 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRIGHT: A Collaborative Generalist-Specialist Foundation Model for Breast Pathology
Mar 03, 2026Generalist pathology foundation models (PFMs), pretrained on large-scale multi-organ datasets, have demonstrated remarkable predictive capabilities across diverse clinical applications. However, their proficiency on the full spectrum of clinically essential tasks within a specific organ system remains an open question due to the lack of large-scale validation cohorts for a single organ as well as the absence of a tailored training paradigm that can effectively translate broad histomorphological knowledge into the organ-specific expertise required for specialist-level interpretation. In this study, we propose BRIGHT, the first PFM specifically designed for breast pathology, trained on approximately 210 million histopathology tiles from over 51,000 breast whole-slide images derived from a cohort of over 40,000 patients across 19 hospitals. BRIGHT employs a collaborative generalist-specialist framework to capture both universal and organ-specific features. To comprehensively evaluate the performance of PFMs on breast oncology, we curate the largest multi-institutional cohorts to date for downstream task development and evaluation, comprising over 25,000 WSIs across 10 hospitals. The validation cohorts cover the full spectrum of breast pathology across 24 distinct clinical tasks spanning diagnosis, biomarker prediction, treatment response and survival prediction. Extensive experiments demonstrate that BRIGHT outperforms three leading generalist PFMs, achieving state-of-the-art (SOTA) performance in 21 of 24 internal validation tasks and in 5 of 10 external validation tasks with excellent heatmap interpretability. By evaluating on large-scale validation cohorts, this study not only demonstrates BRIGHT's clinical utility in breast oncology but also validates a collaborative generalist-specialist paradigm, providing a scalable template for developing PFMs on a specific organ system.
TreePS-RAG: Tree-based Process Supervision for Reinforcement Learning in Agentic RAG
Jan 11, 2026Agentic retrieval-augmented generation (RAG) formulates question answering as a multi-step interaction between reasoning and information retrieval, and has recently been advanced by reinforcement learning (RL) with outcome-based supervision. While effective, relying solely on sparse final rewards limits step-wise credit assignment and provides weak guidance for intermediate reasoning and actions. Recent efforts explore process-level supervision, but typically depend on offline constructed training data, which risks distribution shift, or require costly intermediate annotations. We present TreePS-RAG, an online, tree-based RL framework for agentic RAG that enables step-wise credit assignment while retaining standard outcome-only rewards. Our key insight is to model agentic RAG reasoning as a rollout tree, where each reasoning step naturally maps to a node. This tree structure allows step utility to be estimated via Monte Carlo estimation over its descendant outcomes, yielding fine-grained process advantages without requiring intermediate labels. To make this paradigm practical, we introduce an efficient online tree construction strategy that preserves exploration diversity under a constrained computational budget. With a rollout cost comparable to strong baselines like Search-R1, experiments on seven multi-hop and general QA benchmarks across multiple model scales show that TreePS-RAG consistently and significantly outperforms both outcome-supervised and leading process-supervised RL methods.
MMSU: A Massive Multi-task Spoken Language Understanding and Reasoning Benchmark
Jun 05, 2025Speech inherently contains rich acoustic information that extends far beyond the textual language. In real-world spoken language understanding, effective interpretation often requires integrating semantic meaning (e.g., content), paralinguistic features (e.g., emotions, speed, pitch) and phonological characteristics (e.g., prosody, intonation, rhythm), which are embedded in speech. While recent multimodal Speech Large Language Models (SpeechLLMs) have demonstrated remarkable capabilities in processing audio information, their ability to perform fine-grained perception and complex reasoning in natural speech remains largely unexplored. To address this gap, we introduce MMSU, a comprehensive benchmark designed specifically for understanding and reasoning in spoken language. MMSU comprises 5,000 meticulously curated audio-question-answer triplets across 47 distinct tasks. To ground our benchmark in linguistic theory, we systematically incorporate a wide range of linguistic phenomena, including phonetics, prosody, rhetoric, syntactics, semantics, and paralinguistics. Through a rigorous evaluation of 14 advanced SpeechLLMs, we identify substantial room for improvement in existing models, highlighting meaningful directions for future optimization. MMSU establishes a new standard for comprehensive assessment of spoken language understanding, providing valuable insights for developing more sophisticated human-AI speech interaction systems. MMSU benchmark is available at https://huggingface.co/datasets/ddwang2000/MMSU. Evaluation Code is available at https://github.com/dingdongwang/MMSU_Bench.
RAG-Zeval: Towards Robust and Interpretable Evaluation on RAG Responses through End-to-End Rule-Guided Reasoning
May 28, 2025



Robust evaluation is critical for deploying trustworthy retrieval-augmented generation (RAG) systems. However, current LLM-based evaluation frameworks predominantly rely on directly prompting resource-intensive models with complex multi-stage prompts, underutilizing models' reasoning capabilities and introducing significant computational cost. In this paper, we present RAG-Zeval (RAG-Zero Evaluator), a novel end-to-end framework that formulates faithfulness and correctness evaluation as a rule-guided reasoning task. Our approach trains evaluators with reinforcement learning, facilitating compact models to generate comprehensive and sound assessments with detailed explanation in one-pass. We introduce a ranking-based outcome reward mechanism, using preference judgments rather than absolute scores, to address the challenge of obtaining precise pointwise reward signals. To this end, we synthesize the ranking references by generating quality-controlled responses with zero human annotation. Experiments demonstrate RAG-Zeval's superior performance, achieving the strongest correlation with human judgments and outperforming baselines that rely on LLMs with 10-100 times more parameters. Our approach also exhibits superior interpretability in response evaluation.
Generate, Discriminate, Evolve: Enhancing Context Faithfulness via Fine-Grained Sentence-Level Self-Evolution
Mar 03, 2025



Improving context faithfulness in large language models is essential for developing trustworthy retrieval augmented generation systems and mitigating hallucinations, especially in long-form question answering (LFQA) tasks or scenarios involving knowledge conflicts. Existing methods either intervene LLMs only at inference without addressing their inherent limitations or overlook the potential for self-improvement. In this paper, we introduce GenDiE (Generate, Discriminate, Evolve), a novel self-evolving framework that enhances context faithfulness through fine-grained sentence-level optimization. GenDiE combines both generative and discriminative training, equipping LLMs with self-generation and self-scoring capabilities to facilitate iterative self-evolution. This supports both data construction for model alignment and score-guided search during inference. Furthermore, by treating each sentence in a response as an independent optimization unit, GenDiE effectively addresses the limitations of previous approaches that optimize at the holistic answer level, which may miss unfaithful details. Experiments on ASQA (in-domain LFQA) and ConFiQA (out-of-domain counterfactual QA) datasets demonstrate that GenDiE surpasses various baselines in both faithfulness and correctness, and exhibits robust performance for domain adaptation.
Decoding on Graphs: Faithful and Sound Reasoning on Knowledge Graphs through Generation of Well-Formed Chains
Oct 24, 2024



Knowledge Graphs (KGs) can serve as reliable knowledge sources for question answering (QA) due to their structured representation of knowledge. Existing research on the utilization of KG for large language models (LLMs) prevalently relies on subgraph retriever or iterative prompting, overlooking the potential synergy of LLMs' step-wise reasoning capabilities and KGs' structural nature. In this paper, we present DoG (Decoding on Graphs), a novel framework that facilitates a deep synergy between LLMs and KGs. We first define a concept, well-formed chain, which consists of a sequence of interrelated fact triplets on the KGs, starting from question entities and leading to answers. We argue that this concept can serve as a principle for making faithful and sound reasoning for KGQA. To enable LLMs to generate well-formed chains, we propose graph-aware constrained decoding, in which a constraint derived from the topology of the KG regulates the decoding process of the LLMs. This constrained decoding method ensures the generation of well-formed chains while making full use of the step-wise reasoning capabilities of LLMs. Based on the above, DoG, a training-free approach, is able to provide faithful and sound reasoning trajectories grounded on the KGs. Experiments across various KGQA tasks with different background KGs demonstrate that DoG achieves superior and robust performance. DoG also shows general applicability with various open-source LLMs.
Adaptive Query Rewriting: Aligning Rewriters through Marginal Probability of Conversational Answers
Jun 16, 2024Query rewriting is a crucial technique for passage retrieval in open-domain conversational question answering (CQA). It decontexualizes conversational queries into self-contained questions suitable for off-the-shelf retrievers. Existing methods attempt to incorporate retriever's preference during the training of rewriting models. However, these approaches typically rely on extensive annotations such as in-domain rewrites and/or relevant passage labels, limiting the models' generalization and adaptation capabilities. In this paper, we introduce AdaQR ($\textbf{Ada}$ptive $\textbf{Q}$uery $\textbf{R}$ewriting), a framework for training query rewriting models with limited rewrite annotations from seed datasets and completely no passage label. Our approach begins by fine-tuning compact large language models using only ~$10\%$ of rewrite annotations from the seed dataset training split. The models are then utilized to generate rewrite candidates for each query instance. A novel approach is then proposed to assess retriever's preference for these candidates by the probability of answers conditioned on the conversational query by marginalizing the Top-$K$ passages. This serves as the reward for optimizing the rewriter further using Direct Preference Optimization (DPO), a process free of rewrite and retrieval annotations. Experimental results on four open-domain CQA datasets demonstrate that AdaQR not only enhances the in-domain capabilities of the rewriter with limited annotation requirement, but also adapts effectively to out-of-domain datasets.
Self-DC: When to retrieve and When to generate? Self Divide-and-Conquer for Compositional Unknown Questions
Feb 21, 2024



Retrieve-then-read and generate-then-read are two typical solutions to handle unknown and known questions in open-domain question-answering, while the former retrieves necessary external knowledge and the later prompt the large language models to generate internal known knowledge encoded in the parameters. However, few of previous works consider the compositional unknown questions, which consist of several known or unknown sub-questions. Thus, simple binary classification (known or unknown) becomes sub-optimal and inefficient since it will call external retrieval excessively for each compositional unknown question. To this end, we propose the first Compositional unknown Question-Answering dataset (CuQA), and introduce a Self Divide-and-Conquer (Self-DC) framework to empower LLMs to adaptively call different methods on-demand, resulting in better performance and efficiency. Experimental results on two datasets (CuQA and FreshQA) demonstrate that Self-DC can achieve comparable or even better performance with much more less retrieval times compared with several strong baselines.
Natural Language Embedded Programs for Hybrid Language Symbolic Reasoning
Sep 19, 2023How can we perform computations over natural language representations to solve tasks that require symbolic and numeric reasoning? We propose natural language embedded programs (NLEP) as a unifying framework for addressing math/symbolic reasoning, natural language understanding, and instruction following tasks. Our approach prompts a language model to generate full Python programs that define functions over data structures which contain natural language representations of structured knowledge. A Python interpreter then executes the generated code and prints the output. Despite using a task-general prompt, we find that this approach can improve upon strong baselines across a range of different tasks including math and symbolic reasoning, text classification, question answering, and instruction following. We further find the generated programs are often interpretable and enable post-hoc verification of the intermediate reasoning steps.
SAIL: Search-Augmented Instruction Learning
May 24, 2023


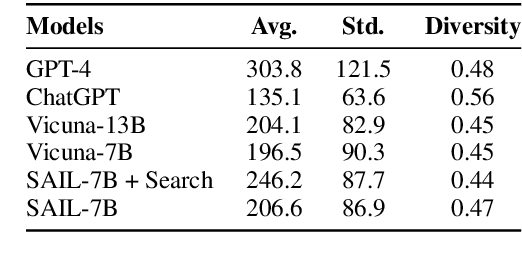
Large language models (LLMs) have been significantly improved by instruction fine-tuning, but still lack transparency and the ability to utilize up-to-date knowledge and information. In this work, we propose search-augmented instruction learning (SAIL), which grounds the language generation and instruction following abilities on complex search results generated by in-house and external search engines. With an instruction tuning corpus, we collect search results for each training case from different search APIs and domains, and construct a new search-grounded training set containing \textit{(instruction, grounding information, response)} triplets. We then fine-tune the LLaMA-7B model on the constructed training set. Since the collected results contain unrelated and disputing languages, the model needs to learn to ground on trustworthy search results, filter out distracting passages, and generate the target response. The search result-denoising process entails explicit trustworthy information selection and multi-hop reasoning, since the retrieved passages might be informative but not contain the instruction-following answer. Experiments show that the fine-tuned SAIL-7B model has a strong instruction-following ability, and it performs significantly better on transparency-sensitive tasks, including open-ended question answering and fact checking.