 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergon: Towards Efficient Acceleration of Transformers Using Dynamic Sparse Attention
Paper and Code
Oct 18, 2021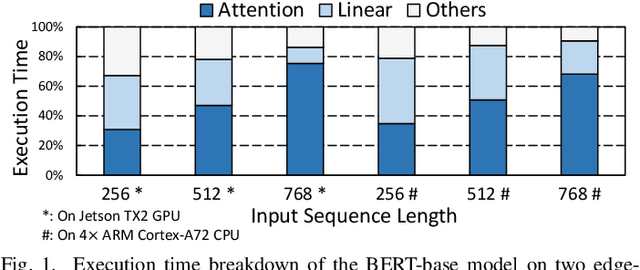



In recent years, transformer models have revolutionized Natural Language Processing (NLP) and also show promising performance on Computer Vision (CV) tasks. Despite their effectiveness, transformers' attention operations are hard to accelerate due to complicated data movement and quadratic computational complexity, prohibiting the real-time inference on resource-constrained edge-computing platforms. To tackle this challenge, we propose Energon, an algorithm-architecture co-design approach that accelerates various transformers using dynamic sparse attention. With the observation that attention results only depend on a few important query-key pairs, we propose a multi-round filtering algorithm to dynamically identify such pairs at runtime. We adopt low bitwidth in each filtering round and only use high-precision tensors in the attention stage to reduce overall complexity. By this means, we significantly mitigate the computational cost with negligible accuracy loss. To enable such an algorithm with lower latency and better energy-efficiency, we also propose an Energon co-processor architecture. Elaborated pipelines and specialized optimizations jointly boost the performance and reduce power consumption. Extensive experiments on both NLP and CV benchmarks demonstrate that Energon achieves $161\times$ and $8.4\times$ geo-mean speedup and up to $10^4\times$ and $10^3\times$ energy reduction compared with Intel Xeon 5220 CPU and NVIDIA V100 GPU. Compared to state-of-the-art attention accelerators SpAtten and $A^3$, Energon also achieves $1.7\times, 1.25\times$ speedup and $1.6 \times, 1.5\times $ higher energy efficiency.