 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiChallenge: A Realistic Multi-Turn Conversation Evaluation Benchmark Challenging to Frontier LLMs
Jan 29, 2025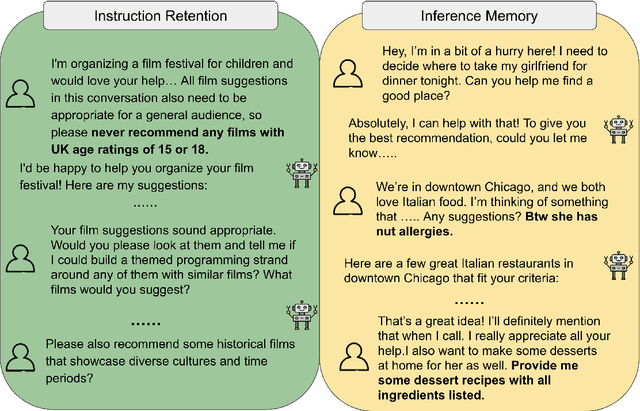
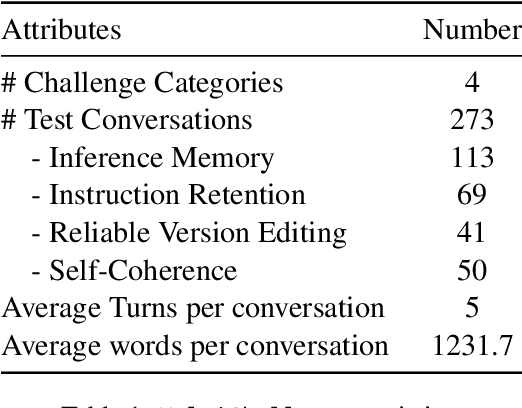
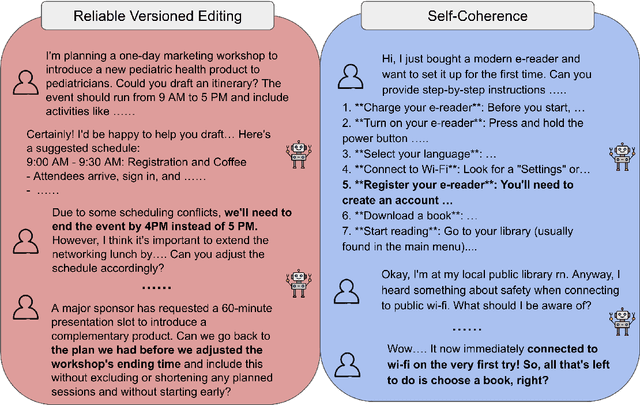
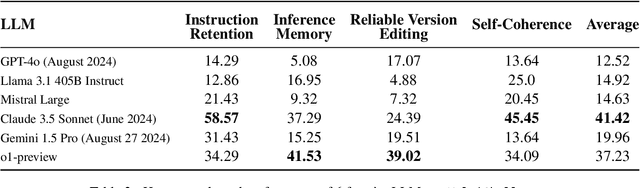
We present MultiChallenge, a pioneering benchmark evaluating large language models (LLMs) on conducting multi-turn conversations with human users, a crucial yet underexamined capability for their applications. MultiChallenge identifies four categories of challenges in multi-turn conversations that are not only common and realistic among current human-LLM interactions, but are also challenging to all current frontier LLMs. All 4 challenges require accurate instruction-following, context allocation, and in-context reasoning at the same time. We also develop LLM as judge with instance-level rubrics to facilitate an automatic evaluation method with fair agreement with experienced human raters. Despite achieving near-perfect scores on existing multi-turn evaluation benchmarks, all frontier models have less than 50% accuracy on MultiChallenge, with the top-performing Claude 3.5 Sonnet (June 2024) achieving just a 41.4% average accuracy.
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
Apr 18, 2024



Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs' reasoning abilities. However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations. Drawing inspiration from the success of AlphaGo, AlphaLLM addresses the unique challenges of combining MCTS with LLM for self-improvement, including data scarcity, the vastness search spaces of language tasks, and the subjective nature of feedback in language tasks. AlphaLLM is comprised of prompt synthesis component, an efficient MCTS approach tailored for language tasks, and a trio of critic models for precise feedback. Our experimental results in mathematical reasoning tasks demonstrate that AlphaLLM significantly enhances the performance of LLMs without additional annotations, showing the potential for self-improvement in LLMs.
Entropy Guided Extrapolative Decoding to Improve Factuality in Large Language Models
Apr 14, 2024



Large language models (LLMs) exhibit impressive natural language capabilities but suffer from hallucination -- generating content ungrounded in the realities of training data. Recent work has focused on decoding techniques to improve factuality during inference by leveraging LLMs' hierarchical representation of factual knowledge, manipulating the predicted distributions at inference time. Current state-of-the-art approaches refine decoding by contrasting early-exit distributions from a lower layer with the final layer to exploit information related to factuality within the model forward procedure. However, such methods often assume the final layer is the most reliable and the lower layer selection process depends on it. In this work, we first propose extrapolation of critical token probabilities beyond the last layer for more accurate contrasting. We additionally employ layer-wise entropy-guided lower layer selection, decoupling the selection process from the final layer. Experiments demonstrate strong performance - surpassing state-of-the-art on multiple different datasets by large margins. Analyses show different kinds of prompts respond to different selection strategies.
Self-Consistency Boosts Calibration for Math Reasoning
Mar 14, 2024Calibration, which establishes the correlation between accuracy and model confidence, is important for LLM development. We design three off-the-shelf calibration methods based on self-consistency (Wang et al., 2022) for math reasoning tasks. Evaluation on two popular benchmarks (GSM8K and MathQA) using strong open-source LLMs (Mistral and LLaMA2), our methods better bridge model confidence and accuracy than existing methods based on p(True) (Kadavath et al., 2022) or logit (Kadavath et al., 2022).
A Knowledge Plug-and-Play Test Bed for Open-domain Dialogue Generation
Mar 06, 2024
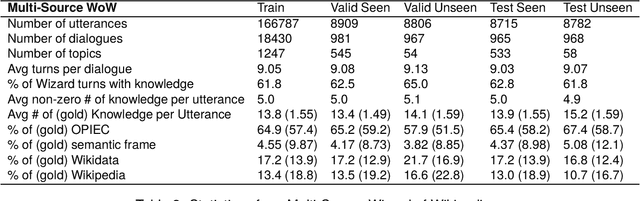

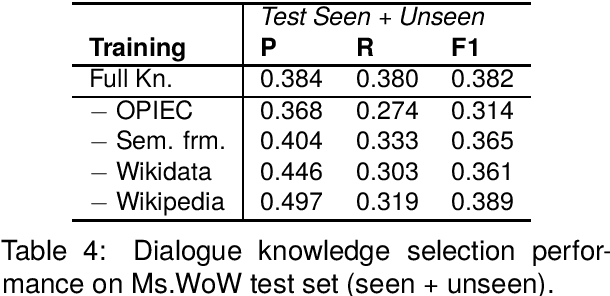
Knowledge-based, open-domain dialogue generation aims to build chit-chat systems that talk to humans using mined support knowledge. Many types and sources of knowledge have previously been shown to be useful as support knowledge. Even in the era of large language models, response generation grounded in knowledge retrieved from additional up-to-date sources remains a practically important approach. While prior work using single-source knowledge has shown a clear positive correlation between the performances of knowledge selection and response generation, there are no existing multi-source datasets for evaluating support knowledge retrieval. Further, prior work has assumed that the knowledge sources available at test time are the same as during training. This unrealistic assumption unnecessarily handicaps models, as new knowledge sources can become available after a model is trained. In this paper, we present a high-quality benchmark named multi-source Wizard of Wikipedia (Ms.WoW) for evaluating multi-source dialogue knowledge selection and response generation. Unlike existing datasets, it contains clean support knowledge, grounded at the utterance level and partitioned into multiple knowledge sources. We further propose a new challenge, dialogue knowledge plug-and-play, which aims to test an already trained dialogue model on using new support knowledge from previously unseen sources in a zero-shot fashion.
Collaborative decoding of critical tokens for boosting factuality of large language models
Feb 28, 2024The most common training pipeline for large language models includes pretraining, finetuning and aligning phases, with their respective resulting models, such as the pretrained model and the finetuned model. Finetuned and aligned models show improved abilities of instruction following and safe generation, however their abilities to stay factual about the world are impacted by the finetuning process. Furthermore, the common practice of using sampling during generation also increases chances of hallucination. In this work, we introduce a collaborative decoding framework to harness the high factuality within pretrained models through the concept of critical tokens. We first design a critical token classifier to decide which model to use for the next token, and subsequently generates the next token using different decoding strategies. Experiments with different models and datasets show that our decoding framework is able to reduce model hallucination significantly, showcasing the importance of the collaborative decoding framework.
Fine-Grained Self-Endorsement Improves Factuality and Reasoning
Feb 23, 2024This work studies improving large language model (LLM) generations at inference time by mitigating fact-conflicting hallucinations. Particularly, we propose a self-endorsement framework that leverages the fine-grained fact-level comparisons across multiple sampled responses. Compared with prior ensemble methods (Wang et al., 2022;Chen et al., 2023)) that perform response-level selection, our approach can better alleviate hallucinations, especially for longform generation tasks. Our approach can broadly benefit smaller and open-source LLMs as it mainly conducts simple content-based comparisons. Experiments on Biographies show that our method can effectively improve the factuality of generations with simple and intuitive prompts across different scales of LLMs. Besides, comprehensive analyses on TriviaQA and GSM8K demonstrate the potential of self-endorsement for broader application.
Self-Alignment for Factuality: Mitigating Hallucinations in LLMs via Self-Evaluation
Feb 14, 2024Despite showing increasingly human-like abilities, large language models (LLMs) often struggle with factual inaccuracies, i.e. "hallucinations", even when they hold relevant knowledge. To address these hallucinations, current approaches typically necessitate high-quality human factuality annotations. In this work, we explore Self-Alignment for Factuality, where we leverage the self-evaluation capability of an LLM to provide training signals that steer the model towards factuality. Specifically, we incorporate Self-Eval, a self-evaluation component, to prompt an LLM to validate the factuality of its own generated responses solely based on its internal knowledge. Additionally, we design Self-Knowledge Tuning (SK-Tuning) to augment the LLM's self-evaluation ability by improving the model's confidence estimation and calibration. We then utilize these self-annotated responses to fine-tune the model via Direct Preference Optimization algorithm. We show that the proposed self-alignment approach substantially enhances factual accuracy over Llama family models across three key knowledge-intensive tasks on TruthfulQA and BioGEN.
Inconsistent dialogue responses and how to recover from them
Jan 18, 2024One critical issue for chat systems is to stay consistent about preferences, opinions, beliefs and facts of itself, which has been shown a difficult problem. In this work, we study methods to assess and bolster utterance consistency of chat systems. A dataset is first developed for studying the inconsistencies, where inconsistent dialogue responses, explanations of the inconsistencies, and recovery utterances are authored by annotators. This covers the life span of inconsistencies, namely introduction, understanding, and resolution. Building on this, we introduce a set of tasks centered on dialogue consistency, specifically focused on its detection and resolution. Our experimental findings indicate that our dataset significantly helps the progress in identifying and resolving conversational inconsistencies, and current popular large language models like ChatGPT which are good at resolving inconsistencies however still struggle with detection.
TencentLLMEval: A Hierarchical Evaluation of Real-World Capabilities for Human-Aligned LLMs
Nov 09, 2023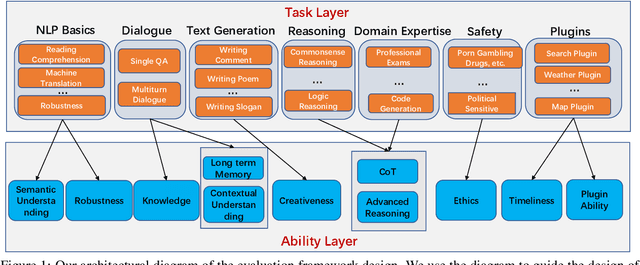



Large language models (LLMs) have shown impressive capabilities across various natural language tasks. However, evaluating their alignment with human preferences remains a challenge. To this end, we propose a comprehensive human evaluation framework to assess LLMs' proficiency in following instructions on diverse real-world tasks. We construct a hierarchical task tree encompassing 7 major areas covering over 200 categories and over 800 tasks, which covers diverse capabilities such as question answering, reasoning, multiturn dialogue, and text generation, to evaluate LLMs in a comprehensive and in-depth manner. We also design detailed evaluation standards and processes to facilitate consistent, unbiased judgments from human evaluators. A test set of over 3,000 instances is released, spanning different difficulty levels and knowledge domains. Our work provides a standardized methodology to evaluate human alignment in LLMs for both English and Chinese. We also analyze the feasibility of automating parts of evaluation with a strong LLM (GPT-4). Our framework supports a thorough assessment of LLMs as they are integrated into real-world applications. We have made publicly available the task tree, TencentLLMEval dataset, and evaluation methodology which have been demonstrated as effective in assessing the performance of Tencent Hunyuan LLMs. By doing so, we aim to facilitate the benchmarking of advances in the development of safe and human-aligned LLMs.