 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Structure Guided Transformer for Source Code Summarization
Apr 19, 2021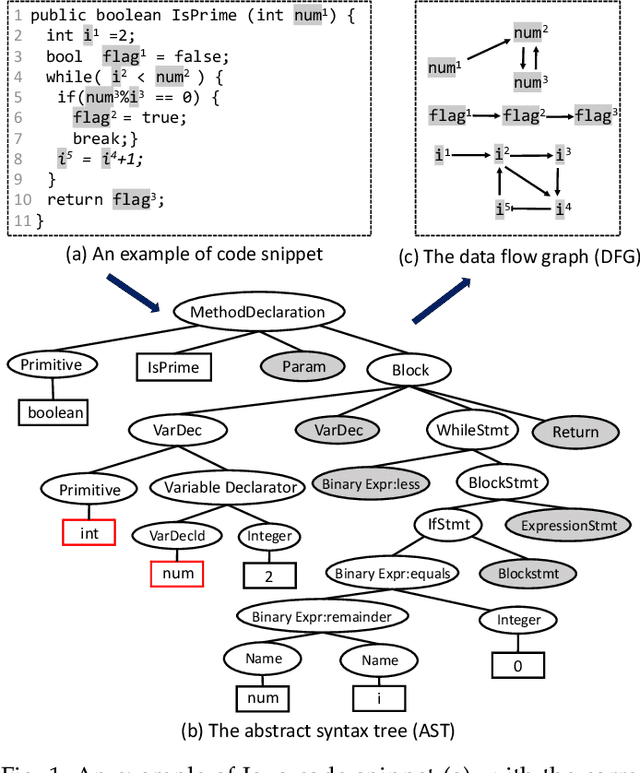
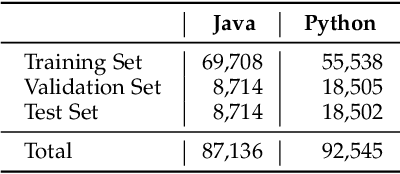
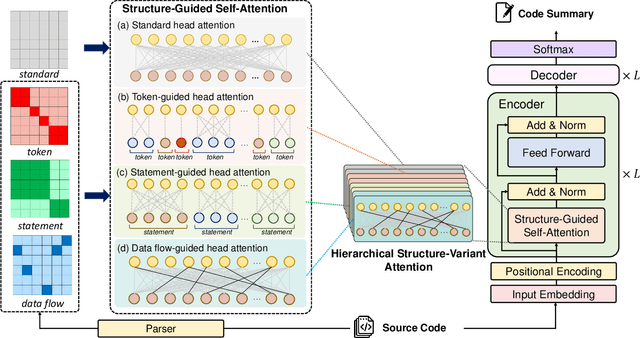
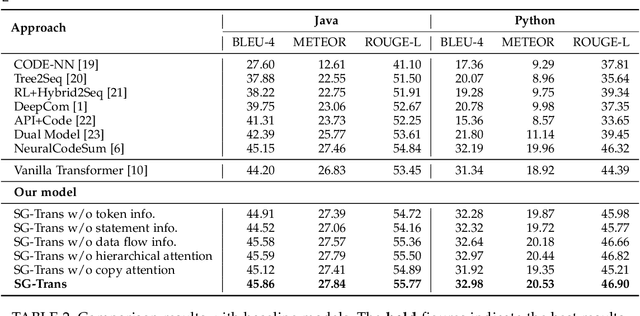
Source code summarization aims at generating concise descriptions of given programs' functionalities. While Transformer-based approaches achieve promising performance, they do not explicitly incorporate the code structure information which is important for capturing code semantics. Besides, without explicit constraints, multi-head attentions in Transformer may suffer from attention collapse, leading to poor code representations for summarization. Effectively integrating the code structure information into Transformer is under-explored in this task domain. In this paper, we propose a novel approach named SG-Trans to incorporate code structural properties into Transformer. Specifically, to capture the hierarchical characteristics of code, we inject the local symbolic information (e.g., code tokens) and global syntactic structure (e.g., data flow) into the self-attention module as inductive bias. Extensive evaluation shows the superior performance of SG-Trans over the state-of-the-art approaches.
Unstructured Knowledge Access in Task-oriented Dialog Modeling using Language Inference, Knowledge Retrieval and Knowledge-Integrative Response Generation
Jan 15, 2021
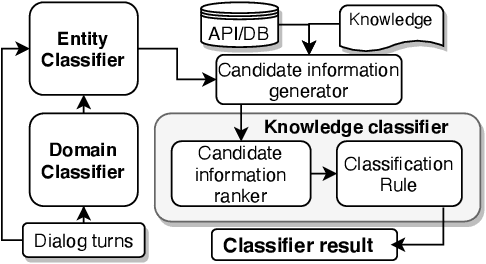

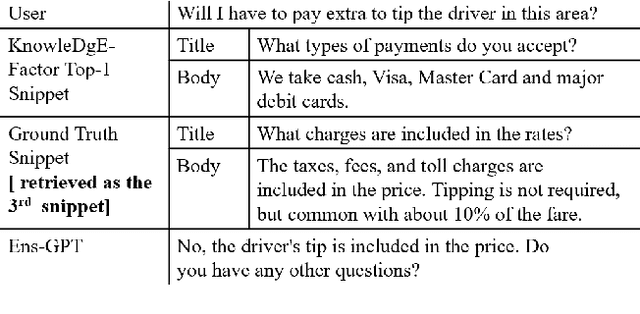
Dialog systems enriched with external knowledge can handle user queries that are outside the scope of the supporting databases/APIs. In this paper, we follow the baseline provided in DSTC9 Track 1 and propose three subsystems, KDEAK, KnowleDgEFactor, and Ens-GPT, which form the pipeline for a task-oriented dialog system capable of accessing unstructured knowledge. Specifically, KDEAK performs knowledge-seeking turn detection by formulating the problem as natural language inference using knowledge from dialogs, databases and FAQs. KnowleDgEFactor accomplishes the knowledge selection task by formulating a factorized knowledge/document retrieval problem with three modules performing domain, entity and knowledge level analyses. Ens-GPT generates a response by first processing multiple knowledge snippets, followed by an ensemble algorithm that decides if the response should be solely derived from a GPT2-XL model, or regenerated in combination with the top-ranking knowledge snippet. Experimental results demonstrate that the proposed pipeline system outperforms the baseline and generates high-quality responses, achieving at least 58.77% improvement on BLEU-4 score.
Contextualized Code Representation Learning for Commit Message Generation
Jul 14, 2020
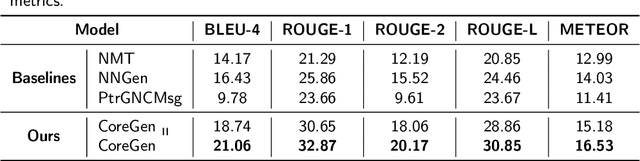
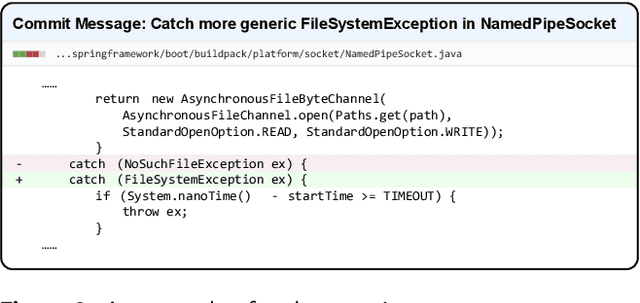
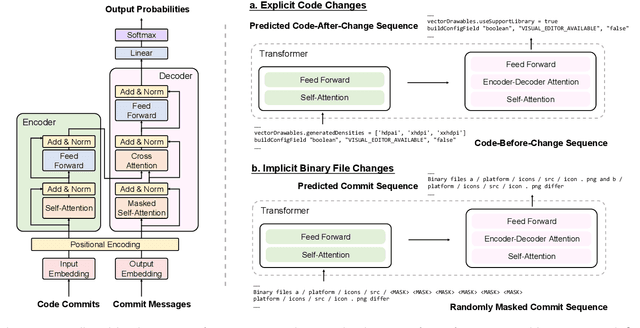
Automatic generation of high-quality commit messages for code commits can substantially facilitate developers' works and coordination. However, the semantic gap between source code and natural language poses a major challenge for the task. Several studies have been proposed to alleviate the challenge but none explicitly involves code contextual information during commit message generation. Specifically, existing research adopts static embedding for code tokens, which maps a token to the same vector regardless of its context. In this paper, we propose a novel Contextualized code representation learning method for commit message Generation (CoreGen). CoreGen first learns contextualized code representation which exploits the contextual information behind code commit sequences. The learned representations of code commits built upon Transformer are then transferred for downstream commit message generation. Experiments on the benchmark dataset demonstrate the superior effectiveness of our model over the baseline models with an improvement of 28.18% in terms of BLEU-4 score. Furthermore, we also highlight the future opportunities in training contextualized code representations on larger code corpus as a solution to low-resource settings and adapting the pretrained code representations to other downstream code-to-text generation tasks.