 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Inclusion Hypothesis and Quantifications: Probing Hypernymy in Functional Distributional Semantics
Sep 15, 2023Functional Distributional Semantics (FDS) models the meaning of words by truth-conditional functions. This provides a natural representation for hypernymy, but no guarantee that it is learnt when FDS models are trained on a corpus. We demonstrate that FDS models learn hypernymy when a corpus strictly follows the Distributional Inclusion Hypothesis. We further introduce a training objective that allows FDS to handle simple universal quantifications, thus enabling hypernymy learning under the reverse of DIH. Experimental results on both synthetic and real data sets confirm our hypotheses and the effectiveness of our proposed objective.
Unstructured Knowledge Access in Task-oriented Dialog Modeling using Language Inference, Knowledge Retrieval and Knowledge-Integrative Response Generation
Jan 15, 2021
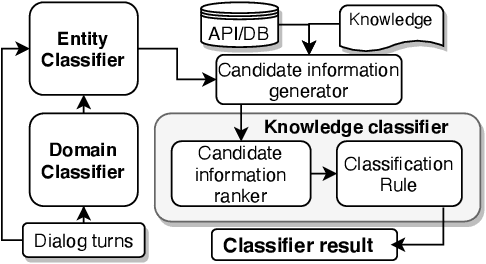

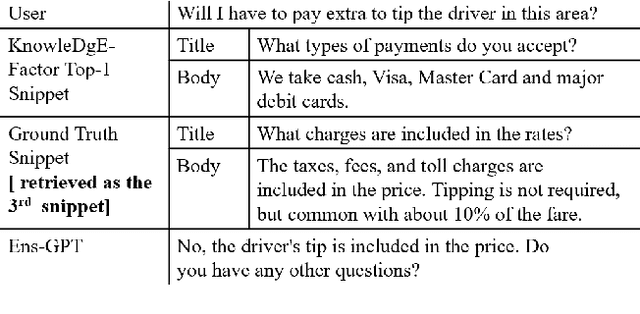
Dialog systems enriched with external knowledge can handle user queries that are outside the scope of the supporting databases/APIs. In this paper, we follow the baseline provided in DSTC9 Track 1 and propose three subsystems, KDEAK, KnowleDgEFactor, and Ens-GPT, which form the pipeline for a task-oriented dialog system capable of accessing unstructured knowledge. Specifically, KDEAK performs knowledge-seeking turn detection by formulating the problem as natural language inference using knowledge from dialogs, databases and FAQs. KnowleDgEFactor accomplishes the knowledge selection task by formulating a factorized knowledge/document retrieval problem with three modules performing domain, entity and knowledge level analyses. Ens-GPT generates a response by first processing multiple knowledge snippets, followed by an ensemble algorithm that decides if the response should be solely derived from a GPT2-XL model, or regenerated in combination with the top-ranking knowledge snippet. Experimental results demonstrate that the proposed pipeline system outperforms the baseline and generates high-quality responses, achieving at least 58.77% improvement on BLEU-4 score.