 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCold-Start Personalization via Training-Free Priors from Structured World Models
Feb 16, 2026Cold-start personalization requires inferring user preferences through interaction when no user-specific historical data is available. The core challenge is a routing problem: each task admits dozens of preference dimensions, yet individual users care about only a few, and which ones matter depends on who is asking. With a limited question budget, asking without structure will miss the dimensions that matter. Reinforcement learning is the natural formulation, but in multi-turn settings its terminal reward fails to exploit the factored, per-criterion structure of preference data, and in practice learned policies collapse to static question sequences that ignore user responses. We propose decomposing cold-start elicitation into offline structure learning and online Bayesian inference. Pep (Preference Elicitation with Priors) learns a structured world model of preference correlations offline from complete profiles, then performs training-free Bayesian inference online to select informative questions and predict complete preference profiles, including dimensions never asked about. The framework is modular across downstream solvers and requires only simple belief models. Across medical, mathematical, social, and commonsense reasoning, Pep achieves 80.8% alignment between generated responses and users' stated preferences versus 68.5% for RL, with 3-5x fewer interactions. When two users give different answers to the same question, Pep changes its follow-up 39-62% of the time versus 0-28% for RL. It does so with ~10K parameters versus 8B for RL, showing that the bottleneck in cold-start elicitation is the capability to exploit the factored structure of preference data.
Smoothing DiLoCo with Primal Averaging for Faster Training of LLMs
Dec 18, 2025



We propose Generalized Primal Averaging (GPA), an extension of Nesterov's method in its primal averaging formulation that addresses key limitations of recent averaging-based optimizers such as single-worker DiLoCo and Schedule-Free (SF) in the non-distributed setting. These two recent algorithmic approaches improve the performance of base optimizers, such as AdamW, through different iterate averaging strategies. Schedule-Free explicitly maintains a uniform average of past weights, while single-worker DiLoCo performs implicit averaging by periodically aggregating trajectories, called pseudo-gradients, to update the model parameters. However, single-worker DiLoCo's periodic averaging introduces a two-loop structure, increasing its memory requirements and number of hyperparameters. GPA overcomes these limitations by decoupling the interpolation constant in the primal averaging formulation of Nesterov. This decoupling enables GPA to smoothly average iterates at every step, generalizing and improving upon single-worker DiLoCo. Empirically, GPA consistently outperforms single-worker DiLoCo while removing the two-loop structure, simplifying hyperparameter tuning, and reducing its memory overhead to a single additional buffer. On the Llama-160M model, GPA provides a 24.22% speedup in terms of steps to reach the baseline (AdamW's) validation loss. Likewise, GPA achieves speedups of 12% and 27% on small and large batch setups, respectively, to attain AdamW's validation accuracy on the ImageNet ViT workload. Furthermore, we prove that for any base optimizer with regret bounded by $O(\sqrt{T})$, where $T$ is the number of iterations, GPA can match or exceed the convergence guarantee of the original optimizer, depending on the choice of interpolation constants.
Bregman Douglas-Rachford Splitting Method
Sep 10, 2025In this paper, we propose the Bregman Douglas-Rachford splitting (BDRS) method and its variant Bregman Peaceman-Rachford splitting method for solving maximal monotone inclusion problem. We show that BDRS is equivalent to a Bregman alternating direction method of multipliers (ADMM) when applied to the dual of the problem. A special case of the Bregman ADMM is an alternating direction version of the exponential multiplier method. To the best of our knowledge, algorithms proposed in this paper are new to the literature. We also discuss how to use our algorithms to solve the discrete optimal transport (OT) problem. We prove the convergence of the algorithms under certain assumptions, though we point out that one assumption does not apply to the OT problem.
LoRe: Personalizing LLMs via Low-Rank Reward Modeling
Apr 20, 2025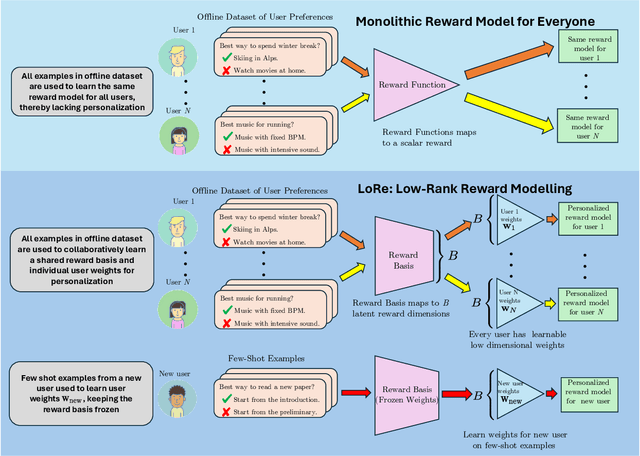
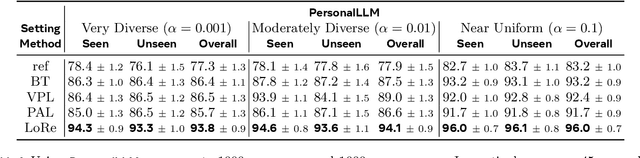
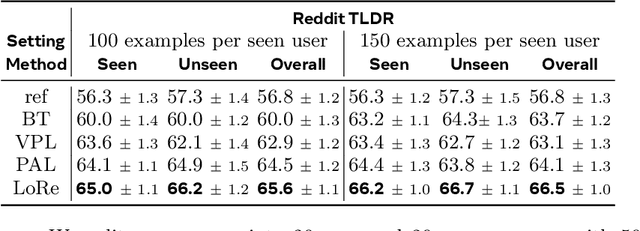
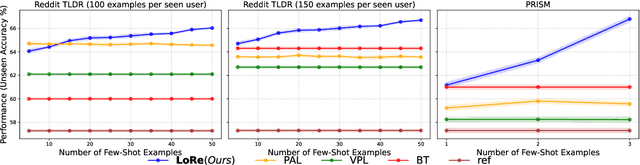
Personalizing large language models (LLMs) to accommodate diverse user preferences is essential for enhancing alignment and user satisfaction. Traditional reinforcement learning from human feedback (RLHF) approaches often rely on monolithic value representations, limiting their ability to adapt to individual preferences. We introduce a novel framework that leverages low-rank preference modeling to efficiently learn and generalize user-specific reward functions. By representing reward functions in a low-dimensional subspace and modeling individual preferences as weighted combinations of shared basis functions, our approach avoids rigid user categorization while enabling scalability and few-shot adaptation. We validate our method on multiple preference datasets, demonstrating superior generalization to unseen users and improved accuracy in preference prediction tasks.
PARQ: Piecewise-Affine Regularized Quantization
Mar 19, 2025



We develop a principled method for quantization-aware training (QAT) of large-scale machine learning models. Specifically, we show that convex, piecewise-affine regularization (PAR) can effectively induce the model parameters to cluster towards discrete values. We minimize PAR-regularized loss functions using an aggregate proximal stochastic gradient method (AProx) and prove that it has last-iterate convergence. Our approach provides an interpretation of the straight-through estimator (STE), a widely used heuristic for QAT, as the asymptotic form of PARQ. We conduct experiments to demonstrate that PARQ obtains competitive performance on convolution- and transformer-based vision tasks.
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization
Feb 04, 2025The optimal bit-width for achieving the best trade-off between quantized model size and accuracy has been a subject of ongoing debate. While some advocate for 4-bit quantization, others propose that 1.58-bit offers superior results. However, the lack of a cohesive framework for different bits has left such conclusions relatively tenuous. We present ParetoQ, the first unified framework that facilitates rigorous comparisons across 1-bit, 1.58-bit, 2-bit, 3-bit, and 4-bit quantization settings. Our findings reveal a notable learning transition between 2 and 3 bits: For 3-bits and above, the fine-tuned models stay close to their original pre-trained distributions, whereas for learning 2-bit networks or below, the representations change drastically. By optimizing training schemes and refining quantization functions, ParetoQ surpasses all previous methods tailored to specific bit widths. Remarkably, our ParetoQ ternary 600M-parameter model even outperforms the previous SoTA ternary 3B-parameter model in accuracy, using only one-fifth of the parameters. Extensive experimentation shows that ternary, 2-bit, and 3-bit quantization maintains comparable performance in the size-accuracy trade-off and generally exceeds 4-bit and binary quantization. Considering hardware constraints, 2-bit quantization offers promising potential for memory reduction and speedup.
SHYI: Action Support for Contrastive Learning in High-Fidelity Text-to-Image Generation
Jan 15, 2025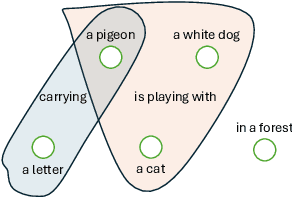

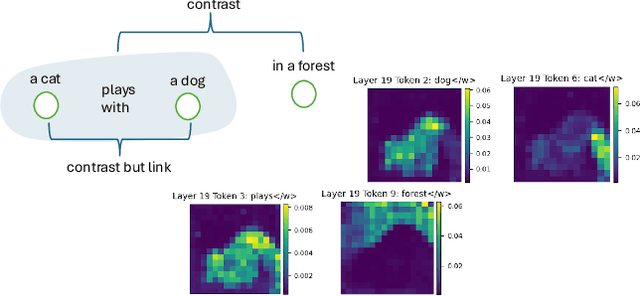

In this project, we address the issue of infidelity in text-to-image generation, particularly for actions involving multiple objects. For this we build on top of the CONFORM framework which uses Contrastive Learning to improve the accuracy of the generated image for multiple objects. However the depiction of actions which involves multiple different object has still large room for improvement. To improve, we employ semantically hypergraphic contrastive adjacency learning, a comprehension of enhanced contrastive structure and "contrast but link" technique. We further amend Stable Diffusion's understanding of actions by InteractDiffusion. As evaluation metrics we use image-text similarity CLIP and TIFA. In addition, we conducted a user study. Our method shows promising results even with verbs that Stable Diffusion understands mediocrely. We then provide future directions by analyzing the results. Our codebase can be found on polybox under the link: https://polybox.ethz.ch/index.php/s/dJm3SWyRohUrFxn
Multimodal Graph Neural Network for Recommendation with Dynamic De-redundancy and Modality-Guided Feature De-noisy
Nov 03, 2024



Graph neural networks (GNNs) have become crucial in multimodal recommendation tasks because of their powerful ability to capture complex relationships between neighboring nodes. However, increasing the number of propagation layers in GNNs can lead to feature redundancy, which may negatively impact the overall recommendation performance. In addition, the existing recommendation task method directly maps the preprocessed multimodal features to the low-dimensional space, which will bring the noise unrelated to user preference, thus affecting the representation ability of the model. To tackle the aforementioned challenges, we propose Multimodal Graph Neural Network for Recommendation (MGNM) with Dynamic De-redundancy and Modality-Guided Feature De-noisy, which is divided into local and global interaction. Initially, in the local interaction process,we integrate a dynamic de-redundancy (DDR) loss function which is achieved by utilizing the product of the feature coefficient matrix and the feature matrix as a penalization factor. It reduces the feature redundancy effects of multimodal and behavioral features caused by the stacking of multiple GNN layers. Subsequently, in the global interaction process, we developed modality-guided global feature purifiers for each modality to alleviate the impact of modality noise. It is a two-fold guiding mechanism eliminating modality features that are irrelevant to user preferences and captures complex relationships within the modality. Experimental results demonstrate that MGNM achieves superior performance on multimodal information denoising and removal of redundant information compared to the state-of-the-art methods.
Dual Approximation Policy Optimization
Oct 02, 2024



We propose Dual Approximation Policy Optimization (DAPO), a framework that incorporates general function approximation into policy mirror descent methods. In contrast to the popular approach of using the $L_2$-norm to measure function approximation errors, DAPO uses the dual Bregman divergence induced by the mirror map for policy projection. This duality framework has both theoretical and practical implications: not only does it achieve fast linear convergence with general function approximation, but it also includes several well-known practical methods as special cases, immediately providing strong convergence guarantees.
An Adaptive Stochastic Gradient Method with Non-negative Gauss-Newton Stepsizes
Jul 05, 2024We consider the problem of minimizing the average of a large number of smooth but possibly non-convex functions. In the context of most machine learning applications, each loss function is non-negative and thus can be expressed as the composition of a square and its real-valued square root. This reformulation allows us to apply the Gauss-Newton method, or the Levenberg-Marquardt method when adding a quadratic regularization. The resulting algorithm, while being computationally as efficient as the vanilla stochastic gradient method, is highly adaptive and can automatically warmup and decay the effective stepsize while tracking the non-negative loss landscape. We provide a tight convergence analysis, leveraging new techniques, in the stochastic convex and non-convex settings. In particular, in the convex case, the method does not require access to the gradient Lipshitz constant for convergence, and is guaranteed to never diverge. The convergence rates and empirical evaluations compare favorably to the classical (stochastic) gradient method as well as to several other adaptive methods.