 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Primitives for Generalized Sensor Fusion in Autonomous Vehicles
Dec 01, 2021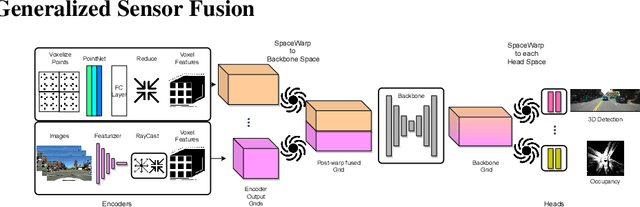
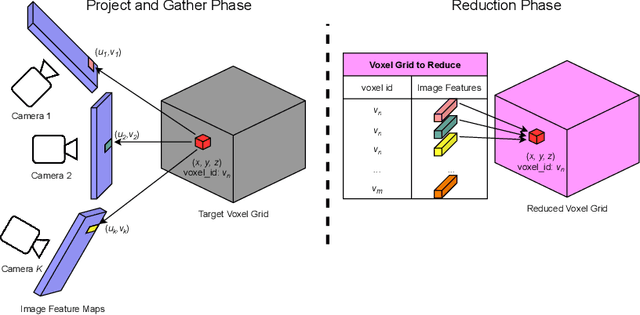

In autonomous driving, there has been an explosion in the use of deep neural networks for perception, prediction and planning tasks. As autonomous vehicles (AVs) move closer to production, multi-modal sensor inputs and heterogeneous vehicle fleets with different sets of sensor platforms are becoming increasingly common in the industry. However, neural network architectures typically target specific sensor platforms and are not robust to changes in input, making the problem of scaling and model deployment particularly difficult. Furthermore, most players still treat the problem of optimizing software and hardware as entirely independent problems. We propose a new end to end architecture, Generalized Sensor Fusion (GSF), which is designed in such a way that both sensor inputs and target tasks are modular and modifiable. This enables AV system designers to easily experiment with different sensor configurations and methods and opens up the ability to deploy on heterogeneous fleets using the same models that are shared across a large engineering organization. Using this system, we report experimental results where we demonstrate near-parity of an expensive high-density (HD) LiDAR sensor with a cheap low-density (LD) LiDAR plus camera setup in the 3D object detection task. This paves the way for the industry to jointly design hardware and software architectures as well as large fleets with heterogeneous configurations.
SqueezeNAS: Fast neural architecture search for faster semantic segmentation
Aug 08, 2019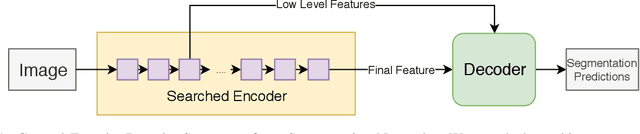
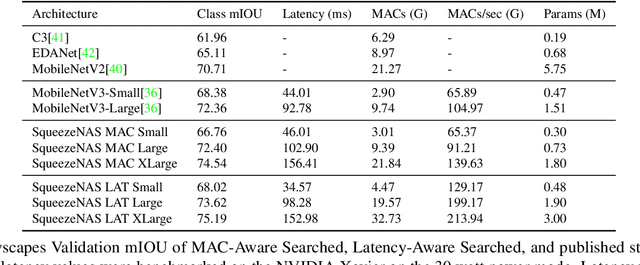
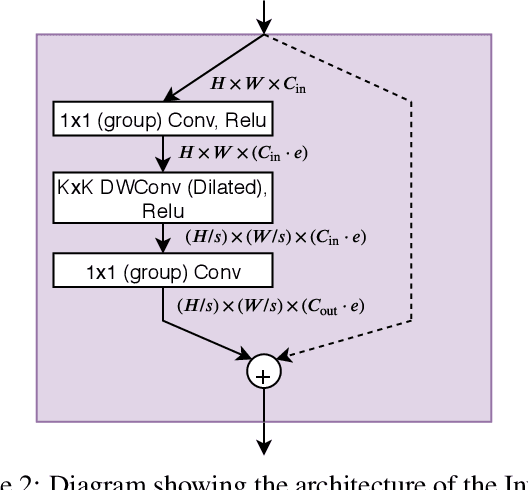
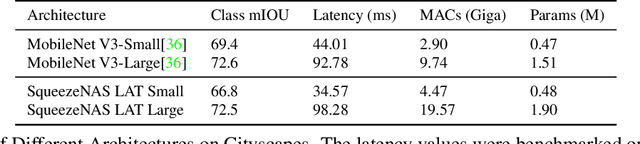
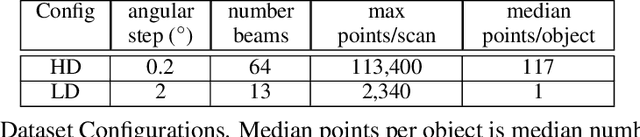
For real time applications utilizing Deep Neural Networks (DNNs), it is critical that the models achieve high-accuracy on the target task and low-latency inference on the target computing platform. While Neural Architecture Search (NAS) has been effectively used to develop low-latency networks for image classification, there has been relatively little effort to use NAS to optimize DNN architectures for other vision tasks. In this work, we present what we believe to be the first proxyless hardware-aware search targeted for dense semantic segmentation. With this approach, we advance the state-of-the-art accuracy for latency-optimized networks on the Cityscapes semantic segmentation dataset. Our latency-optimized small SqueezeNAS network achieves 68.02% validation class mIOU with less than 35 ms inference times on the NVIDIA AGX Xavier. Our latency-optimized large SqueezeNAS network achieves 73.62% class mIOU with less than 100 ms inference times. We demonstrate that significant performance gains are possible by utilizing NAS to find networks optimized for both the specific task and inference hardware. We also present detailed analysis comparing our networks to recent state-of-the-art architectures.
DSCnet: Replicating Lidar Point Clouds with Deep Sensor Cloning
Nov 27, 2018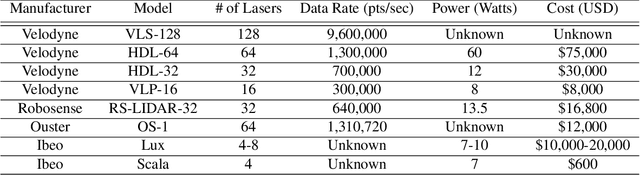
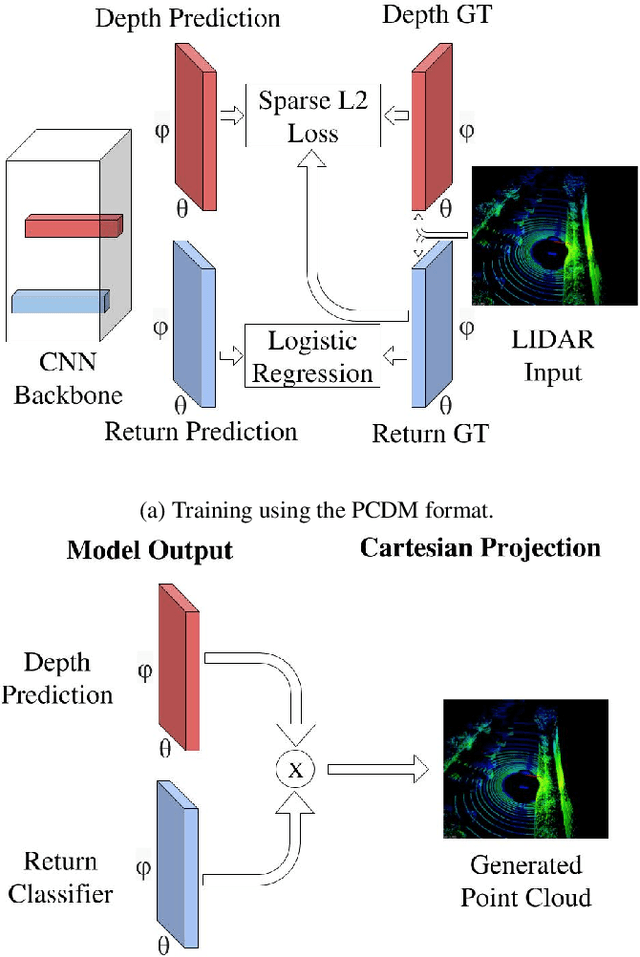


Convolutional neural networks (CNNs) have become increasingly popular for solving a variety of computer vision tasks, ranging from image classification to image segmentation. Recently, autonomous vehicles have created a demand for depth information, which is often obtained using hardware sensors such as Light detection and ranging (LIDAR). Although it can provide precise distance measurements, most LIDARs are still far too expensive to sell in mass-produced consumer vehicles, which has motivated methods to generate depth information from commodity automotive sensors like cameras. In this paper, we propose an approach called Deep Sensor Cloning (DSC). The idea is to use Convolutional Neural Networks in conjunction with inexpensive sensors to replicate the 3D point-clouds that are created by expensive LIDARs. To accomplish this, we develop a new dataset (DSDepth) and a new family of CNN architectures (DSCnets). While previous tasks such as KITTI depth prediction use an interpolated RGB-D images as ground-truth for training, we instead use DSCnets to directly predict LIDAR point-clouds. When we compare the output of our models to a $75,000 LIDAR, we find that our most accurate DSCnet achieves a relative error of 5.77% using a single camera and 4.69% using stereo cameras.