 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Disentangled Prompts for Compositional Image Synthesis
Jun 01, 2023



We study domain-adaptive image synthesis, the problem of teaching pretrained image generative models a new style or concept from as few as one image to synthesize novel images, to better understand the compositional image synthesis. We present a framework that leverages a pretrained class-conditional generation model and visual prompt tuning. Specifically, we propose a novel source class distilled visual prompt that learns disentangled prompts of semantic (e.g., class) and domain (e.g., style) from a few images. Learned domain prompt is then used to synthesize images of any classes in the style of target domain. We conduct studies on various target domains with the number of images ranging from one to a few to many, and show qualitative results which show the compositional generalization of our method. Moreover, we show that our method can help improve zero-shot domain adaptation classification accuracy.
Squeezeformer: An Efficient Transformer for Automatic Speech Recognition
Jun 02, 2022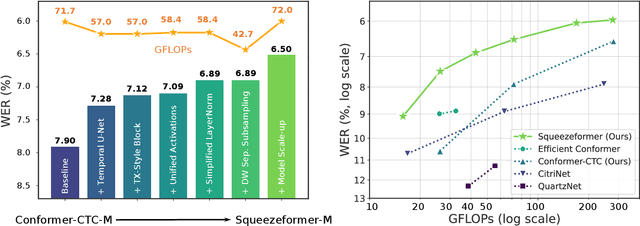
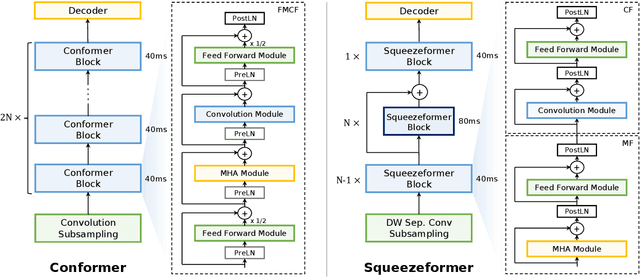
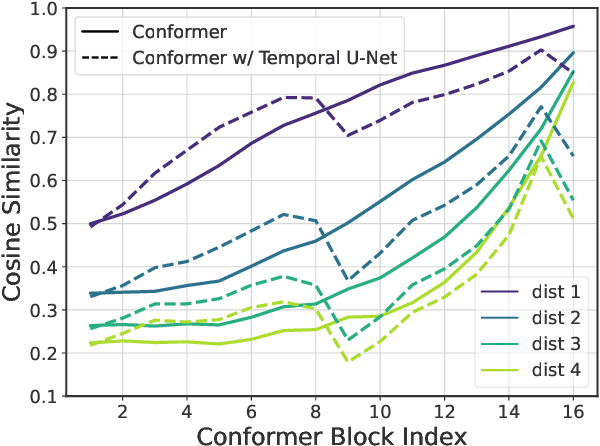
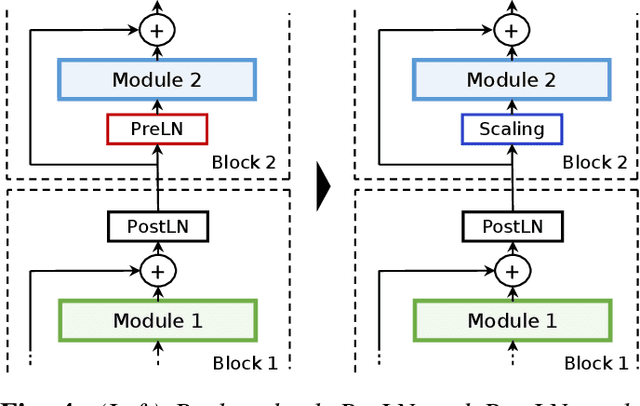
The recently proposed Conformer model has become the de facto backbone model for various downstream speech tasks based on its hybrid attention-convolution architecture that captures both local and global features. However, through a series of systematic studies, we find that the Conformer architecture's design choices are not optimal. After reexamining the design choices for both the macro and micro-architecture of Conformer, we propose the Squeezeformer model, which consistently outperforms the state-of-the-art ASR models under the same training schemes. In particular, for the macro-architecture, Squeezeformer incorporates (i) the Temporal U-Net structure, which reduces the cost of the multi-head attention modules on long sequences, and (ii) a simpler block structure of feed-forward module, followed up by multi-head attention or convolution modules, instead of the Macaron structure proposed in Conformer. Furthermore, for the micro-architecture, Squeezeformer (i) simplifies the activations in the convolutional block, (ii) removes redundant Layer Normalization operations, and (iii) incorporates an efficient depth-wise downsampling layer to efficiently sub-sample the input signal. Squeezeformer achieves state-of-the-art results of 7.5%, 6.5%, and 6.0% word-error-rate on Librispeech test-other without external language models. This is 3.1%, 1.4%, and 0.6% better than Conformer-CTC with the same number of FLOPs. Our code is open-sourced and available online.
SqueezeNAS: Fast neural architecture search for faster semantic segmentation
Aug 08, 2019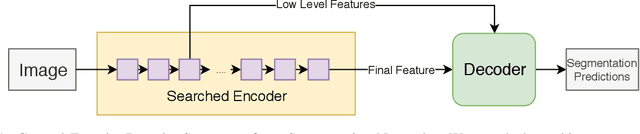
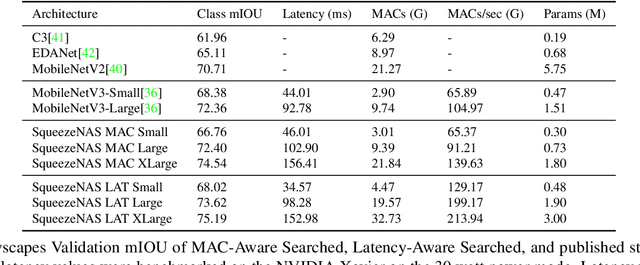
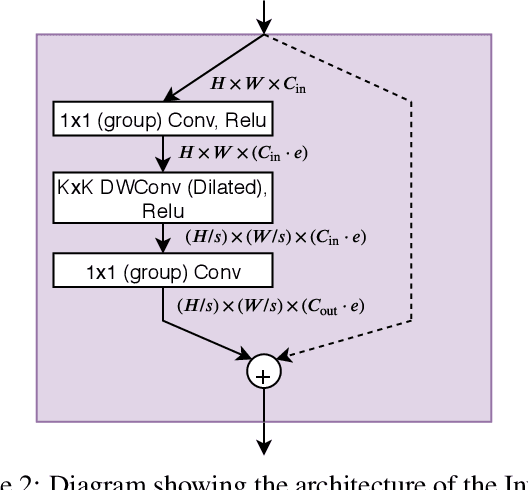
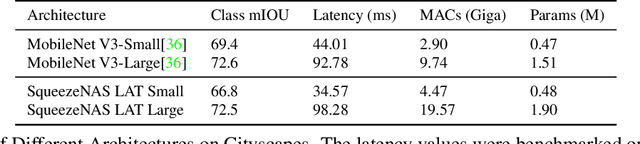
For real time applications utilizing Deep Neural Networks (DNNs), it is critical that the models achieve high-accuracy on the target task and low-latency inference on the target computing platform. While Neural Architecture Search (NAS) has been effectively used to develop low-latency networks for image classification, there has been relatively little effort to use NAS to optimize DNN architectures for other vision tasks. In this work, we present what we believe to be the first proxyless hardware-aware search targeted for dense semantic segmentation. With this approach, we advance the state-of-the-art accuracy for latency-optimized networks on the Cityscapes semantic segmentation dataset. Our latency-optimized small SqueezeNAS network achieves 68.02% validation class mIOU with less than 35 ms inference times on the NVIDIA AGX Xavier. Our latency-optimized large SqueezeNAS network achieves 73.62% class mIOU with less than 100 ms inference times. We demonstrate that significant performance gains are possible by utilizing NAS to find networks optimized for both the specific task and inference hardware. We also present detailed analysis comparing our networks to recent state-of-the-art architectures.
Bayesian Meta-network Architecture Learning
Dec 22, 2018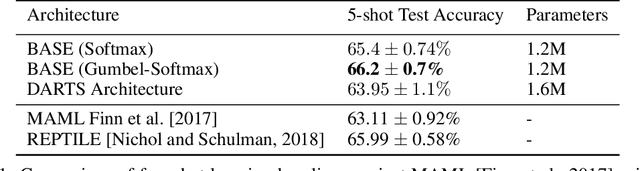
For deep neural networks, the particular structure often plays a vital role in achieving state-of-the-art performances in many practical applications. However, existing architecture search methods can only learn the architecture for a single task at a time. In this paper, we first propose a Bayesian inference view of architecture learning and use this novel view to derive a variational inference method to learn the architecture of a meta-network, which will be shared across multiple tasks. To account for the task distribution in the posterior distribution of the architecture and its corresponding weights, we exploit the optimization embedding technique to design the parameterization of the posterior. Our method finds architectures which achieve state-of-the-art performance on the few-shot learning problem and demonstrates the advantages of meta-network learning for both architecture search and meta-learning.
SBEED: Convergent Reinforcement Learning with Nonlinear Function Approximation
Jun 05, 2018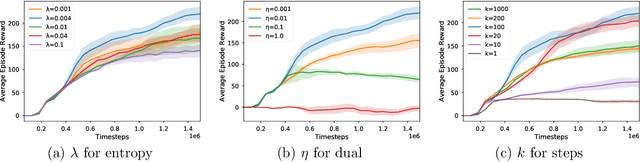
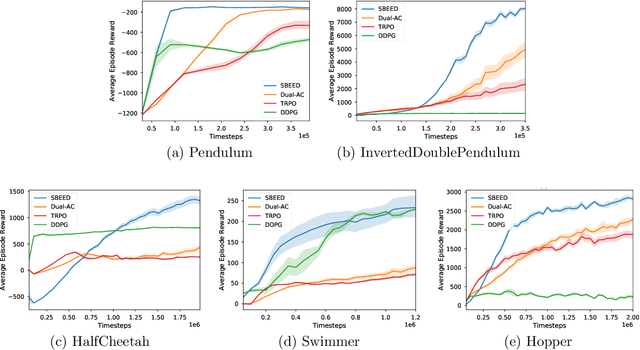
When function approximation is used, solving the Bellman optimality equation with stability guarantees has remained a major open problem in reinforcement learning for decades. The fundamental difficulty is that the Bellman operator may become an expansion in general, resulting in oscillating and even divergent behavior of popular algorithms like Q-learning. In this paper, we revisit the Bellman equation, and reformulate it into a novel primal-dual optimization problem using Nesterov's smoothing technique and the Legendre-Fenchel transformation. We then develop a new algorithm, called Smoothed Bellman Error Embedding, to solve this optimization problem where any differentiable function class may be used. We provide what we believe to be the first convergence guarantee for general nonlinear function approximation, and analyze the algorithm's sample complexity. Empirically, our algorithm compares favorably to state-of-the-art baselines in several benchmark control problems.
Boosting the Actor with Dual Critic
Dec 29, 2017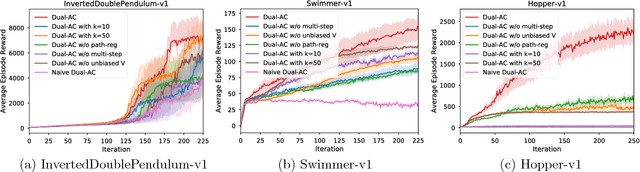
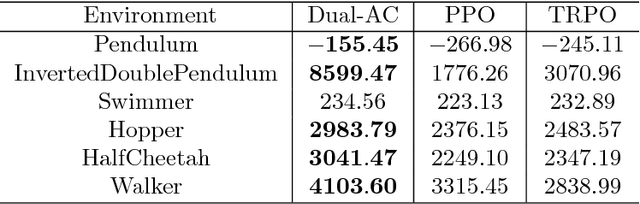
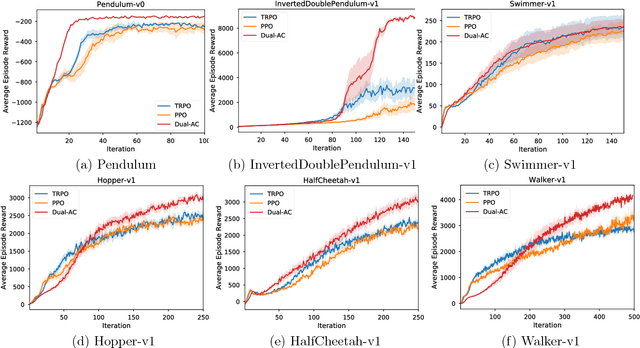
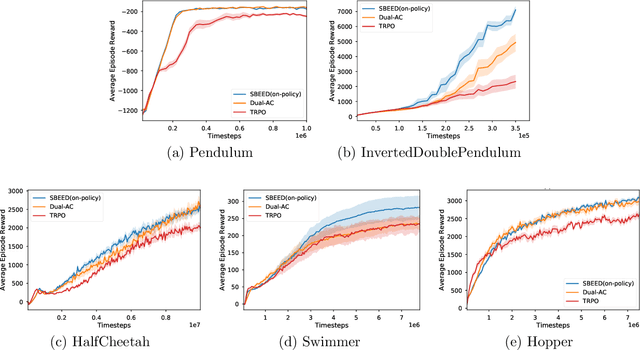
This paper proposes a new actor-critic-style algorithm called Dual Actor-Critic or Dual-AC. It is derived in a principled way from the Lagrangian dual form of the Bellman optimality equation, which can be viewed as a two-player game between the actor and a critic-like function, which is named as dual critic. Compared to its actor-critic relatives, Dual-AC has the desired property that the actor and dual critic are updated cooperatively to optimize the same objective function, providing a more transparent way for learning the critic that is directly related to the objective function of the actor. We then provide a concrete algorithm that can effectively solve the minimax optimization problem, using techniques of multi-step bootstrapping, path regularization, and stochastic dual ascent algorithm. We demonstrate that the proposed algorithm achieves the state-of-the-art performances across several benchmarks.