 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeguarding Text-to-Image Generative Models Against Unauthorized Knowledge Distillation
May 21, 2026Closed-weight generative services are increasingly deployed through query-based APIs, where users can obtain generated outputs while model parameters remain inaccessible. However, such deployment does not prevent model stealing: an attacker can repeatedly query the service, collect large volumes of released synthetic images, and use them as training data for a private substitute model. This query-output-driven process enables unauthorized knowledge distillation and capability replication without direct access to the original weights. To mitigate this threat, a practical defense should preserve the visual fidelity of released images, provide explicit control over perturbation magnitude, and scale efficiently to large-volume output release. We present WaveGuard, a single-pass, generator-based protection framework that safeguards released synthetic images under a user-specified perturbation budget. WaveGuard employs a frequency-aware perturbation generator to inject structured, imperceptible perturbations that maintain perceptual utility for benign viewers while reducing the usefulness of protected images as training data for unauthorized student models. Extensive experiments under WikiArt-related synthetic-output distillation settings show that WaveGuard achieves a favorable efficacy--fidelity--efficiency trade-off, with explicit imperceptibility control and substantial gains in protection efficiency.
Explore How to Inject Beneficial Noise in MLLMs
Nov 17, 2025Multimodal Large Language Models (MLLMs) have played an increasingly important role in multimodal intelligence. However, the existing fine-tuning methods often ignore cross-modal heterogeneity, limiting their full potential. In this work, we propose a novel fine-tuning strategy by injecting beneficial random noise, which outperforms previous methods and even surpasses full fine-tuning, with minimal additional parameters. The proposed Multimodal Noise Generator (MuNG) enables efficient modality fine-tuning by injecting customized noise into the frozen MLLMs. Specifically, we reformulate the reasoning process of MLLMs from a variational inference perspective, upon which we design a multimodal noise generator that dynamically analyzes cross-modal relationships in image-text pairs to generate task-adaptive beneficial noise. Injecting this type of noise into the MLLMs effectively suppresses irrelevant semantic components, leading to significantly improved cross-modal representation alignment and enhanced performance on downstream tasks. Experiments on two mainstream MLLMs, QwenVL and LLaVA, demonstrate that our method surpasses full-parameter fine-tuning and other existing fine-tuning approaches, while requiring adjustments to only about $1\sim2\%$ additional parameters. The relevant code is uploaded in the supplementary.
Rectified Noise: A Generative Model Using Positive-incentive Noise
Nov 12, 2025Rectified Flow (RF) has been widely used as an effective generative model. Although RF is primarily based on probability flow Ordinary Differential Equations (ODE), recent studies have shown that injecting noise through reverse-time Stochastic Differential Equations (SDE) for sampling can achieve superior generative performance. Inspired by Positive-incentive Noise (pi-noise), we propose an innovative generative algorithm to train pi-noise generators, namely Rectified Noise (RN), which improves the generative performance by injecting pi-noise into the velocity field of pre-trained RF models. After introducing the Rectified Noise pipeline, pre-trained RF models can be efficiently transformed into pi-noise generators. We validate Rectified Noise by conducting extensive experiments across various model architectures on different datasets. Notably, we find that: (1) RF models using Rectified Noise reduce FID from 10.16 to 9.05 on ImageNet-1k. (2) The models of pi-noise generators achieve improved performance with only 0.39% additional training parameters.
Laytrol: Preserving Pretrained Knowledge in Layout Control for Multimodal Diffusion Transformers
Nov 11, 2025With the development of diffusion models, enhancing spatial controllability in text-to-image generation has become a vital challenge. As a representative task for addressing this challenge, layout-to-image generation aims to generate images that are spatially consistent with the given layout condition. Existing layout-to-image methods typically introduce the layout condition by integrating adapter modules into the base generative model. However, the generated images often exhibit low visual quality and stylistic inconsistency with the base model, indicating a loss of pretrained knowledge. To alleviate this issue, we construct the Layout Synthesis (LaySyn) dataset, which leverages images synthesized by the base model itself to mitigate the distribution shift from the pretraining data. Moreover, we propose the Layout Control (Laytrol) Network, in which parameters are inherited from MM-DiT to preserve the pretrained knowledge of the base model. To effectively activate the copied parameters and avoid disturbance from unstable control conditions, we adopt a dedicated initialization scheme for Laytrol. In this scheme, the layout encoder is initialized as a pure text encoder to ensure that its output tokens remain within the data domain of MM-DiT. Meanwhile, the outputs of the layout control network are initialized to zero. In addition, we apply Object-level Rotary Position Embedding to the layout tokens to provide coarse positional information. Qualitative and quantitative experiments demonstrate the effectiveness of our method.
CoLM: Collaborative Large Models via A Client-Server Paradigm
Nov 10, 2025Large models have achieved remarkable performance across a range of reasoning and understanding tasks. Prior work often utilizes model ensembles or multi-agent systems to collaboratively generate responses, effectively operating in a server-to-server paradigm. However, such approaches do not align well with practical deployment settings, where a limited number of server-side models are shared by many clients under modern internet architectures. In this paper, we introduce \textbf{CoLM} (\textbf{Co}llaboration in \textbf{L}arge-\textbf{M}odels), a novel framework for collaborative reasoning that redefines cooperation among large models from a client-server perspective. Unlike traditional ensemble methods that rely on simultaneous inference from multiple models to produce a single output, CoLM allows the outputs of multiple models to be aggregated or shared, enabling each client model to independently refine and update its own generation based on these high-quality outputs. This design enables collaborative benefits by fully leveraging both client-side and shared server-side models. We further extend CoLM to vision-language models (VLMs), demonstrating its applicability beyond language tasks. Experimental results across multiple benchmarks show that CoLM consistently improves model performance on previously failed queries, highlighting the effectiveness of collaborative guidance in enhancing single-model capabilities.
AI Flow: Perspectives, Scenarios, and Approaches
Jun 14, 2025Pioneered by the foundational information theory by Claude Shannon and the visionary framework of machine intelligence by Alan Turing, the convergent evolution of information and communication technologies (IT/CT) has created an unbroken wave of connectivity and computation. This synergy has sparked a technological revolution, now reaching its peak with large artificial intelligence (AI) models that are reshaping industries and redefining human-machine collaboration. However, the realization of ubiquitous intelligence faces considerable challenges due to substantial resource consumption in large models and high communication bandwidth demands. To address these challenges, AI Flow has been introduced as a multidisciplinary framework that integrates cutting-edge IT and CT advancements, with a particular emphasis on the following three key points. First, device-edge-cloud framework serves as the foundation, which integrates end devices, edge servers, and cloud clusters to optimize scalability and efficiency for low-latency model inference. Second, we introduce the concept of familial models, which refers to a series of different-sized models with aligned hidden features, enabling effective collaboration and the flexibility to adapt to varying resource constraints and dynamic scenarios. Third, connectivity- and interaction-based intelligence emergence is a novel paradigm of AI Flow. By leveraging communication networks to enhance connectivity, the collaboration among AI models across heterogeneous nodes achieves emergent intelligence that surpasses the capability of any single model. The innovations of AI Flow provide enhanced intelligence, timely responsiveness, and ubiquitous accessibility to AI services, paving the way for the tighter fusion of AI techniques and communication systems.
Enhance Vision-Language Alignment with Noise
Dec 17, 2024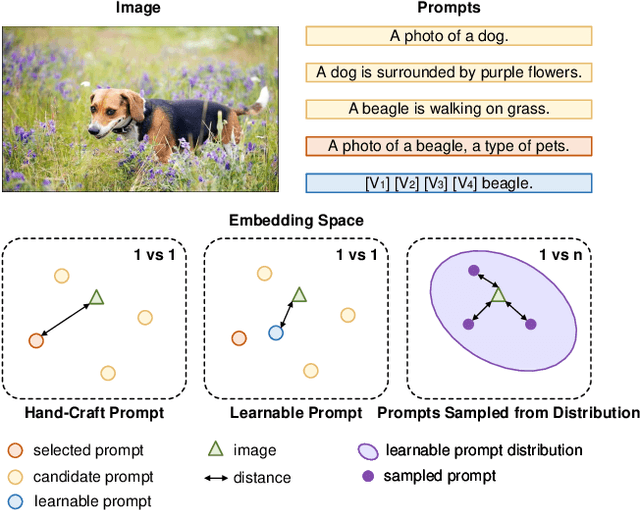
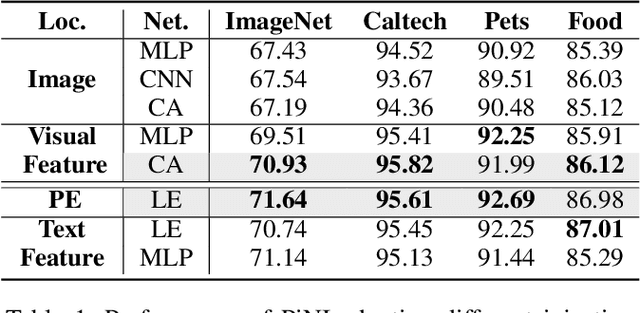

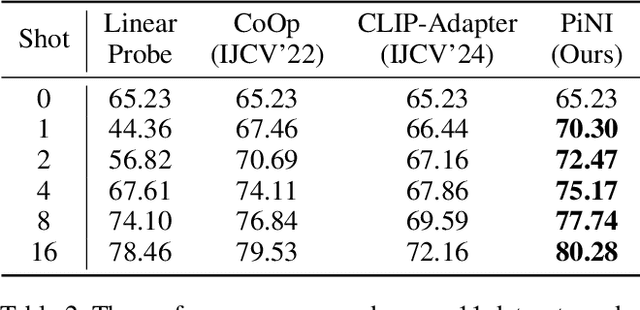
With the advancement of pre-trained vision-language (VL) models, enhancing the alignment between visual and linguistic modalities in downstream tasks has emerged as a critical challenge. Different from existing fine-tuning methods that add extra modules to these two modalities, we investigate whether the frozen model can be fine-tuned by customized noise. Our approach is motivated by the scientific study of beneficial noise, namely Positive-incentive Noise (Pi-noise or $\pi$-noise) , which quantitatively analyzes the impact of noise. It therefore implies a new scheme to learn beneficial noise distribution that can be employed to fine-tune VL models. Focusing on few-shot classification tasks based on CLIP, we reformulate the inference process of CLIP and apply variational inference, demonstrating how to generate $\pi$-noise towards visual and linguistic modalities. Then, we propose Positive-incentive Noise Injector (PiNI), which can fine-tune CLIP via injecting noise into both visual and text encoders. Since the proposed method can learn the distribution of beneficial noise, we can obtain more diverse embeddings of vision and language to better align these two modalities for specific downstream tasks within limited computational resources. We evaluate different noise incorporation approaches and network architectures of PiNI. The evaluation across 11 datasets demonstrates its effectiveness.
Deep Learning Based Solar Cell Recognition for Optical Wireless Power Transfer
Oct 18, 2024
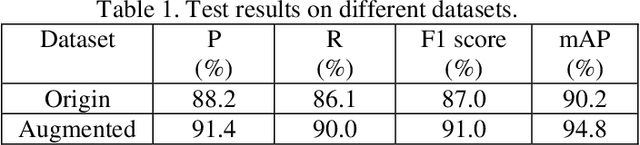
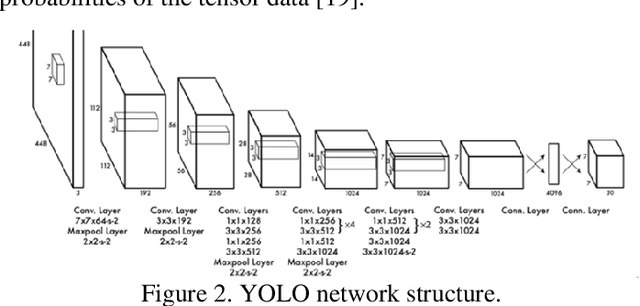

Optical wireless power transfer (OWPT) is a technology that wirelessly transmit light energy from an optical transmitter to an optical receiver, usually a solar cell. In order to achieve the highest transmission efficiency, the solar cell receiver should be accurately aligned with the optical transmitter. Hitherto, only a few works have been existed for solar cell recognition in presence of complex backgrounds. In this paper, we employ a deep learning approach based on Yolov5-Lite for the solar cell recognition purpose, due to its lightweight, fast and easy to deploy on hardware characteristics. Our tests show a high accuracy of the employed deep learning model with the highest F1 score of 91% and mAP of 94.8%. Therefore, this deep learning model is highly promising for use in OWPT systems to precisely align optical transmitters and solar cell receivers.
Data Augmentation of Contrastive Learning is Estimating Positive-incentive Noise
Aug 19, 2024Inspired by the idea of Positive-incentive Noise (Pi-Noise or $\pi$-Noise) that aims at learning the reliable noise beneficial to tasks, we scientifically investigate the connection between contrastive learning and $\pi$-noise in this paper. By converting the contrastive loss to an auxiliary Gaussian distribution to quantitatively measure the difficulty of the specific contrastive model under the information theory framework, we properly define the task entropy, the core concept of $\pi$-noise, of contrastive learning. It is further proved that the predefined data augmentation in the standard contrastive learning paradigm can be regarded as a kind of point estimation of $\pi$-noise. Inspired by the theoretical study, a framework that develops a $\pi$-noise generator to learn the beneficial noise (instead of estimation) as data augmentations for contrast is proposed. The designed framework can be applied to diverse types of data and is also completely compatible with the existing contrastive models. From the visualization, we surprisingly find that the proposed method successfully learns effective augmentations.
Variational Positive-incentive Noise: How Noise Benefits Models
Jun 13, 2023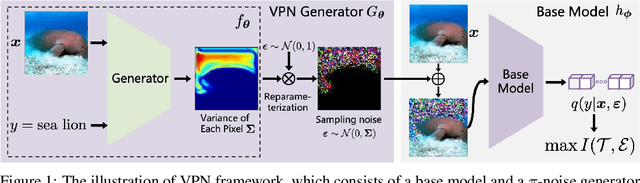
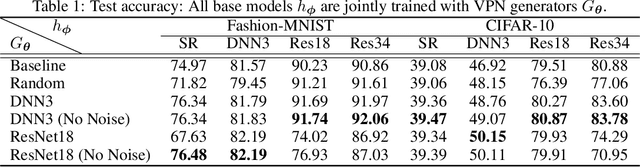
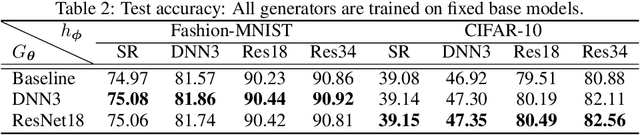
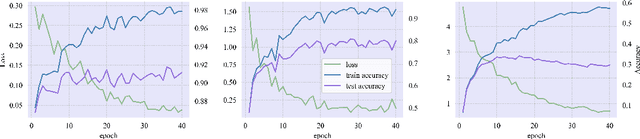
A large number of works aim to alleviate the impact of noise due to an underlying conventional assumption of the negative role of noise. However, some existing works show that the assumption does not always hold. In this paper, we investigate how to benefit the classical models by random noise under the framework of Positive-incentive Noise (Pi-Noise). Since the ideal objective of Pi-Noise is intractable, we propose to optimize its variational bound instead, namely variational Pi-Noise (VPN). With the variational inference, a VPN generator implemented by neural networks is designed for enhancing base models and simplifying the inference of base models, without changing the architecture of base models. Benefiting from the independent design of base models and VPN generators, the VPN generator can work with most existing models. From the experiments, it is shown that the proposed VPN generator can improve the base models. It is appealing that the trained variational VPN generator prefers to blur the irrelevant ingredients in complicated images, which meets our expectations.