 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnigmaEval: A Benchmark of Long Multimodal Reasoning Challenges
Feb 13, 2025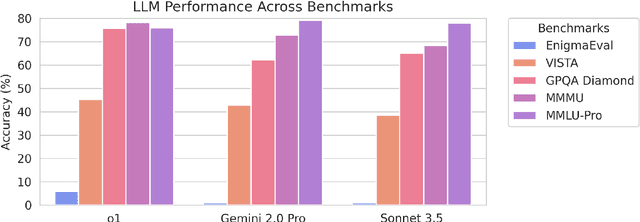



As language models master existing reasoning benchmarks, we need new challenges to evaluate their cognitive frontiers. Puzzle-solving events are rich repositories of challenging multimodal problems that test a wide range of advanced reasoning and knowledge capabilities, making them a unique testbed for evaluating frontier language models. We introduce EnigmaEval, a dataset of problems and solutions derived from puzzle competitions and events that probes models' ability to perform implicit knowledge synthesis and multi-step deductive reasoning. Unlike existing reasoning and knowledge benchmarks, puzzle solving challenges models to discover hidden connections between seemingly unrelated pieces of information to uncover solution paths. The benchmark comprises 1184 puzzles of varying complexity -- each typically requiring teams of skilled solvers hours to days to complete -- with unambiguous, verifiable solutions that enable efficient evaluation. State-of-the-art language models achieve extremely low accuracy on these puzzles, even lower than other difficult benchmarks such as Humanity's Last Exam, unveiling models' shortcomings when challenged with problems requiring unstructured and lateral reasoning.
MultiChallenge: A Realistic Multi-Turn Conversation Evaluation Benchmark Challenging to Frontier LLMs
Jan 29, 2025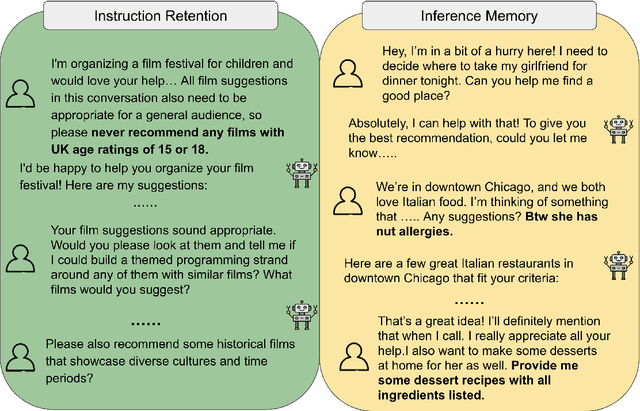
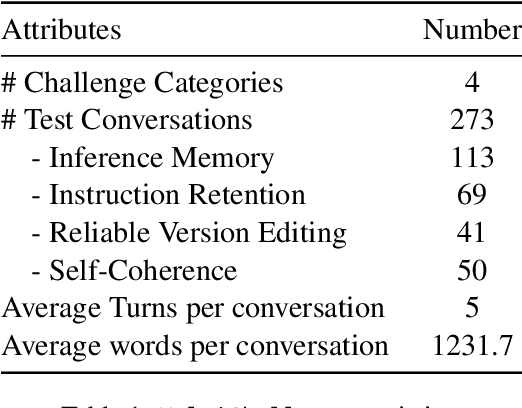
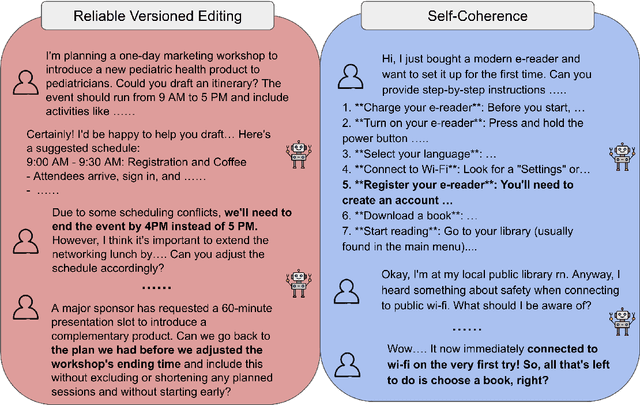
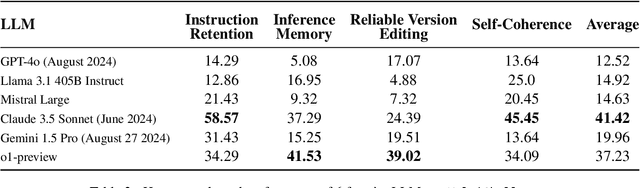
We present MultiChallenge, a pioneering benchmark evaluating large language models (LLMs) on conducting multi-turn conversations with human users, a crucial yet underexamined capability for their applications. MultiChallenge identifies four categories of challenges in multi-turn conversations that are not only common and realistic among current human-LLM interactions, but are also challenging to all current frontier LLMs. All 4 challenges require accurate instruction-following, context allocation, and in-context reasoning at the same time. We also develop LLM as judge with instance-level rubrics to facilitate an automatic evaluation method with fair agreement with experienced human raters. Despite achieving near-perfect scores on existing multi-turn evaluation benchmarks, all frontier models have less than 50% accuracy on MultiChallenge, with the top-performing Claude 3.5 Sonnet (June 2024) achieving just a 41.4% average accuracy.