deeper understanding of future human states, facilitating more fluid and intelligent interactions through informed motion planning. We validate UA-PCBFs through comprehensive real-world experiments with an increasing level of realism, including automated setups (to perform exactly repeatable motions) with a robotic hand and direct human-robot interactions (to validate promptness, usability, and human confidence). Relative to state-of-the-art HRI architectures, UA-PCBFs show better performance in task-critical metrics, significantly reducing the number of violations of the robot's safe space during interaction with respect to the state-of-the-art.
OO-dMVMT: A Deep Multi-view Multi-task Classification Framework for Real-time 3D Hand Gesture Classification and Segmentation
Apr 12, 2023Continuous mid-air hand gesture recognition based on captured hand pose streams is fundamental for human-computer interaction, particularly in AR / VR. However, many of the methods proposed to recognize heterogeneous hand gestures are tested only on the classification task, and the real-time low-latency gesture segmentation in a continuous stream is not well addressed in the literature. For this task, we propose the On-Off deep Multi-View Multi-Task paradigm (OO-dMVMT). The idea is to exploit multiple time-local views related to hand pose and movement to generate rich gesture descriptions, along with using heterogeneous tasks to achieve high accuracy. OO-dMVMT extends the classical MVMT paradigm, where all of the multiple tasks have to be active at each time, by allowing specific tasks to switch on/off depending on whether they can apply to the input. We show that OO-dMVMT defines the new SotA on continuous/online 3D skeleton-based gesture recognition in terms of gesture classification accuracy, segmentation accuracy, false positives, and decision latency while maintaining real-time operation.
SHREC 2022 Track on Online Detection of Heterogeneous Gestures
Jul 22, 2022

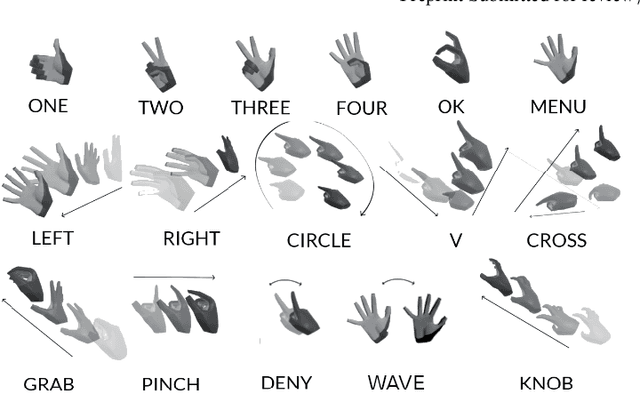
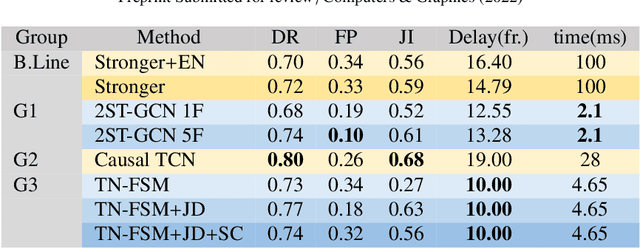
This paper presents the outcomes of a contest organized to evaluate methods for the online recognition of heterogeneous gestures from sequences of 3D hand poses. The task is the detection of gestures belonging to a dictionary of 16 classes characterized by different pose and motion features. The dataset features continuous sequences of hand tracking data where the gestures are interleaved with non-significant motions. The data have been captured using the Hololens 2 finger tracking system in a realistic use-case of mixed reality interaction. The evaluation is based not only on the detection performances but also on the latency and the false positives, making it possible to understand the feasibility of practical interaction tools based on the algorithms proposed. The outcomes of the contest's evaluation demonstrate the necessity of further research to reduce recognition errors, while the computational cost of the algorithms proposed is sufficiently low.
SHREC 2021: Track on Skeleton-based Hand Gesture Recognition in the Wild
Jun 21, 2021
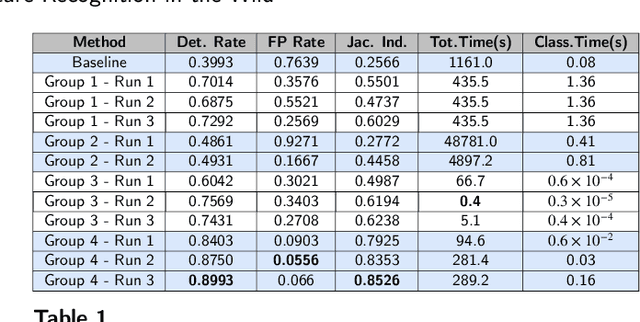

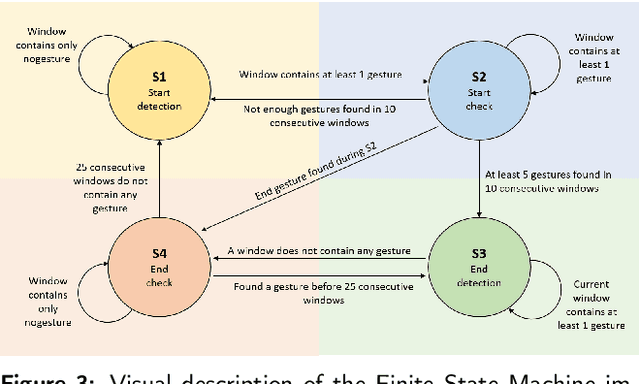
Gesture recognition is a fundamental tool to enable novel interaction paradigms in a variety of application scenarios like Mixed Reality environments, touchless public kiosks, entertainment systems, and more. Recognition of hand gestures can be nowadays performed directly from the stream of hand skeletons estimated by software provided by low-cost trackers (Ultraleap) and MR headsets (Hololens, Oculus Quest) or by video processing software modules (e.g. Google Mediapipe). Despite the recent advancements in gesture and action recognition from skeletons, it is unclear how well the current state-of-the-art techniques can perform in a real-world scenario for the recognition of a wide set of heterogeneous gestures, as many benchmarks do not test online recognition and use limited dictionaries. This motivated the proposal of the SHREC 2021: Track on Skeleton-based Hand Gesture Recognition in the Wild. For this contest, we created a novel dataset with heterogeneous gestures featuring different types and duration. These gestures have to be found inside sequences in an online recognition scenario. This paper presents the result of the contest, showing the performances of the techniques proposed by four research groups on the challenging task compared with a simple baseline method.
Shape retrieval of non-rigid 3d human models
Mar 01, 2020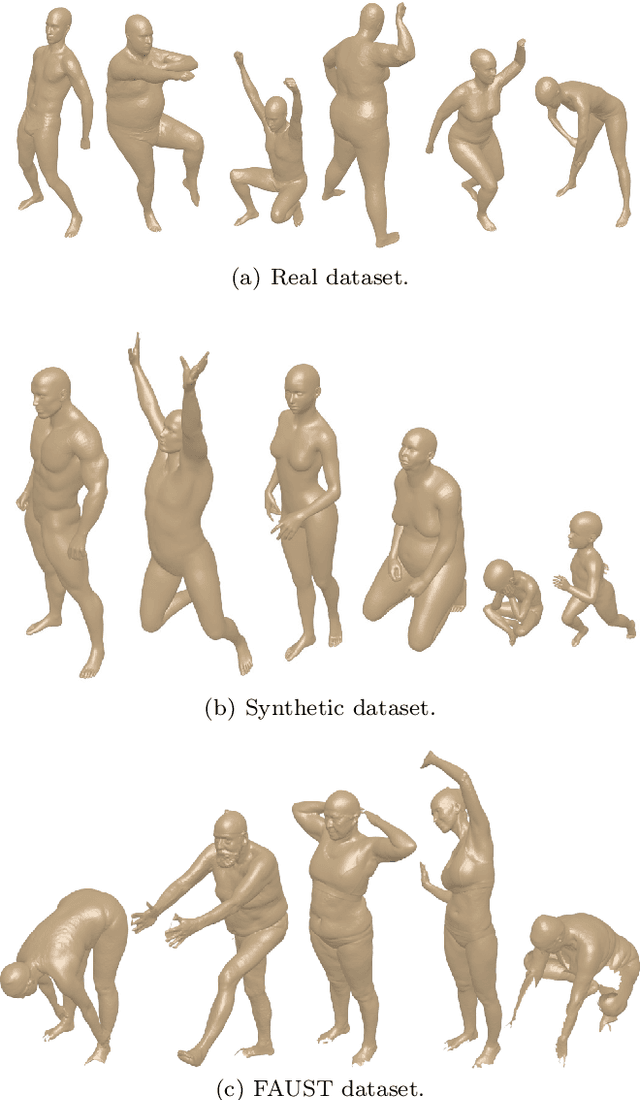
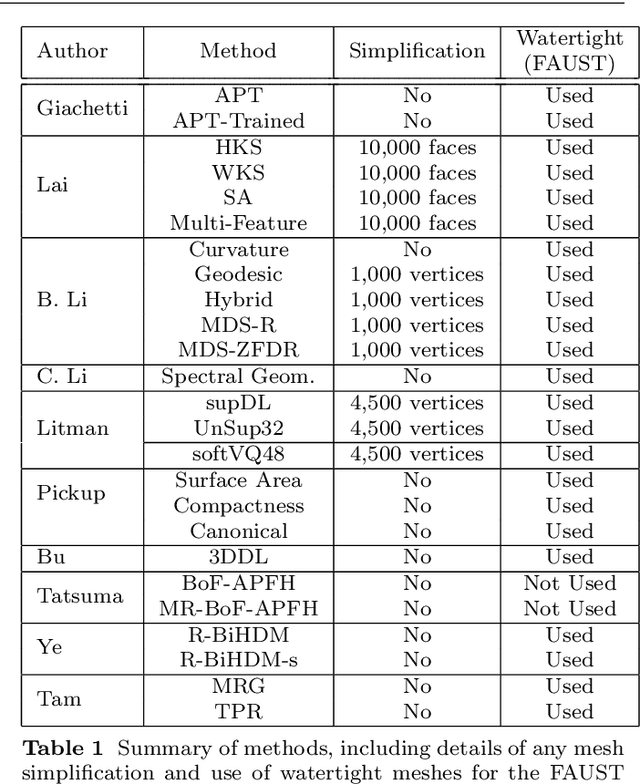
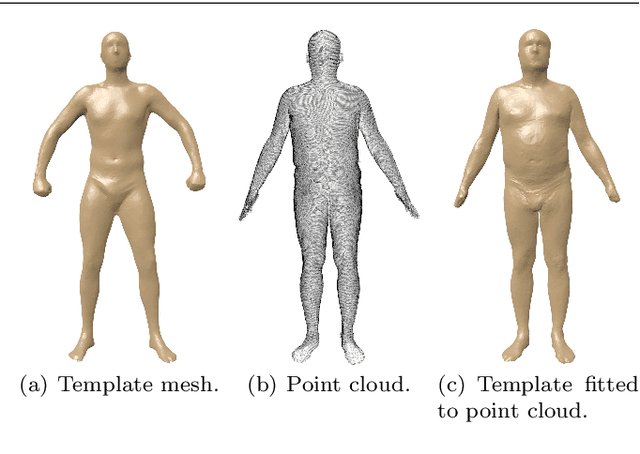
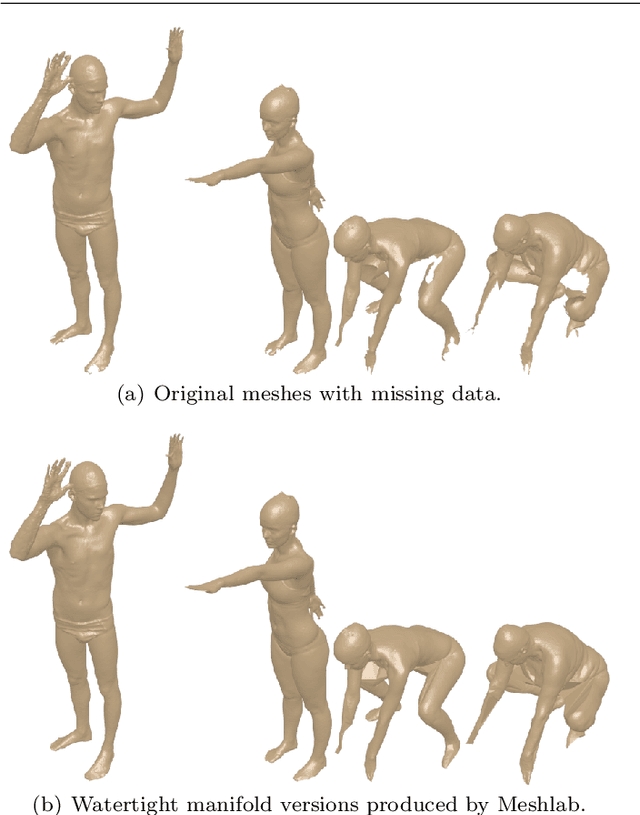
3D models of humans are commonly used within computer graphics and vision, and so the ability to distinguish between body shapes is an important shape retrieval problem. We extend our recent paper which provided a benchmark for testing non-rigid 3D shape retrieval algorithms on 3D human models. This benchmark provided a far stricter challenge than previous shape benchmarks. We have added 145 new models for use as a separate training set, in order to standardise the training data used and provide a fairer comparison. We have also included experiments with the FAUST dataset of human scans. All participants of the previous benchmark study have taken part in the new tests reported here, many providing updated results using the new data. In addition, further participants have also taken part, and we provide extra analysis of the retrieval results. A total of 25 different shape retrieval methods.
Texture Retrieval in the Wild through detection-based attributes
Oct 04, 2019



Capturing the essence of a textile image in a robust way is important to retrieve it in a large repository, especially if it has been acquired in the wild (by taking a photo of the textile of interest). In this paper we show that a texel-based representation fits well with this task. In particular, we refer to Texel-Att, a recent texel-based descriptor which has shown to capture fine grained variations of a texture, for retrieval purposes. After a brief explanation of Texel-Att, we will show in our experiments that this descriptor is robust to distortions resulting from acquisitions in the wild by setting up an experiment in which textures from the ElBa (an Element-Based texture dataset) are artificially distorted and then used to retrieve the original image. We compare our approach with existing descriptors using a simple ranking framework based on distance functions. Results show that even under extreme conditions (such as a down-sampling with a factor of 10), we perform better than alternative approaches.
Texel-Att: Representing and Classifying Element-based Textures by Attributes
Aug 30, 2019


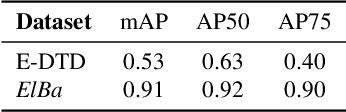
Element-based textures are a kind of texture formed by nameable elements, the texels [1], distributed according to specific statistical distributions; it is of primary importance in many sectors, namely textile, fashion and interior design industry. State-of-theart texture descriptors fail to properly characterize element-based texture, so we present Texel-Att to fill this gap. Texel-Att is the first fine-grained, attribute-based representation and classification framework for element-based textures. It first individuates texels, characterizing them with individual attributes; subsequently, texels are grouped and characterized through layout attributes, which give the Texel-Att representation. Texels are detected by a Mask-RCNN, trained on a brand-new element-based texture dataset, ElBa, containing 30K texture images with 3M fully-annotated texels. Examples of individual and layout attributes are exhibited to give a glimpse on the level of achievable graininess. In the experiments, we present detection results to show that texels can be precisely individuated, even on textures "in the wild"; to this sake, we individuate the element-based classes of the Describable Texture Dataset (DTD), where almost 900K texels have been manually annotated, leading to the Element-based DTD (E-DTD). Subsequently, classification and ranking results demonstrate the expressivity of Texel-Att on ElBa and E-DTD, overcoming the alternative features and relative attributes, doubling the best performance in some cases; finally, we report interactive search results on ElBa and E-DTD: with Texel-Att on the E-DTD dataset we are able to individuate within 10 iterations the desired texture in the 90% of cases, against the 71% obtained with a combination of the finest existing attributes so far. Dataset and code is available at https://github.com/godimarcovr/Texel-Att
SIMCO: SIMilarity-based object COunting
Apr 15, 2019
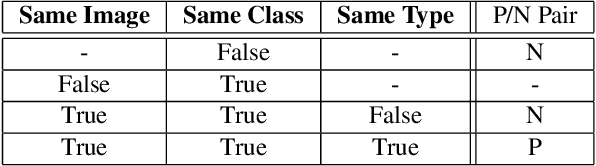
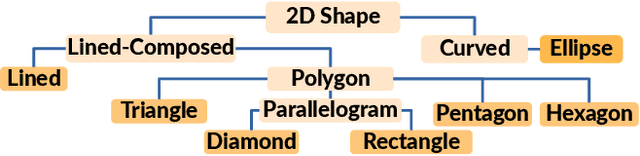
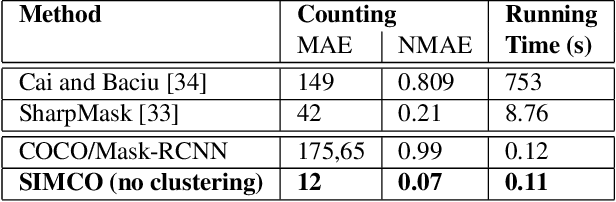
We present SIMCO, the first agnostic multi-class object counting approach. SIMCO starts by detecting foreground objects through a novel Mask RCNN-based architecture trained beforehand (just once) on a brand-new synthetic 2D shape dataset, InShape; the idea is to highlight every object resembling a primitive 2D shape (circle, square, rectangle, etc.). Each object detected is described by a low-dimensional embedding, obtained from a novel similarity-based head branch; this latter implements a triplet loss, encouraging similar objects (same 2D shape + color and scale) to map close. Subsequently, SIMCO uses this embedding for clustering, so that different types of objects can emerge and be counted, making SIMCO the very first multi-class unsupervised counter. Experiments show that SIMCO provides state-of-the-art scores on counting benchmarks and that it can also help in many challenging image understanding tasks.