 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrictly Breadth-First AMR Parsing
Nov 08, 2022AMR parsing is the task that maps a sentence to an AMR semantic graph automatically. We focus on the breadth-first strategy of this task, which was proposed recently and achieved better performance than other strategies. However, current models under this strategy only \emph{encourage} the model to produce the AMR graph in breadth-first order, but \emph{cannot guarantee} this. To solve this problem, we propose a new architecture that \emph{guarantees} that the parsing will strictly follow the breadth-first order. In each parsing step, we introduce a \textbf{focused parent} vertex and use this vertex to guide the generation. With the help of this new architecture and some other improvements in the sentence and graph encoder, our model obtains better performance on both the AMR 1.0 and 2.0 dataset.
Hierarchical Context Tagging for Utterance Rewriting
Jun 22, 2022
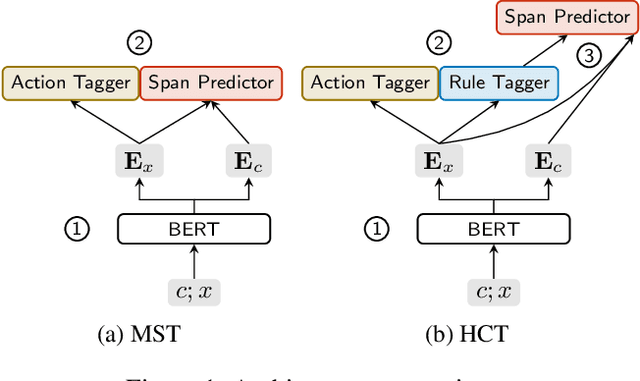

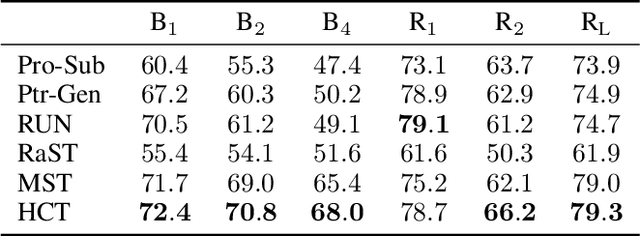
Utterance rewriting aims to recover coreferences and omitted information from the latest turn of a multi-turn dialogue. Recently, methods that tag rather than linearly generate sequences have proven stronger in both in- and out-of-domain rewriting settings. This is due to a tagger's smaller search space as it can only copy tokens from the dialogue context. However, these methods may suffer from low coverage when phrases that must be added to a source utterance cannot be covered by a single context span. This can occur in languages like English that introduce tokens such as prepositions into the rewrite for grammaticality. We propose a hierarchical context tagger (HCT) that mitigates this issue by predicting slotted rules (e.g., "besides _") whose slots are later filled with context spans. HCT (i) tags the source string with token-level edit actions and slotted rules and (ii) fills in the resulting rule slots with spans from the dialogue context. This rule tagging allows HCT to add out-of-context tokens and multiple spans at once; we further cluster the rules to truncate the long tail of the rule distribution. Experiments on several benchmarks show that HCT can outperform state-of-the-art rewriting systems by ~2 BLEU points.
Tree Decomposition Attention for AMR-to-Text Generation
Sep 01, 2021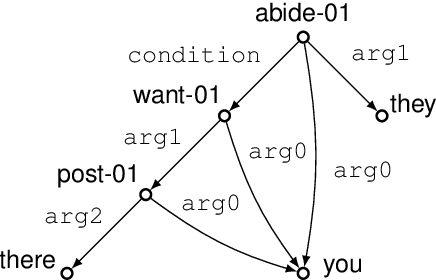
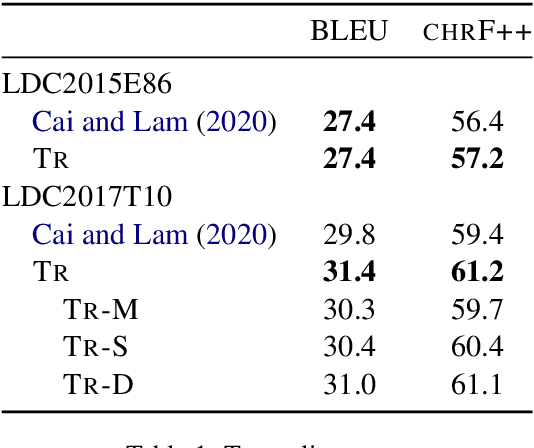
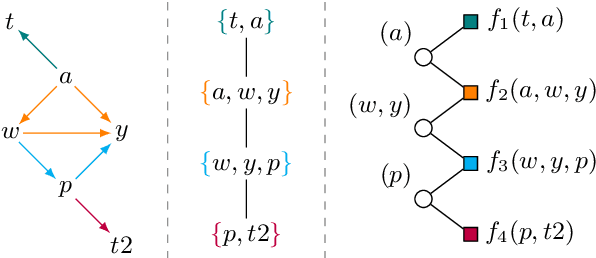

Text generation from AMR requires mapping a semantic graph to a string that it annotates. Transformer-based graph encoders, however, poorly capture vertex dependencies that may benefit sequence prediction. To impose order on an encoder, we locally constrain vertex self-attention using a graph's tree decomposition. Instead of forming a full query-key bipartite graph, we restrict attention to vertices in parent, subtree, and same-depth bags of a vertex. This hierarchical context lends both sparsity and structure to vertex state updates. We apply dynamic programming to derive a forest of tree decompositions, choosing the most structurally similar tree to the AMR. Our system outperforms a self-attentive baseline by 1.6 BLEU and 1.8 chrF++.
Latent Tree Decomposition Parsers for AMR-to-Text Generation
Sep 01, 2021
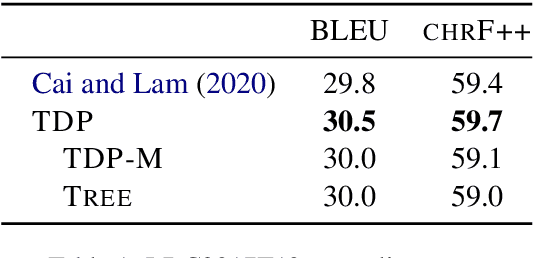
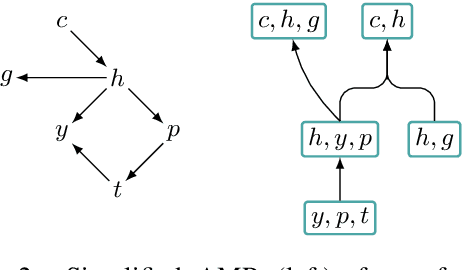

Graph encoders in AMR-to-text generation models often rely on neighborhood convolutions or global vertex attention. While these approaches apply to general graphs, AMRs may be amenable to encoders that target their tree-like structure. By clustering edges into a hierarchy, a tree decomposition summarizes graph structure. Our model encodes a derivation forest of tree decompositions and extracts an expected tree. From tree node embeddings, it builds graph edge features used in vertex attention of the graph encoder. Encoding TD forests instead of shortest-pairwise paths in a self-attentive baseline raises BLEU by 0.7 and chrF++ by 0.3. The forest encoder also surpasses a convolutional baseline for molecular property prediction by 1.92% ROC-AUC.
Tensors over Semirings for Latent-Variable Weighted Logic Programs
Jun 07, 2020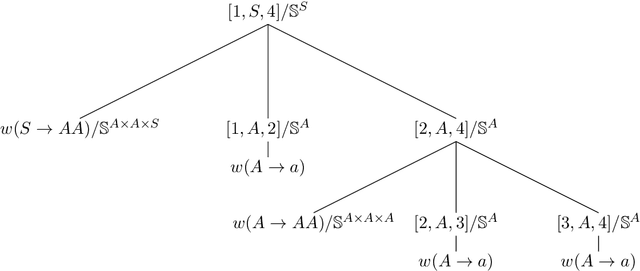
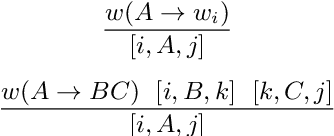
Semiring parsing is an elegant framework for describing parsers by using semiring weighted logic programs. In this paper we present a generalization of this concept: latent-variable semiring parsing. With our framework, any semiring weighted logic program can be latentified by transforming weights from scalar values of a semiring to rank-n arrays, or tensors, of semiring values, allowing the modelling of latent variables within the semiring parsing framework. Semiring is too strong a notion when dealing with tensors, and we have to resort to a weaker structure: a partial semiring. We prove that this generalization preserves all the desired properties of the original semiring framework while strictly increasing its expressiveness.
Unsupervised Bilingual Lexicon Induction Across Writing Systems
Jan 31, 2020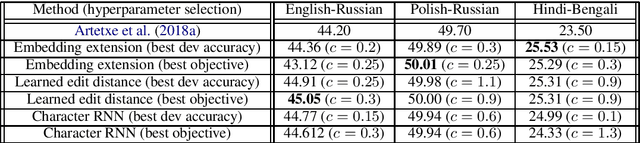
Recent embedding-based methods in unsupervised bilingual lexicon induction have shown good results, but generally have not leveraged orthographic (spelling) information, which can be helpful for pairs of related languages. This work augments a state-of-the-art method with orthographic features, and extends prior work in this space by proposing methods that can learn and utilize orthographic correspondences even between languages with different scripts. We demonstrate this by experimenting on three language pairs with different scripts and varying degrees of lexical similarity.
Leveraging Dependency Forest for Neural Medical Relation Extraction
Dec 16, 2019
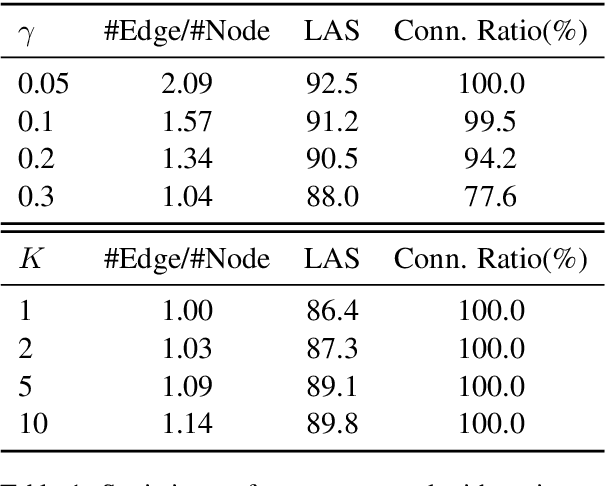
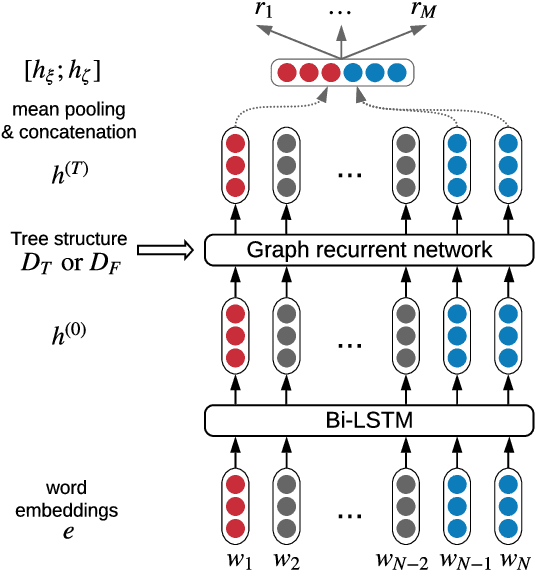
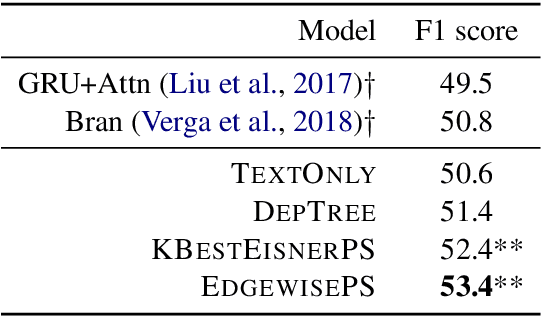
Medical relation extraction discovers relations between entity mentions in text, such as research articles. For this task, dependency syntax has been recognized as a crucial source of features. Yet in the medical domain, 1-best parse trees suffer from relatively low accuracies, diminishing their usefulness. We investigate a method to alleviate this problem by utilizing dependency forests. Forests contain many possible decisions and therefore have higher recall but more noise compared with 1-best outputs. A graph neural network is used to represent the forests, automatically distinguishing the useful syntactic information from parsing noise. Results on two biomedical benchmarks show that our method outperforms the standard tree-based methods, giving the state-of-the-art results in the literature.
AMR-to-Text Generation with Cache Transition Systems
Dec 03, 2019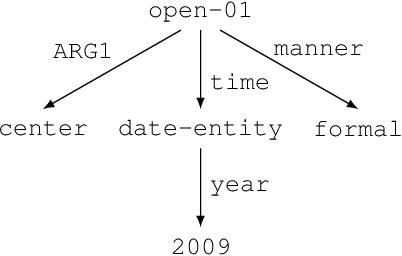

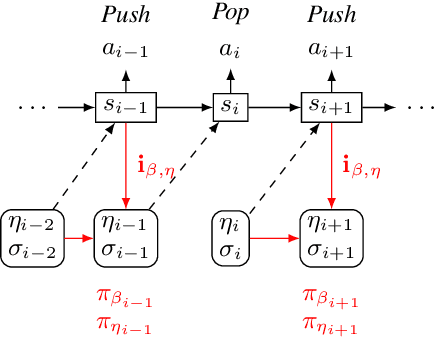
Text generation from AMR involves emitting sentences that reflect the meaning of their AMR annotations. Neural sequence-to-sequence models have successfully been used to decode strings from flattened graphs (e.g., using depth-first or random traversal). Such models often rely on attention-based decoders to map AMR node to English token sequences. Instead of linearizing AMR, we directly encode its graph structure and delegate traversal to the decoder. To enforce a sentence-aligned graph traversal and provide local graph context, we predict transition-based parser actions in addition to English words. We present two model variants: one generates parser actions prior to words, while the other interleaves actions with words.
SemBleu: A Robust Metric for AMR Parsing Evaluation
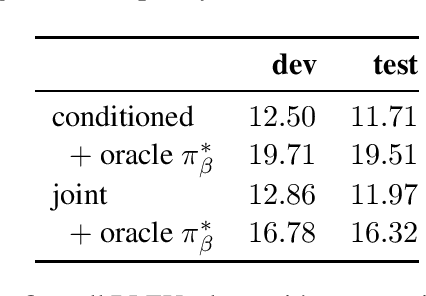
May 30, 2019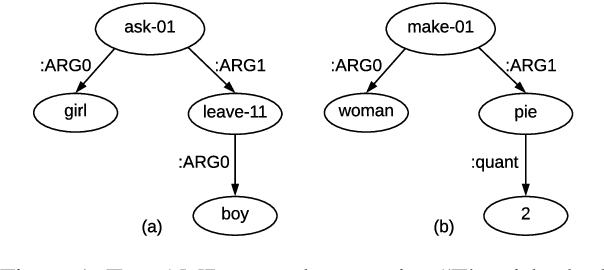

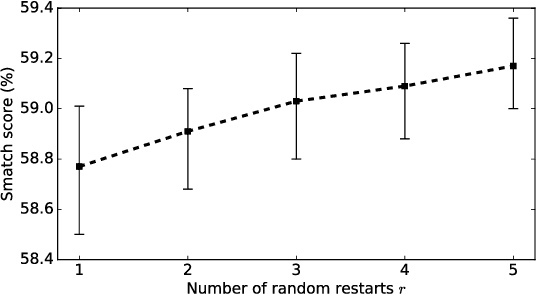

Evaluating AMR parsing accuracy involves comparing pairs of AMR graphs. The major evaluation metric, SMATCH (Cai and Knight, 2013), searches for one-to-one mappings between the nodes of two AMRs with a greedy hill-climbing algorithm, which leads to search errors. We propose SEMBLEU, a robust metric that extends BLEU (Papineni et al., 2002) to AMRs. It does not suffer from search errors and considers non-local correspondences in addition to local ones. SEMBLEU is fully content-driven and punishes situations where a system's output does not preserve most information from the input. Preliminary experiments on both sentence and corpus levels show that SEMBLEU has slightly higher consistency with human judgments than SMATCH. Our code is available at http://github.com/freesunshine0316/sembleu.
Predicting TED Talk Ratings from Language and Prosody
May 21, 2019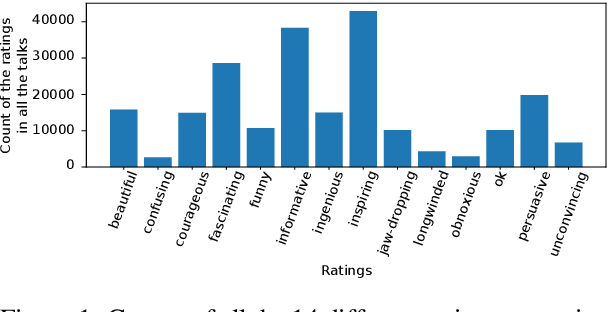
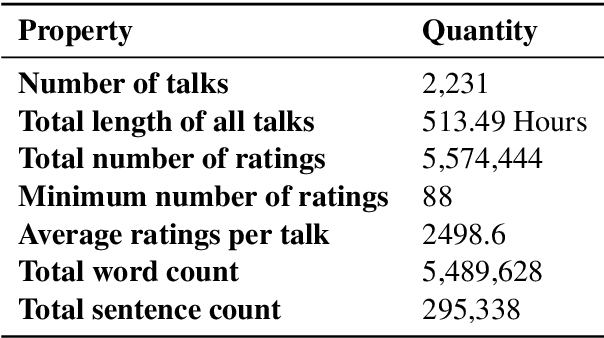
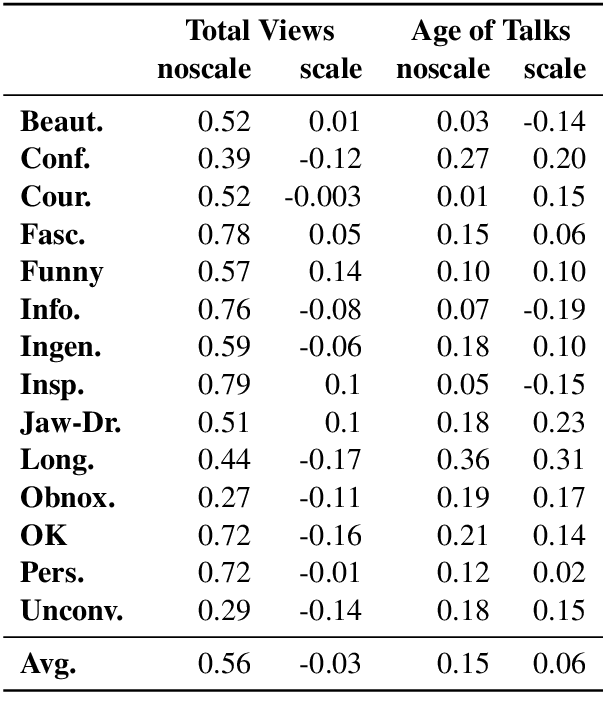
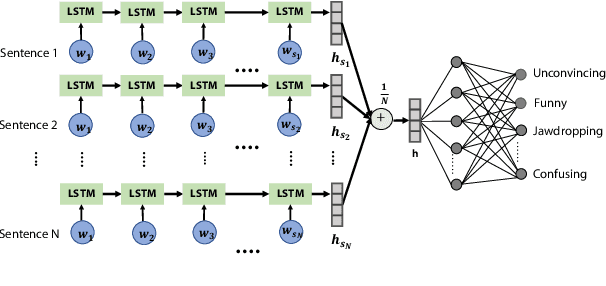
We use the largest open repository of public speaking---TED Talks---to predict the ratings of the online viewers. Our dataset contains over 2200 TED Talk transcripts (includes over 200 thousand sentences), audio features and the associated meta information including about 5.5 Million ratings from spontaneous visitors of the website. We propose three neural network architectures and compare with statistical machine learning. Our experiments reveal that it is possible to predict all the 14 different ratings with an average AUC of 0.83 using the transcripts and prosody features only. The dataset and the complete source code is available for further analysis.