 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRectified Noise: A Generative Model Using Positive-incentive Noise
Nov 12, 2025Rectified Flow (RF) has been widely used as an effective generative model. Although RF is primarily based on probability flow Ordinary Differential Equations (ODE), recent studies have shown that injecting noise through reverse-time Stochastic Differential Equations (SDE) for sampling can achieve superior generative performance. Inspired by Positive-incentive Noise (pi-noise), we propose an innovative generative algorithm to train pi-noise generators, namely Rectified Noise (RN), which improves the generative performance by injecting pi-noise into the velocity field of pre-trained RF models. After introducing the Rectified Noise pipeline, pre-trained RF models can be efficiently transformed into pi-noise generators. We validate Rectified Noise by conducting extensive experiments across various model architectures on different datasets. Notably, we find that: (1) RF models using Rectified Noise reduce FID from 10.16 to 9.05 on ImageNet-1k. (2) The models of pi-noise generators achieve improved performance with only 0.39% additional training parameters.
Yi: Open Foundation Models by 01.AI
Mar 07, 2024



We introduce the Yi model family, a series of language and multimodal models that demonstrate strong multi-dimensional capabilities. The Yi model family is based on 6B and 34B pretrained language models, then we extend them to chat models, 200K long context models, depth-upscaled models, and vision-language models. Our base models achieve strong performance on a wide range of benchmarks like MMLU, and our finetuned chat models deliver strong human preference rate on major evaluation platforms like AlpacaEval and Chatbot Arena. Building upon our scalable super-computing infrastructure and the classical transformer architecture, we attribute the performance of Yi models primarily to its data quality resulting from our data-engineering efforts. For pretraining, we construct 3.1 trillion tokens of English and Chinese corpora using a cascaded data deduplication and quality filtering pipeline. For finetuning, we polish a small scale (less than 10K) instruction dataset over multiple iterations such that every single instance has been verified directly by our machine learning engineers. For vision-language, we combine the chat language model with a vision transformer encoder and train the model to align visual representations to the semantic space of the language model. We further extend the context length to 200K through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance. We show that extending the depth of the pretrained checkpoint through continual pretraining further improves performance. We believe that given our current results, continuing to scale up model parameters using thoroughly optimized data will lead to even stronger frontier models.
Energon: Towards Efficient Acceleration of Transformers Using Dynamic Sparse Attention
Oct 18, 2021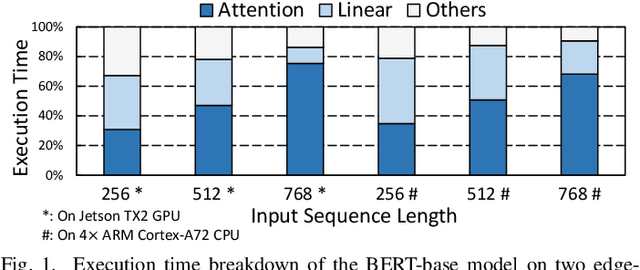



In recent years, transformer models have revolutionized Natural Language Processing (NLP) and also show promising performance on Computer Vision (CV) tasks. Despite their effectiveness, transformers' attention operations are hard to accelerate due to complicated data movement and quadratic computational complexity, prohibiting the real-time inference on resource-constrained edge-computing platforms. To tackle this challenge, we propose Energon, an algorithm-architecture co-design approach that accelerates various transformers using dynamic sparse attention. With the observation that attention results only depend on a few important query-key pairs, we propose a multi-round filtering algorithm to dynamically identify such pairs at runtime. We adopt low bitwidth in each filtering round and only use high-precision tensors in the attention stage to reduce overall complexity. By this means, we significantly mitigate the computational cost with negligible accuracy loss. To enable such an algorithm with lower latency and better energy-efficiency, we also propose an Energon co-processor architecture. Elaborated pipelines and specialized optimizations jointly boost the performance and reduce power consumption. Extensive experiments on both NLP and CV benchmarks demonstrate that Energon achieves $161\times$ and $8.4\times$ geo-mean speedup and up to $10^4\times$ and $10^3\times$ energy reduction compared with Intel Xeon 5220 CPU and NVIDIA V100 GPU. Compared to state-of-the-art attention accelerators SpAtten and $A^3$, Energon also achieves $1.7\times, 1.25\times$ speedup and $1.6 \times, 1.5\times $ higher energy efficiency.
Distribution Adaptive INT8 Quantization for Training CNNs
Feb 09, 2021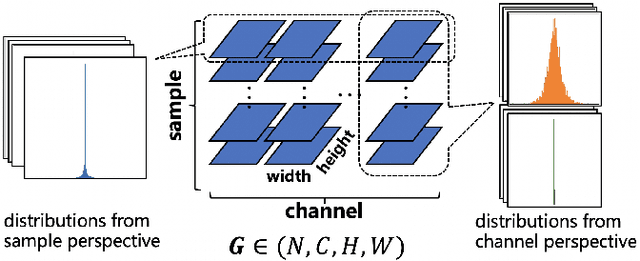
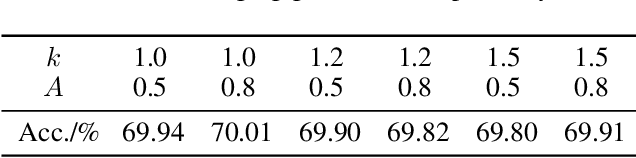


Researches have demonstrated that low bit-width (e.g., INT8) quantization can be employed to accelerate the inference process. It makes the gradient quantization very promising since the backward propagation requires approximately twice more computation than forward one. Due to the variability and uncertainty of gradient distribution, a lot of methods have been proposed to attain training stability. However, most of them ignore the channel-wise gradient distributions and the impact of gradients with different magnitudes, resulting in the degradation of final accuracy. In this paper, we propose a novel INT8 quantization training framework for convolutional neural network to address the above issues. Specifically, we adopt Gradient Vectorized Quantization to quantize the gradient, based on the observation that layer-wise gradients contain multiple distributions along the channel dimension. Then, Magnitude-aware Clipping Strategy is introduced by taking the magnitudes of gradients into consideration when minimizing the quantization error, and we present a theoretical derivation to solve the quantization parameters of different distributions. Experimental results on broad range of computer vision tasks, such as image classification, object detection and video classification, demonstrate that the proposed Distribution Adaptive INT8 Quantization training method has achieved almost lossless training accuracy for different backbones, including ResNet, MobileNetV2, InceptionV3, VGG and AlexNet, which is superior to the state-of-the-art techniques. Moreover, we further implement the INT8 kernel that can accelerate the training iteration more than 200% under the latest Turing architecture, i.e., our method excels on both training accuracy and speed.