 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Cognitive Profiling: Realigning Automated Alzheimer's Disease Detection with Clinical Construct Validity
Mar 18, 2026Automated Alzheimer's Disease (AD) screening has predominantly followed the inductive paradigm of pattern recognition, which directly maps the input signal to the outcome label. This paradigm sacrifices construct validity of clinical protocol for statistical shortcuts. This paper proposes Agentic Cognitive Profiling (ACP), an agentic framework that realigns automated screening with clinical protocol logic across multiple cognitive domains. Rather than learning opaque mappings from transcripts to labels, the framework decomposes standardized assessments into atomic cognitive tasks and orchestrates specialized LLM agents to extract verifiable scoring primitives. Central to our design is decoupling semantic understanding from measurement by delegating all quantification to deterministic function calling, thereby mitigating hallucination and restoring construct validity. Unlike popular datasets that typically comprise around a hundred participants under a single task, we evaluate on a clinically-annotated corpus of 402 participants across eight structured cognitive tasks spanning multiple cognitive domains. The framework achieves 90.5% score match rate in task examination and 85.3% accuracy in AD prediction, surpassing popular baselines while generating interpretable cognitive profiles grounded in behavioral evidence. This work demonstrates that construct validity and predictive performance need not be traded off, charting a path toward AD screening systems that explain rather than merely predict.
Discovery and Reinforcement of Tool-Integrated Reasoning Chains via Rollout Trees
Jan 13, 2026Tool-Integrated Reasoning has emerged as a key paradigm to augment Large Language Models (LLMs) with computational capabilities, yet integrating tool-use into long Chain-of-Thought (long CoT) remains underexplored, largely due to the scarcity of training data and the challenge of integrating tool-use without compromising the model's intrinsic long-chain reasoning. In this paper, we introduce DART (Discovery And Reinforcement of Tool-Integrated Reasoning Chains via Rollout Trees), a reinforcement learning framework that enables spontaneous tool-use during long CoT reasoning without human annotation. DART operates by constructing dynamic rollout trees during training to discover valid tool-use opportunities, branching out at promising positions to explore diverse tool-integrated trajectories. Subsequently, a tree-based process advantage estimation identifies and credits specific sub-trajectories where tool invocation positively contributes to the solution, effectively reinforcing these beneficial behaviors. Extensive experiments on challenging benchmarks like AIME and GPQA-Diamond demonstrate that DART significantly outperforms existing methods, successfully harmonizing tool execution with long CoT reasoning.
TreePS-RAG: Tree-based Process Supervision for Reinforcement Learning in Agentic RAG
Jan 11, 2026Agentic retrieval-augmented generation (RAG) formulates question answering as a multi-step interaction between reasoning and information retrieval, and has recently been advanced by reinforcement learning (RL) with outcome-based supervision. While effective, relying solely on sparse final rewards limits step-wise credit assignment and provides weak guidance for intermediate reasoning and actions. Recent efforts explore process-level supervision, but typically depend on offline constructed training data, which risks distribution shift, or require costly intermediate annotations. We present TreePS-RAG, an online, tree-based RL framework for agentic RAG that enables step-wise credit assignment while retaining standard outcome-only rewards. Our key insight is to model agentic RAG reasoning as a rollout tree, where each reasoning step naturally maps to a node. This tree structure allows step utility to be estimated via Monte Carlo estimation over its descendant outcomes, yielding fine-grained process advantages without requiring intermediate labels. To make this paradigm practical, we introduce an efficient online tree construction strategy that preserves exploration diversity under a constrained computational budget. With a rollout cost comparable to strong baselines like Search-R1, experiments on seven multi-hop and general QA benchmarks across multiple model scales show that TreePS-RAG consistently and significantly outperforms both outcome-supervised and leading process-supervised RL methods.
Speech Discrete Tokens or Continuous Features? A Comparative Analysis for Spoken Language Understanding in SpeechLLMs
Aug 25, 2025With the rise of Speech Large Language Models (SpeechLLMs), two dominant approaches have emerged for speech processing: discrete tokens and continuous features. Each approach has demonstrated strong capabilities in audio-related processing tasks. However, the performance gap between these two paradigms has not been thoroughly explored. To address this gap, we present a fair comparison of self-supervised learning (SSL)-based discrete and continuous features under the same experimental settings. We evaluate their performance across six spoken language understanding-related tasks using both small and large-scale LLMs (Qwen1.5-0.5B and Llama3.1-8B). We further conduct in-depth analyses, including efficient comparison, SSL layer analysis, LLM layer analysis, and robustness comparison. Our findings reveal that continuous features generally outperform discrete tokens in various tasks. Each speech processing method exhibits distinct characteristics and patterns in how it learns and processes speech information. We hope our results will provide valuable insights to advance spoken language understanding in SpeechLLMs.
MMSU: A Massive Multi-task Spoken Language Understanding and Reasoning Benchmark
Jun 05, 2025Speech inherently contains rich acoustic information that extends far beyond the textual language. In real-world spoken language understanding, effective interpretation often requires integrating semantic meaning (e.g., content), paralinguistic features (e.g., emotions, speed, pitch) and phonological characteristics (e.g., prosody, intonation, rhythm), which are embedded in speech. While recent multimodal Speech Large Language Models (SpeechLLMs) have demonstrated remarkable capabilities in processing audio information, their ability to perform fine-grained perception and complex reasoning in natural speech remains largely unexplored. To address this gap, we introduce MMSU, a comprehensive benchmark designed specifically for understanding and reasoning in spoken language. MMSU comprises 5,000 meticulously curated audio-question-answer triplets across 47 distinct tasks. To ground our benchmark in linguistic theory, we systematically incorporate a wide range of linguistic phenomena, including phonetics, prosody, rhetoric, syntactics, semantics, and paralinguistics. Through a rigorous evaluation of 14 advanced SpeechLLMs, we identify substantial room for improvement in existing models, highlighting meaningful directions for future optimization. MMSU establishes a new standard for comprehensive assessment of spoken language understanding, providing valuable insights for developing more sophisticated human-AI speech interaction systems. MMSU benchmark is available at https://huggingface.co/datasets/ddwang2000/MMSU. Evaluation Code is available at https://github.com/dingdongwang/MMSU_Bench.
Detecting Neurocognitive Disorders through Analyses of Topic Evolution and Cross-modal Consistency in Visual-Stimulated Narratives
Jan 07, 2025



Early detection of neurocognitive disorders (NCDs) is crucial for timely intervention and disease management. Speech analysis offers a non-intrusive and scalable screening method, particularly through narrative tasks in neuropsychological assessment tools. Traditional narrative analysis often focuses on local indicators in microstructure, such as word usage and syntax. While these features provide insights into language production abilities, they often fail to capture global narrative patterns, or microstructures. Macrostructures include coherence, thematic organization, and logical progressions, reflecting essential cognitive skills potentially critical for recognizing NCDs. Addressing this gap, we propose to investigate specific cognitive and linguistic challenges by analyzing topical shifts, temporal dynamics, and the coherence of narratives over time, aiming to reveal cognitive deficits by identifying narrative impairments, and exploring their impact on communication and cognition. The investigation is based on the CU-MARVEL Rabbit Story corpus, which comprises recordings of a story-telling task from 758 older adults. We developed two approaches: the Dynamic Topic Models (DTM)-based temporal analysis to examine the evolution of topics over time, and the Text-Image Temporal Alignment Network (TITAN) to evaluate the coherence between spoken narratives and visual stimuli. DTM-based approach validated the effectiveness of dynamic topic consistency as a macrostructural metric (F1=0.61, AUC=0.78). The TITAN approach achieved the highest performance (F1=0.72, AUC=0.81), surpassing established microstructural and macrostructural feature sets. Cross-comparison and regression tasks further demonstrated the effectiveness of proposed dynamic macrostructural modeling approaches for NCD detection.
Not All Errors Are Equal: Investigation of Speech Recognition Errors in Alzheimer's Disease Detection
Dec 09, 2024Automatic Speech Recognition (ASR) plays an important role in speech-based automatic detection of Alzheimer's disease (AD). However, recognition errors could propagate downstream, potentially impacting the detection decisions. Recent studies have revealed a non-linear relationship between word error rates (WER) and AD detection performance, where ASR transcriptions with notable errors could still yield AD detection accuracy equivalent to that based on manual transcriptions. This work presents a series of analyses to explore the effect of ASR transcription errors in BERT-based AD detection systems. Our investigation reveals that not all ASR errors contribute equally to detection performance. Certain words, such as stopwords, despite constituting a large proportion of errors, are shown to play a limited role in distinguishing AD. In contrast, the keywords related to diagnosis tasks exhibit significantly greater importance relative to other words. These findings provide insights into the interplay between ASR errors and the downstream detection model.
Devising a Set of Compact and Explainable Spoken Language Feature for Screening Alzheimer's Disease
Nov 28, 2024



Alzheimer's disease (AD) has become one of the most significant health challenges in an aging society. The use of spoken language-based AD detection methods has gained prevalence due to their scalability due to their scalability. Based on the Cookie Theft picture description task, we devised an explainable and effective feature set that leverages the visual capabilities of a large language model (LLM) and the Term Frequency-Inverse Document Frequency (TF-IDF) model. Our experimental results show that the newly proposed features consistently outperform traditional linguistic features across two different classifiers with high dimension efficiency. Our new features can be well explained and interpreted step by step which enhance the interpretability of automatic AD screening.
Purple-teaming LLMs with Adversarial Defender Training
Jul 01, 2024Existing efforts in safeguarding LLMs are limited in actively exposing the vulnerabilities of the target LLM and readily adapting to newly emerging safety risks. To address this, we present Purple-teaming LLMs with Adversarial Defender training (PAD), a pipeline designed to safeguard LLMs by novelly incorporating the red-teaming (attack) and blue-teaming (safety training) techniques. In PAD, we automatically collect conversational data that cover the vulnerabilities of an LLM around specific safety risks in a self-play manner, where the attacker aims to elicit unsafe responses and the defender generates safe responses to these attacks. We then update both modules in a generative adversarial network style by training the attacker to elicit more unsafe responses and updating the defender to identify them and explain the unsafe reason. Experimental results demonstrate that PAD significantly outperforms existing baselines in both finding effective attacks and establishing a robust safe guardrail. Furthermore, our findings indicate that PAD excels in striking a balance between safety and overall model quality. We also reveal key challenges in safeguarding LLMs, including defending multi-turn attacks and the need for more delicate strategies to identify specific risks.
Rethinking Machine Ethics -- Can LLMs Perform Moral Reasoning through the Lens of Moral Theories?
Aug 29, 2023
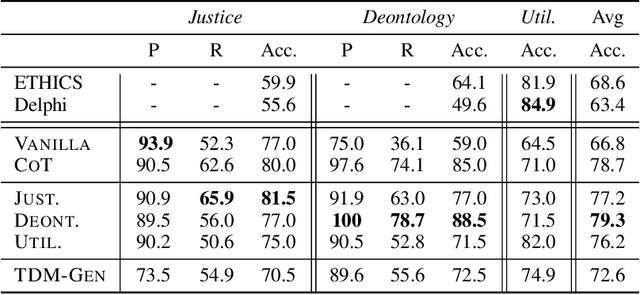
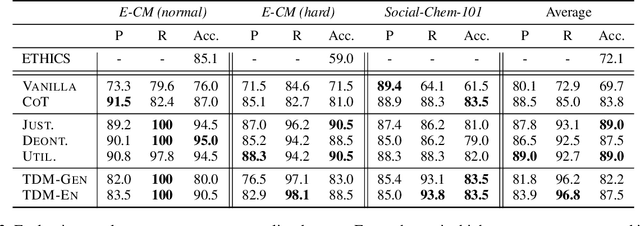
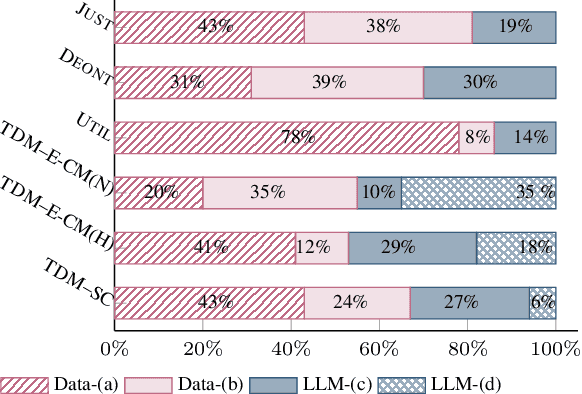
Making moral judgments is an essential step toward developing ethical AI systems. Prevalent approaches are mostly implemented in a bottom-up manner, which uses a large set of annotated data to train models based on crowd-sourced opinions about morality. These approaches have been criticized for potentially overgeneralizing a limited group of annotators' moral stances and lacking explainability. In contrast, top-down approaches make moral judgments grounded in a set of principles. However, it remains conceptual due to the incapability of previous language models and the unsolved debate among moral principles. In this study, we propose a flexible framework to steer Large Language Models (LLMs) to perform moral reasoning with well-established moral theories from interdisciplinary research. The theory-guided top-down framework can incorporate various moral theories. Our experiments demonstrate the effectiveness of the proposed framework on datasets derived from moral theories. Furthermore, we show the alignment between different moral theories and existing morality datasets. Our analysis exhibits the potentials and flaws in existing resources (models and datasets) in developing explainable moral judgment-making systems.