 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebCoT: Enhancing Web Agent Reasoning by Reconstructing Chain-of-Thought in Reflection, Branching, and Rollback
May 26, 2025Web agents powered by Large Language Models (LLMs) show promise for next-generation AI, but their limited reasoning in uncertain, dynamic web environments hinders robust deployment. In this paper, we identify key reasoning skills essential for effective web agents, i.e., reflection & lookahead, branching, and rollback, and curate trajectory data that exemplifies these abilities by reconstructing the agent's (inference-time) reasoning algorithms into chain-of-thought rationales. We conduct experiments in the agent self-improving benchmark, OpenWebVoyager, and demonstrate that distilling salient reasoning patterns into the backbone LLM via simple fine-tuning can substantially enhance its performance. Our approach yields significant improvements across multiple benchmarks, including WebVoyager, Mind2web-live, and SimpleQA (web search), highlighting the potential of targeted reasoning skill enhancement for web agents.
NILE: Internal Consistency Alignment in Large Language Models
Dec 21, 2024As a crucial step to enhance LLMs alignment with human intentions, Instruction Fine-Tuning (IFT) has a high demand on dataset quality. However, existing IFT datasets often contain knowledge that is inconsistent with LLMs' internal knowledge learned from the pre-training phase, which can greatly affect the efficacy of IFT. To address this issue, we introduce NILE (iNternal consIstency aLignmEnt) framework, aimed at optimizing IFT datasets to unlock LLMs' capability further. NILE operates by eliciting target pre-trained LLM's internal knowledge corresponding to instruction data. The internal knowledge is leveraged to revise the answer in IFT datasets. Additionally, we propose a novel Internal Consistency Filtering (ICF) method to filter training samples, ensuring its high consistency with LLM's internal knowledge. Our experiments demonstrate that NILE-aligned IFT datasets sharply boost LLM performance across multiple LLM ability evaluation datasets, achieving up to 66.6% gain on Arena-Hard and 68.5% on Alpaca-Eval V2. Further analysis confirms that each component of the NILE}framework contributes to these substantial performance improvements, and provides compelling evidence that dataset consistency with pre-trained internal knowledge is pivotal for maximizing LLM potential.
Towards Within-Class Variation in Alzheimer's Disease Detection from Spontaneous Speech
Sep 22, 2024



Alzheimer's Disease (AD) detection has emerged as a promising research area that employs machine learning classification models to distinguish between individuals with AD and those without. Unlike conventional classification tasks, we identify within-class variation as a critical challenge in AD detection: individuals with AD exhibit a spectrum of cognitive impairments. Given that many AD detection tasks lack fine-grained labels, simplistic binary classification may overlook two crucial aspects: within-class differences and instance-level imbalance. The former compels the model to map AD samples with varying degrees of impairment to a single diagnostic label, disregarding certain changes in cognitive function. While the latter biases the model towards overrepresented severity levels. This work presents early efforts to address these challenges. We propose two novel methods: Soft Target Distillation (SoTD) and Instance-level Re-balancing (InRe), targeting two problems respectively. Experiments on the ADReSS and ADReSSo datasets demonstrate that the proposed methods significantly improve detection accuracy. Further analysis reveals that SoTD effectively harnesses the strengths of multiple component models, while InRe substantially alleviates model over-fitting. These findings provide insights for developing more robust and reliable AD detection models.
Purple-teaming LLMs with Adversarial Defender Training
Jul 01, 2024Existing efforts in safeguarding LLMs are limited in actively exposing the vulnerabilities of the target LLM and readily adapting to newly emerging safety risks. To address this, we present Purple-teaming LLMs with Adversarial Defender training (PAD), a pipeline designed to safeguard LLMs by novelly incorporating the red-teaming (attack) and blue-teaming (safety training) techniques. In PAD, we automatically collect conversational data that cover the vulnerabilities of an LLM around specific safety risks in a self-play manner, where the attacker aims to elicit unsafe responses and the defender generates safe responses to these attacks. We then update both modules in a generative adversarial network style by training the attacker to elicit more unsafe responses and updating the defender to identify them and explain the unsafe reason. Experimental results demonstrate that PAD significantly outperforms existing baselines in both finding effective attacks and establishing a robust safe guardrail. Furthermore, our findings indicate that PAD excels in striking a balance between safety and overall model quality. We also reveal key challenges in safeguarding LLMs, including defending multi-turn attacks and the need for more delicate strategies to identify specific risks.
Enhancing Biomedical Knowledge Retrieval-Augmented Generation with Self-Rewarding Tree Search and Proximal Policy Optimization
Jun 17, 2024



Large Language Models (LLMs) have shown great potential in the biomedical domain with the advancement of retrieval-augmented generation (RAG). However, existing retrieval-augmented approaches face challenges in addressing diverse queries and documents, particularly for medical knowledge queries, resulting in sub-optimal performance. To address these limitations, we propose a novel plug-and-play LLM-based retrieval method called Self-Rewarding Tree Search (SeRTS) based on Monte Carlo Tree Search (MCTS) and a self-rewarding paradigm. By combining the reasoning capabilities of LLMs with the effectiveness of tree search, SeRTS boosts the zero-shot performance of retrieving high-quality and informative results for RAG. We further enhance retrieval performance by fine-tuning LLMs with Proximal Policy Optimization (PPO) objectives using the trajectories collected by SeRTS as feedback. Controlled experiments using the BioASQ-QA dataset with GPT-3.5-Turbo and LLama2-7b demonstrate that our method significantly improves the performance of the BM25 retriever and surpasses the strong baseline of self-reflection in both efficiency and scalability. Moreover, SeRTS generates higher-quality feedback for PPO training than self-reflection. Our proposed method effectively adapts LLMs to document retrieval tasks, enhancing their ability to retrieve highly relevant documents for RAG in the context of medical knowledge queries. This work presents a significant step forward in leveraging LLMs for accurate and comprehensive biomedical question answering.
Self-Tuning: Instructing LLMs to Effectively Acquire New Knowledge through Self-Teaching
Jun 11, 2024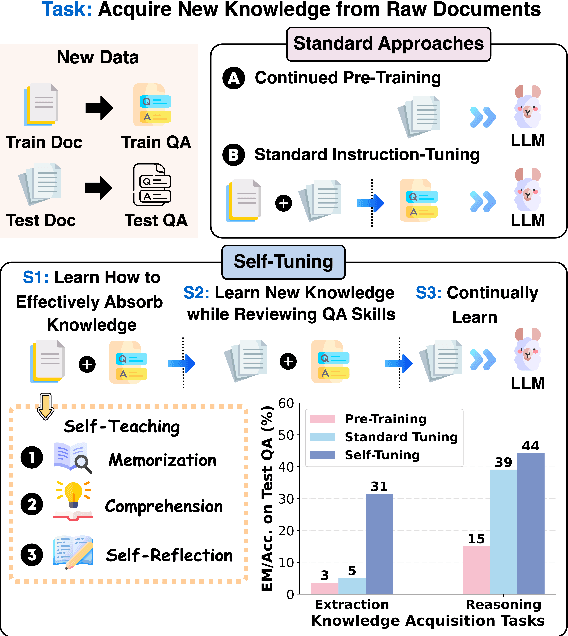
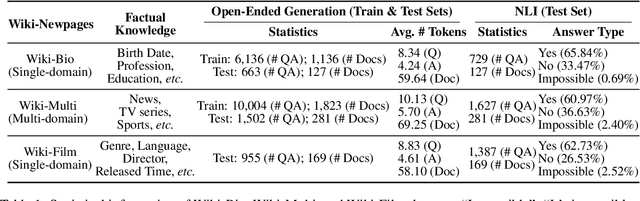

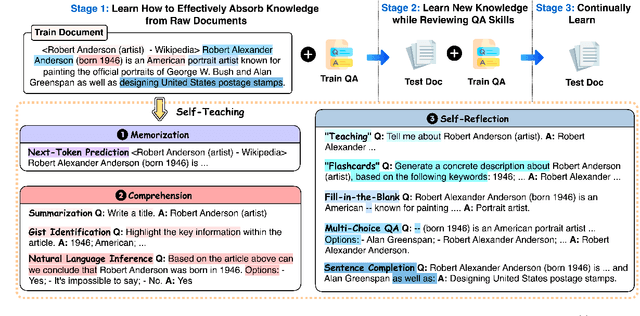
Large language models (LLMs) often struggle to provide up-to-date information due to their one-time training and the constantly evolving nature of the world. To keep LLMs current, existing approaches typically involve continued pre-training on new documents. However, they frequently face difficulties in extracting stored knowledge. Motivated by the remarkable success of the Feynman Technique in efficient human learning, we introduce Self-Tuning, a learning framework aimed at improving an LLM's ability to effectively acquire new knowledge from raw documents through self-teaching. Specifically, we develop a Self-Teaching strategy that augments the documents with a set of knowledge-intensive tasks created in a self-supervised manner, focusing on three crucial aspects: memorization, comprehension, and self-reflection. Additionally, we introduce three Wiki-Newpages-2023-QA datasets to facilitate an in-depth analysis of an LLM's knowledge acquisition ability concerning memorization, extraction, and reasoning. Extensive experimental results on Llama2 family models reveal that Self-Tuning consistently exhibits superior performance across all knowledge acquisition tasks and excels in preserving previous knowledge.
Self-Alignment for Factuality: Mitigating Hallucinations in LLMs via Self-Evaluation
Feb 14, 2024Despite showing increasingly human-like abilities, large language models (LLMs) often struggle with factual inaccuracies, i.e. "hallucinations", even when they hold relevant knowledge. To address these hallucinations, current approaches typically necessitate high-quality human factuality annotations. In this work, we explore Self-Alignment for Factuality, where we leverage the self-evaluation capability of an LLM to provide training signals that steer the model towards factuality. Specifically, we incorporate Self-Eval, a self-evaluation component, to prompt an LLM to validate the factuality of its own generated responses solely based on its internal knowledge. Additionally, we design Self-Knowledge Tuning (SK-Tuning) to augment the LLM's self-evaluation ability by improving the model's confidence estimation and calibration. We then utilize these self-annotated responses to fine-tune the model via Direct Preference Optimization algorithm. We show that the proposed self-alignment approach substantially enhances factual accuracy over Llama family models across three key knowledge-intensive tasks on TruthfulQA and BioGEN.
A Survey of the Evolution of Language Model-Based Dialogue Systems
Nov 28, 2023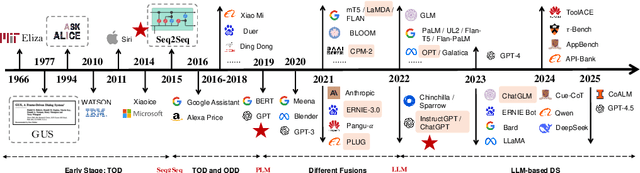



Dialogue systems, including task-oriented_dialogue_system (TOD) and open-domain_dialogue_system (ODD), have undergone significant transformations, with language_models (LM) playing a central role. This survey delves into the historical trajectory of dialogue systems, elucidating their intricate relationship with advancements in language models by categorizing this evolution into four distinct stages, each marked by pivotal LM breakthroughs: 1) Early_Stage: characterized by statistical LMs, resulting in rule-based or machine-learning-driven dialogue_systems; 2) Independent development of TOD and ODD based on neural_language_models (NLM; e.g., LSTM and GRU), since NLMs lack intrinsic knowledge in their parameters; 3) fusion between different types of dialogue systems with the advert of pre-trained_language_models (PLMs), starting from the fusion between four_sub-tasks_within_TOD, and then TOD_with_ODD; and 4) current LLM-based_dialogue_system, wherein LLMs can be used to conduct TOD and ODD seamlessly. Thus, our survey provides a chronological perspective aligned with LM breakthroughs, offering a comprehensive review of state-of-the-art research outcomes. What's more, we focus on emerging topics and discuss open challenges, providing valuable insights into future directions for LLM-based_dialogue_systems. Through this exploration, we pave the way for a deeper_comprehension of the evolution, guiding future developments in LM-based dialogue_systems.
Rethinking Machine Ethics -- Can LLMs Perform Moral Reasoning through the Lens of Moral Theories?
Aug 29, 2023
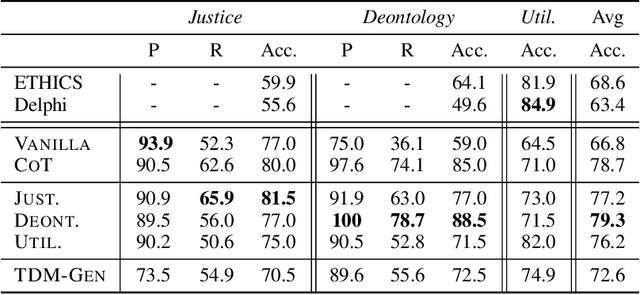
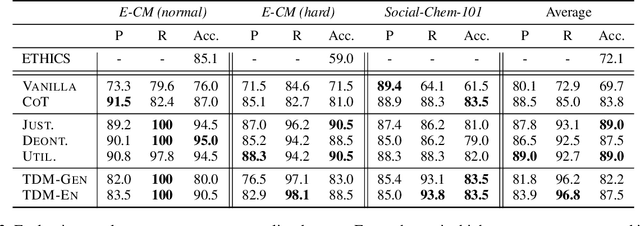
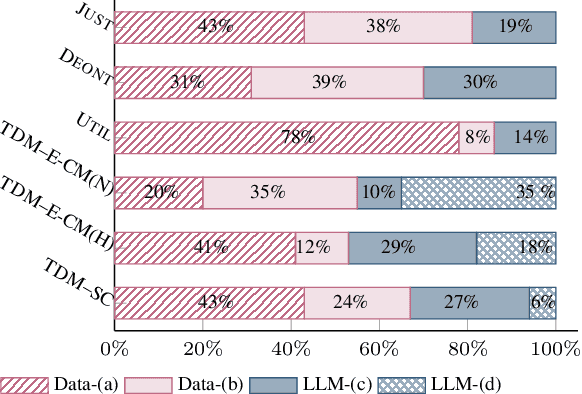
Making moral judgments is an essential step toward developing ethical AI systems. Prevalent approaches are mostly implemented in a bottom-up manner, which uses a large set of annotated data to train models based on crowd-sourced opinions about morality. These approaches have been criticized for potentially overgeneralizing a limited group of annotators' moral stances and lacking explainability. In contrast, top-down approaches make moral judgments grounded in a set of principles. However, it remains conceptual due to the incapability of previous language models and the unsolved debate among moral principles. In this study, we propose a flexible framework to steer Large Language Models (LLMs) to perform moral reasoning with well-established moral theories from interdisciplinary research. The theory-guided top-down framework can incorporate various moral theories. Our experiments demonstrate the effectiveness of the proposed framework on datasets derived from moral theories. Furthermore, we show the alignment between different moral theories and existing morality datasets. Our analysis exhibits the potentials and flaws in existing resources (models and datasets) in developing explainable moral judgment-making systems.
SGP-TOD: Building Task Bots Effortlessly via Schema-Guided LLM Prompting
May 15, 2023



Building end-to-end task bots and maintaining their integration with new functionalities using minimal human efforts is a long-standing challenge in dialog research. Recently large language models (LLMs) have demonstrated exceptional proficiency in conversational engagement and adherence to instructions across various downstream tasks. In this work, we introduce SGP-TOD, Schema-Guided Prompting for building Task-Oriented Dialog systems effortlessly based on LLMs. Utilizing the symbolic knowledge -- task schema, we instruct fixed LLMs to generate appropriate responses on novel tasks, circumventing the need for training data. Specifically, SGP-TOD comprises three components: a LLM for engaging with users, a DST Prompter to aid the LLM with dialog state tracking, which is then used to retrieve database items, and a Policy Prompter to elicit proper responses adhering to the provided dialog policy. Experimental results on Multiwoz, RADDLE and STAR datasets show that our training-free strategy SGP-TOD, without any task-specific data, yields state-of-the-art (SOTA) zero-shot performance, greatly surpasses the few-shot approaches. In a domain-extension setting, SGP-TOD aptly adapts to new functionalities by merely adding supplementary schema rules. We make our code and data publicly available.