 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Context Tagging for Utterance Rewriting
Paper and Code

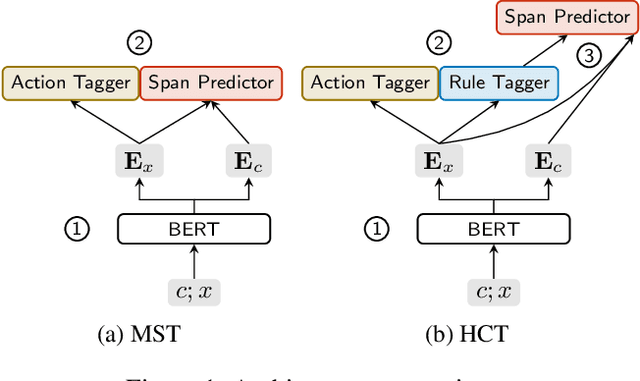

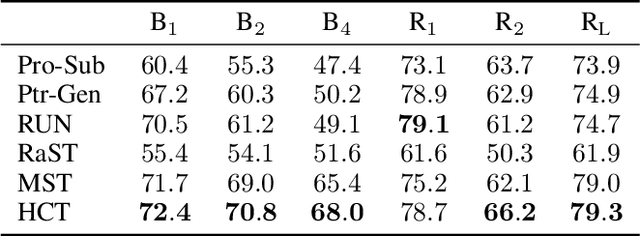
Utterance rewriting aims to recover coreferences and omitted information from the latest turn of a multi-turn dialogue. Recently, methods that tag rather than linearly generate sequences have proven stronger in both in- and out-of-domain rewriting settings. This is due to a tagger's smaller search space as it can only copy tokens from the dialogue context. However, these methods may suffer from low coverage when phrases that must be added to a source utterance cannot be covered by a single context span. This can occur in languages like English that introduce tokens such as prepositions into the rewrite for grammaticality. We propose a hierarchical context tagger (HCT) that mitigates this issue by predicting slotted rules (e.g., "besides _") whose slots are later filled with context spans. HCT (i) tags the source string with token-level edit actions and slotted rules and (ii) fills in the resulting rule slots with spans from the dialogue context. This rule tagging allows HCT to add out-of-context tokens and multiple spans at once; we further cluster the rules to truncate the long tail of the rule distribution. Experiments on several benchmarks show that HCT can outperform state-of-the-art rewriting systems by ~2 BLEU points.