 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Real-World Autonomous Driving by Learning to Predict and Plan with a Mixture of Experts
Nov 03, 2022The goal of autonomous vehicles is to navigate public roads safely and comfortably. To enforce safety, traditional planning approaches rely on handcrafted rules to generate trajectories. Machine learning-based systems, on the other hand, scale with data and are able to learn more complex behaviors. However, they often ignore that agents and self-driving vehicle trajectory distributions can be leveraged to improve safety. In this paper, we propose modeling a distribution over multiple future trajectories for both the self-driving vehicle and other road agents, using a unified neural network architecture for prediction and planning. During inference, we select the planning trajectory that minimizes a cost taking into account safety and the predicted probabilities. Our approach does not depend on any rule-based planners for trajectory generation or optimization, improves with more training data and is simple to implement. We extensively evaluate our method through a realistic simulator and show that the predicted trajectory distribution corresponds to different driving profiles. We also successfully deploy it on a self-driving vehicle on urban public roads, confirming that it drives safely without compromising comfort. The code for training and testing our model on a public prediction dataset and the video of the road test are available at https://woven.mobi/safepathnet
Scalable Primitives for Generalized Sensor Fusion in Autonomous Vehicles
Dec 01, 2021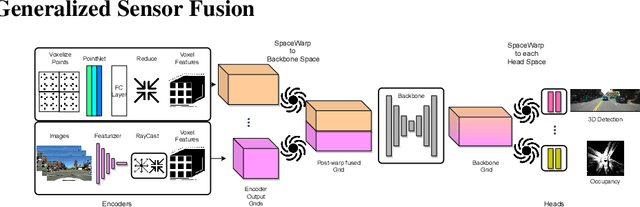
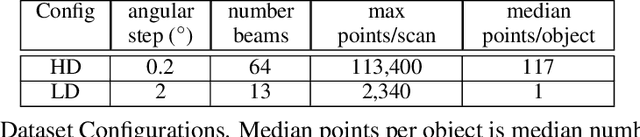
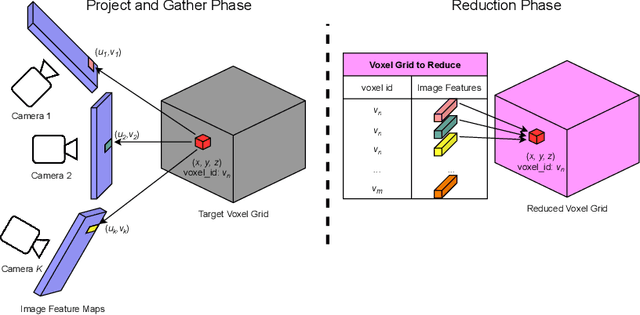

In autonomous driving, there has been an explosion in the use of deep neural networks for perception, prediction and planning tasks. As autonomous vehicles (AVs) move closer to production, multi-modal sensor inputs and heterogeneous vehicle fleets with different sets of sensor platforms are becoming increasingly common in the industry. However, neural network architectures typically target specific sensor platforms and are not robust to changes in input, making the problem of scaling and model deployment particularly difficult. Furthermore, most players still treat the problem of optimizing software and hardware as entirely independent problems. We propose a new end to end architecture, Generalized Sensor Fusion (GSF), which is designed in such a way that both sensor inputs and target tasks are modular and modifiable. This enables AV system designers to easily experiment with different sensor configurations and methods and opens up the ability to deploy on heterogeneous fleets using the same models that are shared across a large engineering organization. Using this system, we report experimental results where we demonstrate near-parity of an expensive high-density (HD) LiDAR sensor with a cheap low-density (LD) LiDAR plus camera setup in the 3D object detection task. This paves the way for the industry to jointly design hardware and software architectures as well as large fleets with heterogeneous configurations.
Autonomous Aerial Cinematography In Unstructured Environments With Learned Artistic Decision-Making
Oct 15, 2019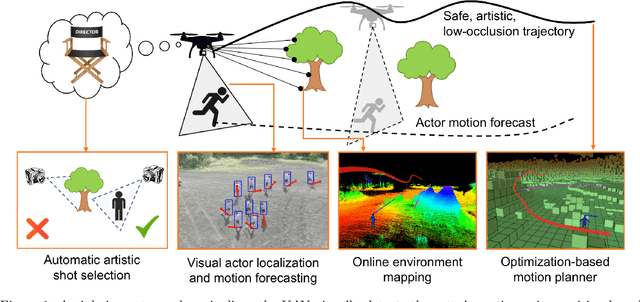
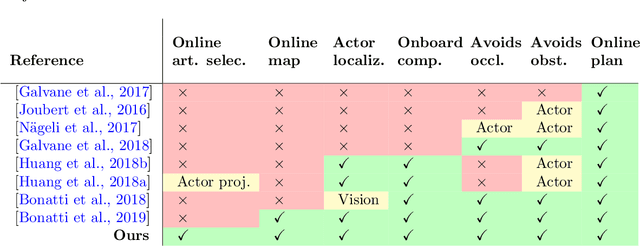
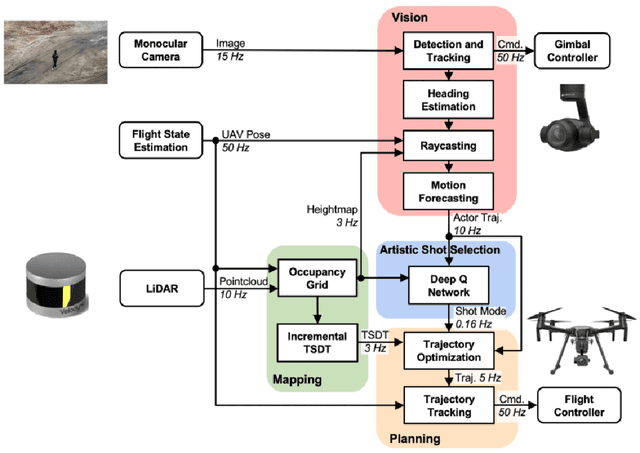

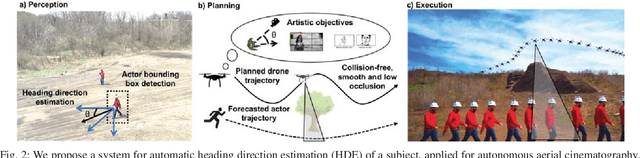
Aerial cinematography is revolutionizing industries that require live and dynamic camera viewpoints such as entertainment, sports, and security. However, safely piloting a drone while filming a moving target in the presence of obstacles is immensely taxing, often requiring multiple expert human operators. Hence, there is demand for an autonomous cinematographer that can reason about both geometry and scene context in real-time. Existing approaches do not address all aspects of this problem; they either require high-precision motion-capture systems or GPS tags to localize targets, rely on prior maps of the environment, plan for short time horizons, or only follow artistic guidelines specified before flight. In this work, we address the problem in its entirety and propose a complete system for real-time aerial cinematography that for the first time combines: (1) vision-based target estimation; (2) 3D signed-distance mapping for occlusion estimation; (3) efficient trajectory optimization for long time-horizon camera motion; and (4) learning-based artistic shot selection. We extensively evaluate our system both in simulation and in field experiments by filming dynamic targets moving through unstructured environments. Our results indicate that our system can operate reliably in the real world without restrictive assumptions. We also provide in-depth analysis and discussions for each module, with the hope that our design tradeoffs can generalize to other related applications. Videos of the complete system can be found at: https://youtu.be/ookhHnqmlaU.
Improved Generalization of Heading Direction Estimation for Aerial Filming Using Semi-supervised Regression
Mar 26, 2019
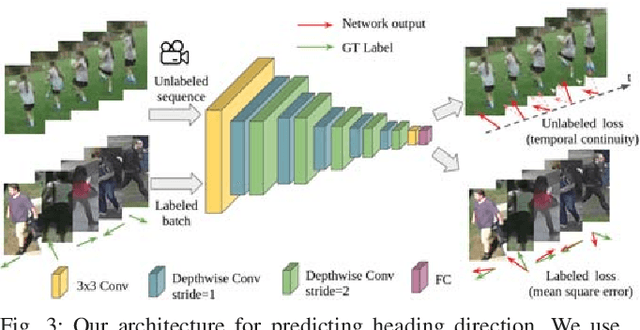

In the task of Autonomous aerial filming of a moving actor (e.g. a person or a vehicle), it is crucial to have a good heading direction estimation for the actor from the visual input. However, the models obtained in other similar tasks, such as pedestrian collision risk analysis and human-robot interaction, are very difficult to generalize to the aerial filming task, because of the difference in data distributions. Towards improving generalization with less amount of labeled data, this paper presents a semi-supervised algorithm for heading direction estimation problem. We utilize temporal continuity as the unsupervised signal to regularize the model and achieve better generalization ability. This semi-supervised algorithm is applied to both training and testing phases, which increases the testing performance by a large margin. We show that by leveraging unlabeled sequences, the amount of labeled data required can be significantly reduced. We also discuss several important details on improving the performance by balancing labeled and unlabeled loss, and making good combinations. Experimental results show that our approach robustly outputs the heading direction for different types of actor. The aesthetic value of the video is also improved in the aerial filming task.