 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization
Feb 04, 2025The optimal bit-width for achieving the best trade-off between quantized model size and accuracy has been a subject of ongoing debate. While some advocate for 4-bit quantization, others propose that 1.58-bit offers superior results. However, the lack of a cohesive framework for different bits has left such conclusions relatively tenuous. We present ParetoQ, the first unified framework that facilitates rigorous comparisons across 1-bit, 1.58-bit, 2-bit, 3-bit, and 4-bit quantization settings. Our findings reveal a notable learning transition between 2 and 3 bits: For 3-bits and above, the fine-tuned models stay close to their original pre-trained distributions, whereas for learning 2-bit networks or below, the representations change drastically. By optimizing training schemes and refining quantization functions, ParetoQ surpasses all previous methods tailored to specific bit widths. Remarkably, our ParetoQ ternary 600M-parameter model even outperforms the previous SoTA ternary 3B-parameter model in accuracy, using only one-fifth of the parameters. Extensive experimentation shows that ternary, 2-bit, and 3-bit quantization maintains comparable performance in the size-accuracy trade-off and generally exceeds 4-bit and binary quantization. Considering hardware constraints, 2-bit quantization offers promising potential for memory reduction and speedup.
Using Machine Translation to Localize Task Oriented NLG Output
Jul 09, 2021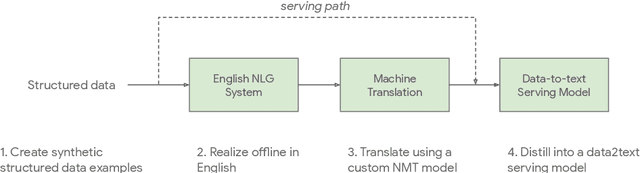
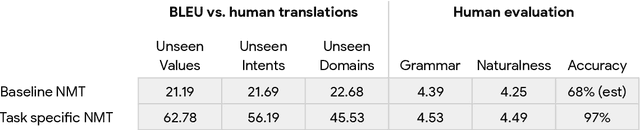
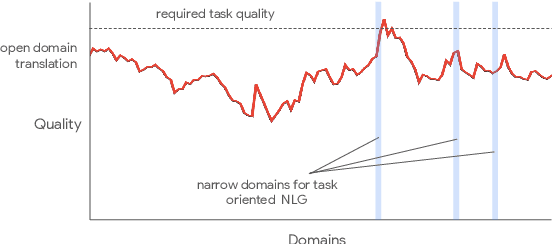
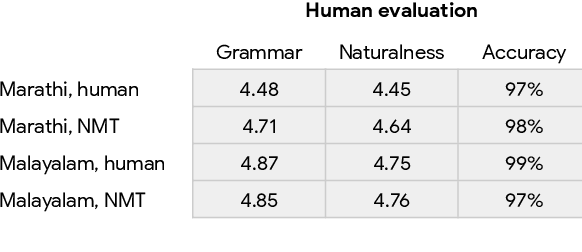
One of the challenges in a task oriented natural language application like the Google Assistant, Siri, or Alexa is to localize the output to many languages. This paper explores doing this by applying machine translation to the English output. Using machine translation is very scalable, as it can work with any English output and can handle dynamic text, but otherwise the problem is a poor fit. The required quality bar is close to perfection, the range of sentences is extremely narrow, and the sentences are often very different than the ones in the machine translation training data. This combination of requirements is novel in the field of domain adaptation for machine translation. We are able to reach the required quality bar by building on existing ideas and adding new ones: finetuning on in-domain translations, adding sentences from the Web, adding semantic annotations, and using automatic error detection. The paper shares our approach and results, together with a distillation model to serve the translation models at scale.
Machine Translation Pre-training for Data-to-Text Generation -- A Case Study in Czech
Apr 05, 2020
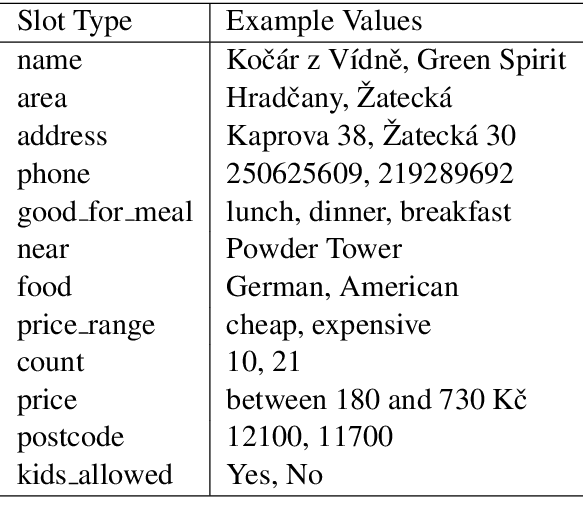

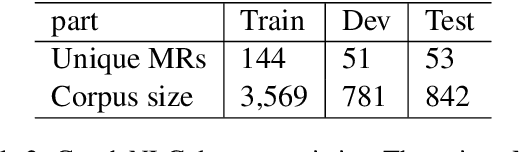
While there is a large body of research studying deep learning methods for text generation from structured data, almost all of it focuses purely on English. In this paper, we study the effectiveness of machine translation based pre-training for data-to-text generation in non-English languages. Since the structured data is generally expressed in English, text generation into other languages involves elements of translation, transliteration and copying - elements already encoded in neural machine translation systems. Moreover, since data-to-text corpora are typically small, this task can benefit greatly from pre-training. Based on our experiments on Czech, a morphologically complex language, we find that pre-training lets us train end-to-end models with significantly improved performance, as judged by automatic metrics and human evaluation. We also show that this approach enjoys several desirable properties, including improved performance in low data scenarios and robustness to unseen slot values.
Text Repair Model for Neural Machine Translation
Apr 09, 2019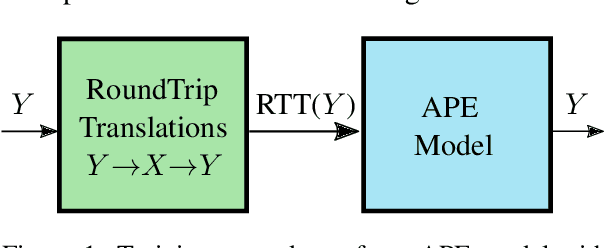
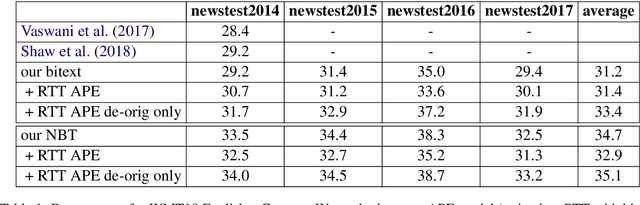
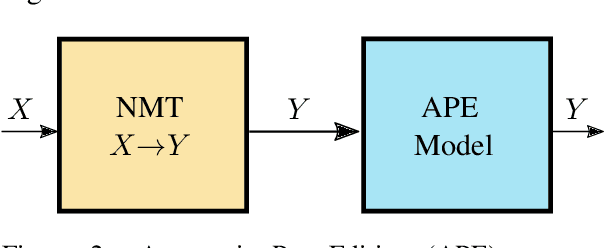
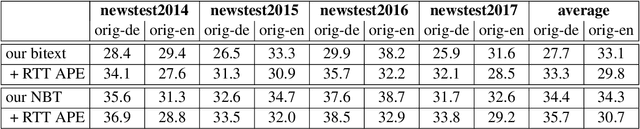
In this work, we train a text repair model as a post-processor for Neural Machine Translation (NMT). The goal of the repair model is to correct typical errors introduced by the translation process, and convert the "translationese" output into natural text. The repair model is trained on monolingual data that has been round-trip translated through English, to mimic errors that are similar to the ones introduced by NMT. Having a trained repair model, we apply it to the output of existing NMT systems. We run experiments for both the WMT18 English to German and the WMT16 English to Romanian task. Furthermore, we apply the repair model on the output of the top submissions of the most recent WMT evaluation campaigns. We see quality improvements on all tasks of up to 2.5 BLEU points.
Unsupervised Natural Language Generation with Denoising Autoencoders
Aug 24, 2018

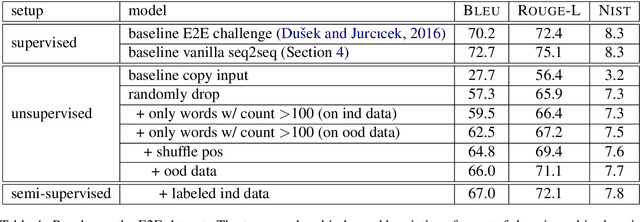
Generating text from structured data is important for various tasks such as question answering and dialog systems. We show that in at least one domain, without any supervision and only based on unlabeled text, we are able to build a Natural Language Generation (NLG) system with higher performance than supervised approaches. In our approach, we interpret the structured data as a corrupt representation of the desired output and use a denoising auto-encoder to reconstruct the sentence. We show how to introduce noise into training examples that do not contain structured data, and that the resulting denoising auto-encoder generalizes to generate correct sentences when given structured data.
Contextual LSTM models for Large scale NLP tasks
May 31, 2016
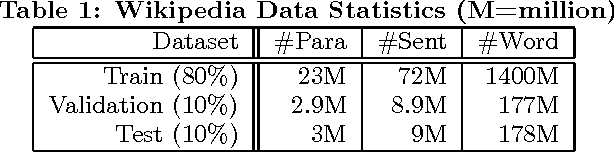
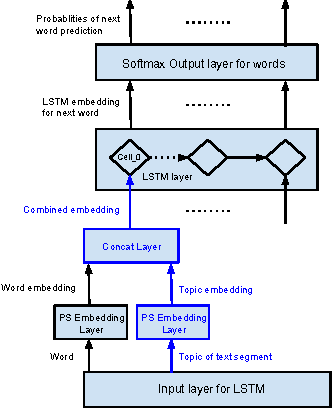
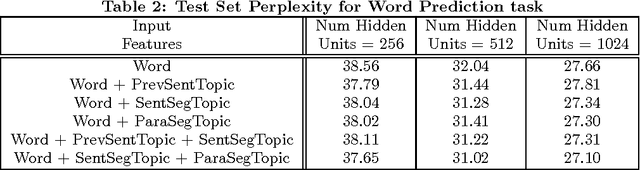
Documents exhibit sequential structure at multiple levels of abstraction (e.g., sentences, paragraphs, sections). These abstractions constitute a natural hierarchy for representing the context in which to infer the meaning of words and larger fragments of text. In this paper, we present CLSTM (Contextual LSTM), an extension of the recurrent neural network LSTM (Long-Short Term Memory) model, where we incorporate contextual features (e.g., topics) into the model. We evaluate CLSTM on three specific NLP tasks: word prediction, next sentence selection, and sentence topic prediction. Results from experiments run on two corpora, English documents in Wikipedia and a subset of articles from a recent snapshot of English Google News, indicate that using both words and topics as features improves performance of the CLSTM models over baseline LSTM models for these tasks. For example on the next sentence selection task, we get relative accuracy improvements of 21% for the Wikipedia dataset and 18% for the Google News dataset. This clearly demonstrates the significant benefit of using context appropriately in natural language (NL) tasks. This has implications for a wide variety of NL applications like question answering, sentence completion, paraphrase generation, and next utterance prediction in dialog systems.