 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARQ: Piecewise-Affine Regularized Quantization
Mar 19, 2025



We develop a principled method for quantization-aware training (QAT) of large-scale machine learning models. Specifically, we show that convex, piecewise-affine regularization (PAR) can effectively induce the model parameters to cluster towards discrete values. We minimize PAR-regularized loss functions using an aggregate proximal stochastic gradient method (AProx) and prove that it has last-iterate convergence. Our approach provides an interpretation of the straight-through estimator (STE), a widely used heuristic for QAT, as the asymptotic form of PARQ. We conduct experiments to demonstrate that PARQ obtains competitive performance on convolution- and transformer-based vision tasks.
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization
Feb 04, 2025The optimal bit-width for achieving the best trade-off between quantized model size and accuracy has been a subject of ongoing debate. While some advocate for 4-bit quantization, others propose that 1.58-bit offers superior results. However, the lack of a cohesive framework for different bits has left such conclusions relatively tenuous. We present ParetoQ, the first unified framework that facilitates rigorous comparisons across 1-bit, 1.58-bit, 2-bit, 3-bit, and 4-bit quantization settings. Our findings reveal a notable learning transition between 2 and 3 bits: For 3-bits and above, the fine-tuned models stay close to their original pre-trained distributions, whereas for learning 2-bit networks or below, the representations change drastically. By optimizing training schemes and refining quantization functions, ParetoQ surpasses all previous methods tailored to specific bit widths. Remarkably, our ParetoQ ternary 600M-parameter model even outperforms the previous SoTA ternary 3B-parameter model in accuracy, using only one-fifth of the parameters. Extensive experimentation shows that ternary, 2-bit, and 3-bit quantization maintains comparable performance in the size-accuracy trade-off and generally exceeds 4-bit and binary quantization. Considering hardware constraints, 2-bit quantization offers promising potential for memory reduction and speedup.
Hierarchical Context Tagging for Utterance Rewriting
Jun 22, 2022
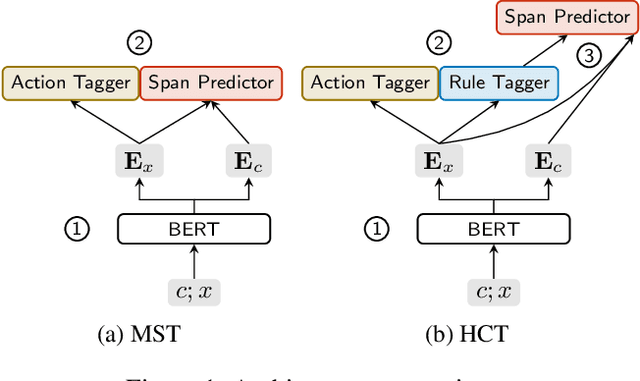

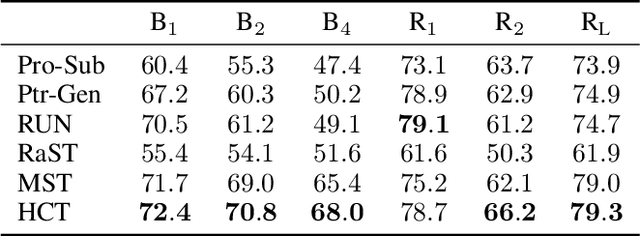
Utterance rewriting aims to recover coreferences and omitted information from the latest turn of a multi-turn dialogue. Recently, methods that tag rather than linearly generate sequences have proven stronger in both in- and out-of-domain rewriting settings. This is due to a tagger's smaller search space as it can only copy tokens from the dialogue context. However, these methods may suffer from low coverage when phrases that must be added to a source utterance cannot be covered by a single context span. This can occur in languages like English that introduce tokens such as prepositions into the rewrite for grammaticality. We propose a hierarchical context tagger (HCT) that mitigates this issue by predicting slotted rules (e.g., "besides _") whose slots are later filled with context spans. HCT (i) tags the source string with token-level edit actions and slotted rules and (ii) fills in the resulting rule slots with spans from the dialogue context. This rule tagging allows HCT to add out-of-context tokens and multiple spans at once; we further cluster the rules to truncate the long tail of the rule distribution. Experiments on several benchmarks show that HCT can outperform state-of-the-art rewriting systems by ~2 BLEU points.
Tree Decomposition Attention for AMR-to-Text Generation
Sep 01, 2021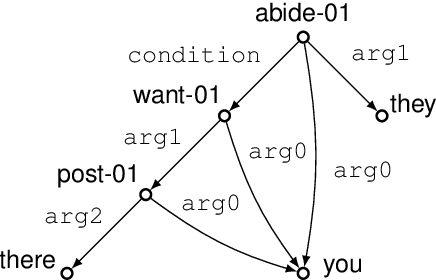
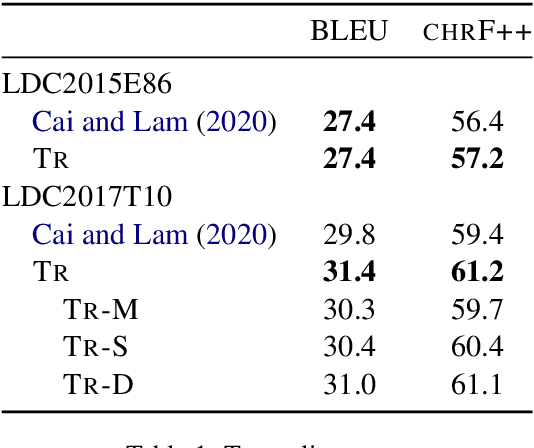
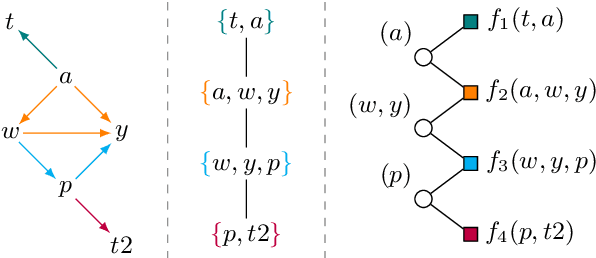

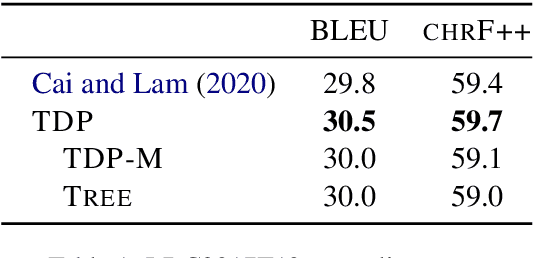
Text generation from AMR requires mapping a semantic graph to a string that it annotates. Transformer-based graph encoders, however, poorly capture vertex dependencies that may benefit sequence prediction. To impose order on an encoder, we locally constrain vertex self-attention using a graph's tree decomposition. Instead of forming a full query-key bipartite graph, we restrict attention to vertices in parent, subtree, and same-depth bags of a vertex. This hierarchical context lends both sparsity and structure to vertex state updates. We apply dynamic programming to derive a forest of tree decompositions, choosing the most structurally similar tree to the AMR. Our system outperforms a self-attentive baseline by 1.6 BLEU and 1.8 chrF++.
Latent Tree Decomposition Parsers for AMR-to-Text Generation
Sep 01, 2021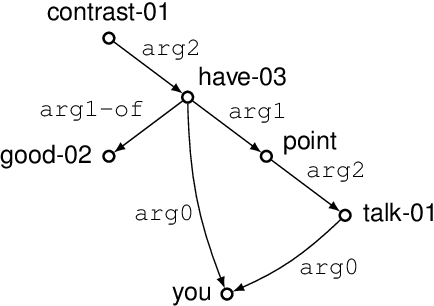
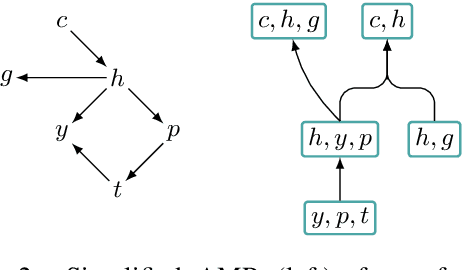

Graph encoders in AMR-to-text generation models often rely on neighborhood convolutions or global vertex attention. While these approaches apply to general graphs, AMRs may be amenable to encoders that target their tree-like structure. By clustering edges into a hierarchy, a tree decomposition summarizes graph structure. Our model encodes a derivation forest of tree decompositions and extracts an expected tree. From tree node embeddings, it builds graph edge features used in vertex attention of the graph encoder. Encoding TD forests instead of shortest-pairwise paths in a self-attentive baseline raises BLEU by 0.7 and chrF++ by 0.3. The forest encoder also surpasses a convolutional baseline for molecular property prediction by 1.92% ROC-AUC.
AMR-to-Text Generation with Cache Transition Systems
Dec 03, 2019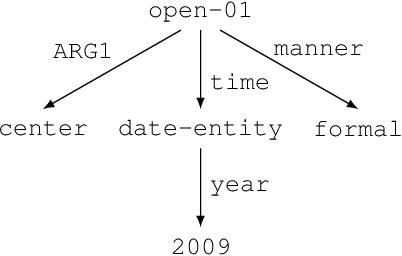

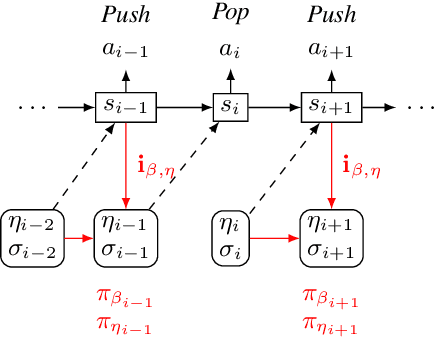
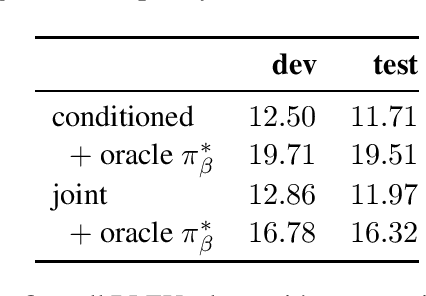
Text generation from AMR involves emitting sentences that reflect the meaning of their AMR annotations. Neural sequence-to-sequence models have successfully been used to decode strings from flattened graphs (e.g., using depth-first or random traversal). Such models often rely on attention-based decoders to map AMR node to English token sequences. Instead of linearizing AMR, we directly encode its graph structure and delegate traversal to the decoder. To enforce a sentence-aligned graph traversal and provide local graph context, we predict transition-based parser actions in addition to English words. We present two model variants: one generates parser actions prior to words, while the other interleaves actions with words.