 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Real-World Autonomous Driving by Learning to Predict and Plan with a Mixture of Experts
Nov 03, 2022The goal of autonomous vehicles is to navigate public roads safely and comfortably. To enforce safety, traditional planning approaches rely on handcrafted rules to generate trajectories. Machine learning-based systems, on the other hand, scale with data and are able to learn more complex behaviors. However, they often ignore that agents and self-driving vehicle trajectory distributions can be leveraged to improve safety. In this paper, we propose modeling a distribution over multiple future trajectories for both the self-driving vehicle and other road agents, using a unified neural network architecture for prediction and planning. During inference, we select the planning trajectory that minimizes a cost taking into account safety and the predicted probabilities. Our approach does not depend on any rule-based planners for trajectory generation or optimization, improves with more training data and is simple to implement. We extensively evaluate our method through a realistic simulator and show that the predicted trajectory distribution corresponds to different driving profiles. We also successfully deploy it on a self-driving vehicle on urban public roads, confirming that it drives safely without compromising comfort. The code for training and testing our model on a public prediction dataset and the video of the road test are available at https://woven.mobi/safepathnet
CW-ERM: Improving Autonomous Driving Planning with Closed-loop Weighted Empirical Risk Minimization
Oct 11, 2022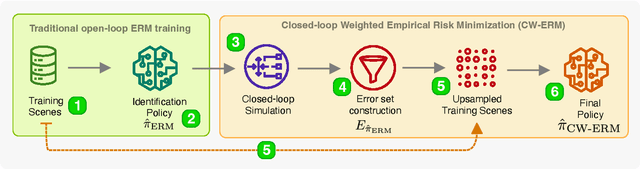
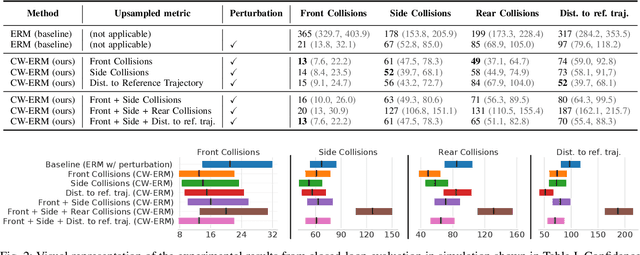
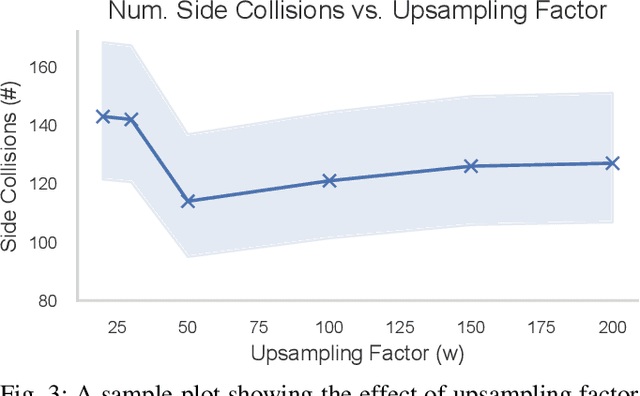
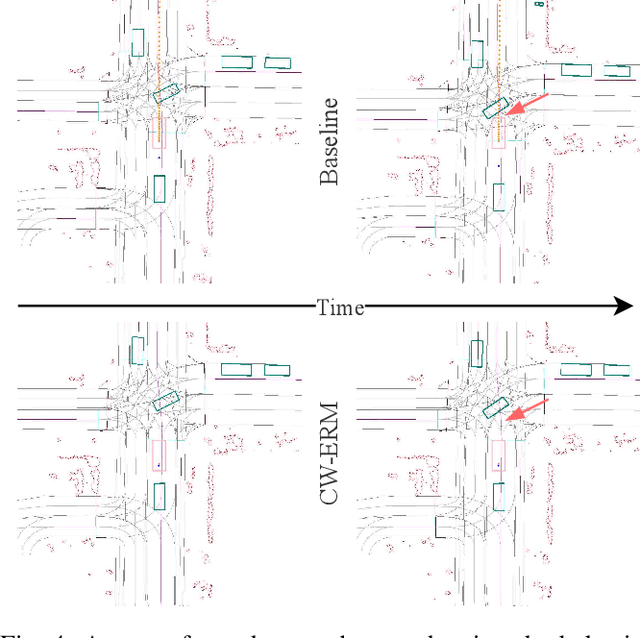
The imitation learning of self-driving vehicle policies through behavioral cloning is often carried out in an open-loop fashion, ignoring the effect of actions to future states. Training such policies purely with Empirical Risk Minimization (ERM) can be detrimental to real-world performance, as it biases policy networks towards matching only open-loop behavior, showing poor results when evaluated in closed-loop. In this work, we develop an efficient and simple-to-implement principle called Closed-loop Weighted Empirical Risk Minimization (CW-ERM), in which a closed-loop evaluation procedure is first used to identify training data samples that are important for practical driving performance and then we these samples to help debias the policy network. We evaluate CW-ERM in a challenging urban driving dataset and show that this procedure yields a significant reduction in collisions as well as other non-differentiable closed-loop metrics.
Semi-Perspective Decoupled Heatmaps for 3D Robot Pose Estimation from Depth Maps
Jul 06, 2022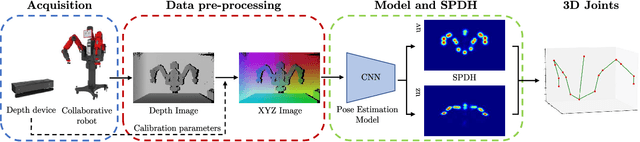
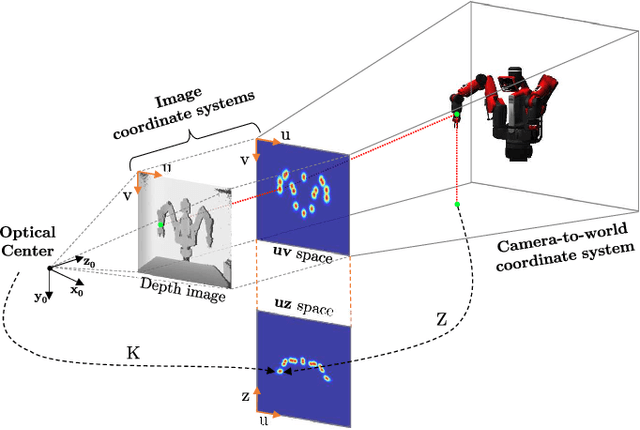
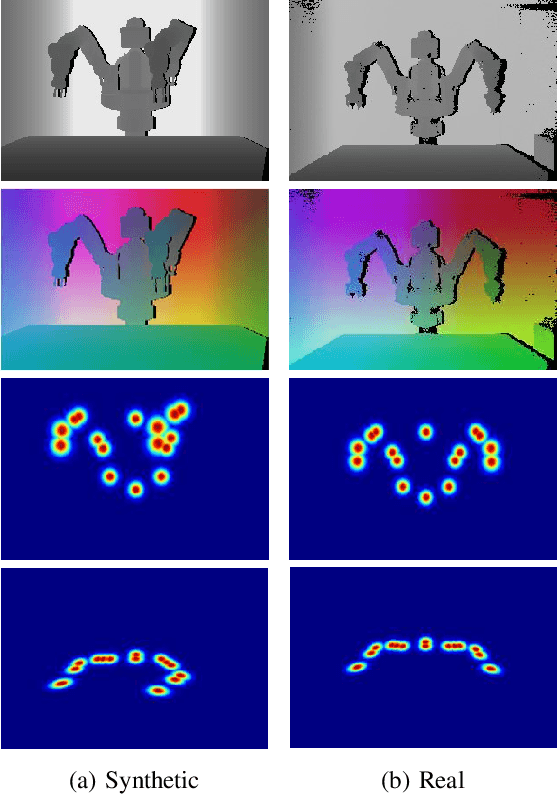

Knowing the exact 3D location of workers and robots in a collaborative environment enables several real applications, such as the detection of unsafe situations or the study of mutual interactions for statistical and social purposes. In this paper, we propose a non-invasive and light-invariant framework based on depth devices and deep neural networks to estimate the 3D pose of robots from an external camera. The method can be applied to any robot without requiring hardware access to the internal states. We introduce a novel representation of the predicted pose, namely Semi-Perspective Decoupled Heatmaps (SPDH), to accurately compute 3D joint locations in world coordinates adapting efficient deep networks designed for the 2D Human Pose Estimation. The proposed approach, which takes as input a depth representation based on XYZ coordinates, can be trained on synthetic depth data and applied to real-world settings without the need for domain adaptation techniques. To this end, we present the SimBa dataset, based on both synthetic and real depth images, and use it for the experimental evaluation. Results show that the proposed approach, made of a specific depth map representation and the SPDH, overcomes the current state of the art.
Multi-Category Mesh Reconstruction From Image Collections
Oct 21, 2021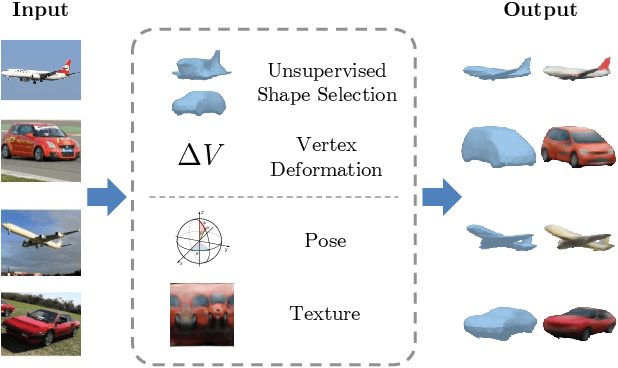
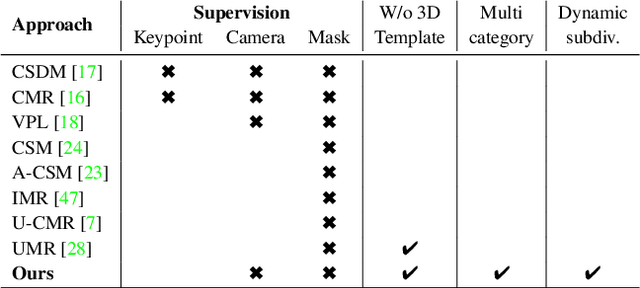

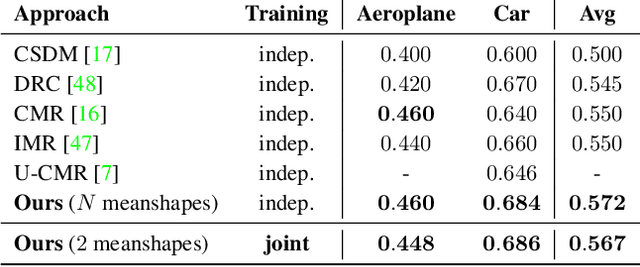
Recently, learning frameworks have shown the capability of inferring the accurate shape, pose, and texture of an object from a single RGB image. However, current methods are trained on image collections of a single category in order to exploit specific priors, and they often make use of category-specific 3D templates. In this paper, we present an alternative approach that infers the textured mesh of objects combining a series of deformable 3D models and a set of instance-specific deformation, pose, and texture. Differently from previous works, our method is trained with images of multiple object categories using only foreground masks and rough camera poses as supervision. Without specific 3D templates, the framework learns category-level models which are deformed to recover the 3D shape of the depicted object. The instance-specific deformations are predicted independently for each vertex of the learned 3D mesh, enabling the dynamic subdivision of the mesh during the training process. Experiments show that the proposed framework can distinguish between different object categories and learn category-specific shape priors in an unsupervised manner. Predicted shapes are smooth and can leverage from multiple steps of subdivision during the training process, obtaining comparable or state-of-the-art results on two public datasets. Models and code are publicly released.
SHREC 2021: Track on Skeleton-based Hand Gesture Recognition in the Wild
Jun 21, 2021
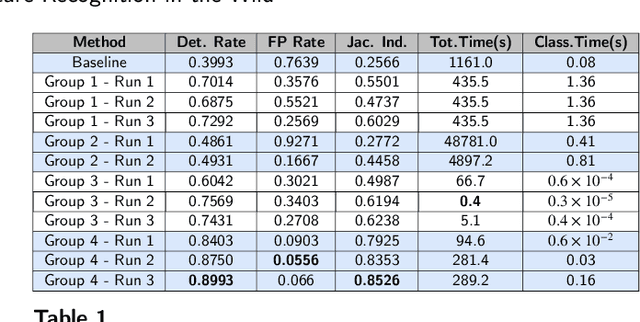

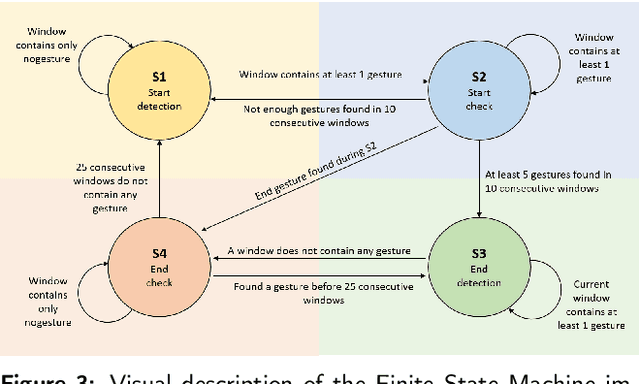
Gesture recognition is a fundamental tool to enable novel interaction paradigms in a variety of application scenarios like Mixed Reality environments, touchless public kiosks, entertainment systems, and more. Recognition of hand gestures can be nowadays performed directly from the stream of hand skeletons estimated by software provided by low-cost trackers (Ultraleap) and MR headsets (Hololens, Oculus Quest) or by video processing software modules (e.g. Google Mediapipe). Despite the recent advancements in gesture and action recognition from skeletons, it is unclear how well the current state-of-the-art techniques can perform in a real-world scenario for the recognition of a wide set of heterogeneous gestures, as many benchmarks do not test online recognition and use limited dictionaries. This motivated the proposal of the SHREC 2021: Track on Skeleton-based Hand Gesture Recognition in the Wild. For this contest, we created a novel dataset with heterogeneous gestures featuring different types and duration. These gestures have to be found inside sequences in an online recognition scenario. This paper presents the result of the contest, showing the performances of the techniques proposed by four research groups on the challenging task compared with a simple baseline method.
M-VAD Names: a Dataset for Video Captioning with Naming
Mar 04, 2019
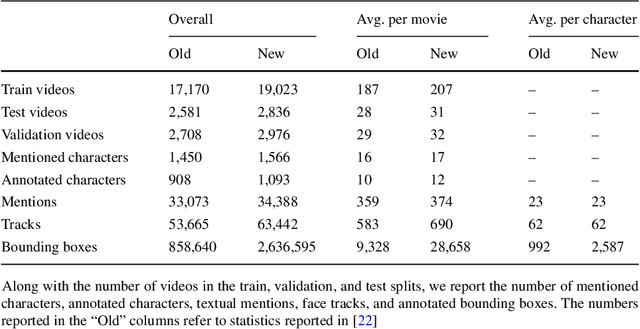
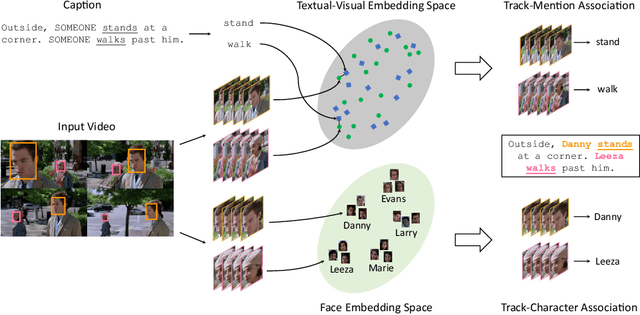
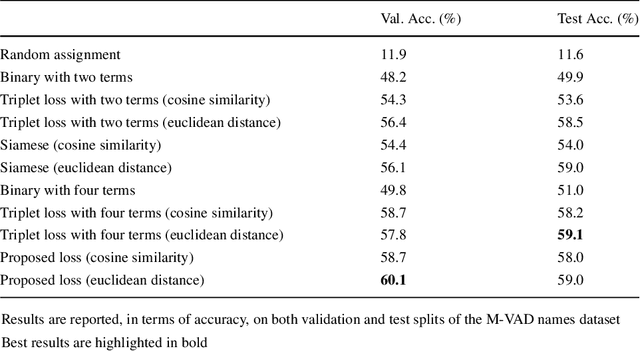
Current movie captioning architectures are not capable of mentioning characters with their proper name, replacing them with a generic "someone" tag. The lack of movie description datasets with characters' visual annotations surely plays a relevant role in this shortage. Recently, we proposed to extend the M-VAD dataset by introducing such information. In this paper, we present an improved version of the dataset, namely M-VAD Names, and its semi-automatic annotation procedure. The resulting dataset contains 63k visual tracks and 34k textual mentions, all associated with character identities. To showcase the features of the dataset and quantify the complexity of the naming task, we investigate multimodal architectures to replace the "someone" tags with proper character names in existing video captions. The evaluation is further extended by testing this application on videos outside of the M-VAD Names dataset.
* Source Code: https://github.com/aimagelab/mvad-names-dataset - Video Demo: https://youtu.be/dOvtAXbOOH4
Learn to See by Events: RGB Frame Synthesis from Event Cameras
Dec 05, 2018
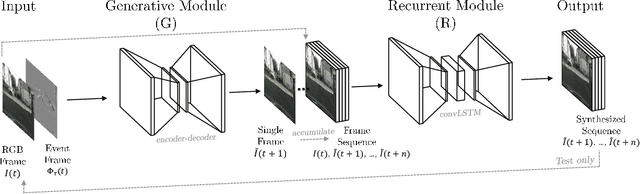
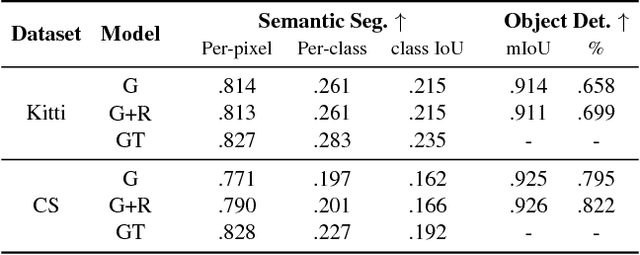

Event cameras are biologically-inspired sensors that gather the temporal evolution of the scene, capturing only pixel-wise brightness variations. Despite having multiple advantages with respect to traditional cameras, their use is still limited due to the difficult intelligibility and restricted usability through traditional vision algorithms. To this aim, we present a framework which exploits the output of event cameras to synthesize RGB frames. In particular, the frame generation relies on an initial or a periodic set of color key-frames and a sequence of intermediate event frames, i.e. gray-level images that integrate the brightness changes captured by the event camera during a short temporal slot. An adversarial architecture combined with a recurrent module is employed for the frame synthesis. Both traditional and event-based datasets are adopted to assess the capabilities of the proposed architecture: pixel-wise and semantic metrics confirm the quality of the synthesized images.
Learning to Generate Facial Depth Maps
May 30, 2018
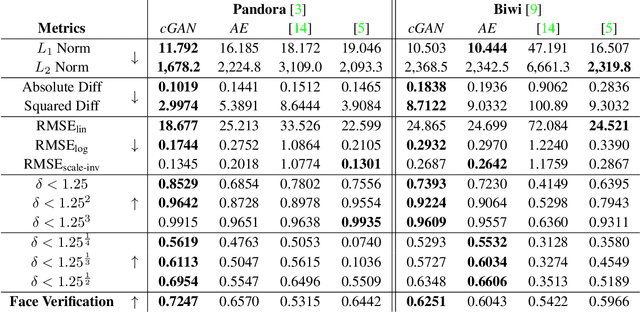
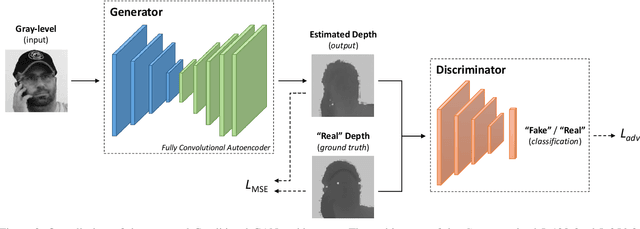

In this paper, an adversarial architecture for facial depth map estimation from monocular intensity images is presented. By following an image-to-image approach, we combine the advantages of supervised learning and adversarial training, proposing a conditional Generative Adversarial Network that effectively learns to translate intensity face images into the corresponding depth maps. Two public datasets, namely Biwi database and Pandora dataset, are exploited to demonstrate that the proposed model generates high-quality synthetic depth images, both in terms of visual appearance and informative content. Furthermore, we show that the model is capable of predicting distinctive facial details by testing the generated depth maps through a deep model trained on authentic depth maps for the face verification task.