 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Supervised Poison Vulnerability to Strengthen Self-Supervised Defense
Sep 13, 2024Availability poisons exploit supervised learning (SL) algorithms by introducing class-related shortcut features in images such that models trained on poisoned data are useless for real-world datasets. Self-supervised learning (SSL), which utilizes augmentations to learn instance discrimination, is regarded as a strong defense against poisoned data. However, by extending the study of SSL across multiple poisons on the CIFAR-10 and ImageNet-100 datasets, we demonstrate that it often performs poorly, far below that of training on clean data. Leveraging the vulnerability of SL to poison attacks, we introduce adversarial training (AT) on SL to obfuscate poison features and guide robust feature learning for SSL. Our proposed defense, designated VESPR (Vulnerability Exploitation of Supervised Poisoning for Robust SSL), surpasses the performance of six previous defenses across seven popular availability poisons. VESPR displays superior performance over all previous defenses, boosting the minimum and average ImageNet-100 test accuracies of poisoned models by 16% and 9%, respectively. Through analysis and ablation studies, we elucidate the mechanisms by which VESPR learns robust class features.
Unstructured Knowledge Access in Task-oriented Dialog Modeling using Language Inference, Knowledge Retrieval and Knowledge-Integrative Response Generation
Jan 15, 2021
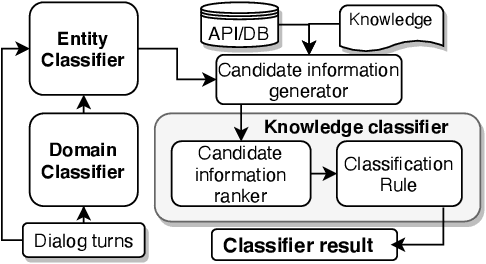

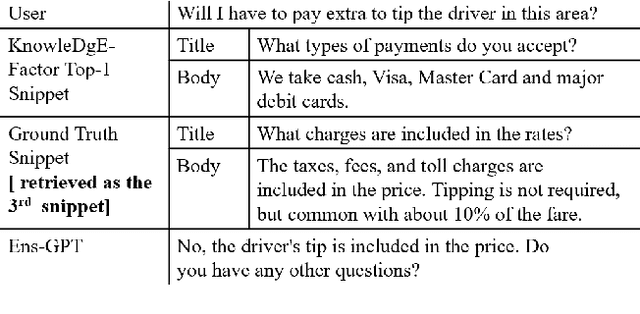
Dialog systems enriched with external knowledge can handle user queries that are outside the scope of the supporting databases/APIs. In this paper, we follow the baseline provided in DSTC9 Track 1 and propose three subsystems, KDEAK, KnowleDgEFactor, and Ens-GPT, which form the pipeline for a task-oriented dialog system capable of accessing unstructured knowledge. Specifically, KDEAK performs knowledge-seeking turn detection by formulating the problem as natural language inference using knowledge from dialogs, databases and FAQs. KnowleDgEFactor accomplishes the knowledge selection task by formulating a factorized knowledge/document retrieval problem with three modules performing domain, entity and knowledge level analyses. Ens-GPT generates a response by first processing multiple knowledge snippets, followed by an ensemble algorithm that decides if the response should be solely derived from a GPT2-XL model, or regenerated in combination with the top-ranking knowledge snippet. Experimental results demonstrate that the proposed pipeline system outperforms the baseline and generates high-quality responses, achieving at least 58.77% improvement on BLEU-4 score.