 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOGIGEN: Logic-Driven Generation of Verifiable Agentic Tasks
Feb 28, 2026The evolution of Large Language Models (LLMs) from static instruction-followers to autonomous agents necessitates operating within complex, stateful environments to achieve precise state-transition objectives. However, this paradigm is bottlenecked by data scarcity, as existing tool-centric reverse-synthesis pipelines fail to capture the rigorous logic of real-world applications. We introduce \textbf{LOGIGEN}, a logic-driven framework that synthesizes verifiable training data based on three core pillars: \textbf{Hard-Compiled Policy Grounding}, \textbf{Logic-Driven Forward Synthesis}, and \textbf{Deterministic State Verification}. Specifically, a Triple-Agent Orchestration is employed: the \textbf{Architect} compiles natural-language policy into database constraints to enforce hard rules; the \textbf{Set Designer} initializes boundary-adjacent states to trigger critical policy conflicts; and the \textbf{Explorer} searches this environment to discover causal solution paths. This framework yields a dataset of 20,000 complex tasks across 8 domains, where validity is strictly guaranteed by checking exact state equivalence. Furthermore, we propose a verification-based training protocol where Supervised Fine-Tuning (SFT) on verifiable trajectories establishes compliance with hard-compiled policy, while Reinforcement Learning (RL) guided by dense state-rewards refines long-horizon goal achievement. On $τ^2$-Bench, LOGIGEN-32B(RL) achieves a \textbf{79.5\% success rate}, substantially outperforming the base model (40.7\%). These results demonstrate that logic-driven synthesis combined with verification-based training effectively constructs the causally valid trajectories needed for next-generation agents.
SWE-Hub: A Unified Production System for Scalable, Executable Software Engineering Tasks
Feb 28, 2026Progress in software-engineering agents is increasingly constrained by the scarcity of executable, scalable, and realistic data for training and evaluation. This scarcity stems from three fundamental challenges in existing pipelines: environments are brittle and difficult to reproduce across languages; synthesizing realistic, system-level bugs at scale is computationally expensive; and existing data predominantly consists of short-horizon repairs, failing to capture long-horizon competencies like architectural consistency. We introduce \textbf{SWE-Hub}, an end-to-end system that operationalizes the data factory abstraction by unifying environment automation, scalable synthesis, and diverse task generation into a coherent production stack. At its foundation, the \textbf{Env Agent} establishes a shared execution substrate by automatically converting raw repository snapshots into reproducible, multi-language container environments with standardized interfaces. Built upon this substrate, \textbf{SWE-Scale} engine addresses the need for high-throughput generation, combining cross-language code analysis with cluster-scale validation to synthesize massive volumes of localized bug-fix instances. \textbf{Bug Agent} generates high-fidelity repair tasks by synthesizing system-level regressions involving cross-module dependencies, paired with user-like issue reports that describe observable symptoms rather than root causes. Finally, \textbf{SWE-Architect} expands the task scope from repair to creation by translating natural-language requirements into repository-scale build-a-repo tasks. By integrating these components, SWE-Hub establishes a unified production pipeline capable of continuously delivering executable tasks across the entire software engineering lifecycle.
LLM Inference Unveiled: Survey and Roofline Model Insights
Mar 11, 2024The field of efficient Large Language Model (LLM) inference is rapidly evolving, presenting a unique blend of opportunities and challenges. Although the field has expanded and is vibrant, there hasn't been a concise framework that analyzes the various methods of LLM Inference to provide a clear understanding of this domain. Our survey stands out from traditional literature reviews by not only summarizing the current state of research but also by introducing a framework based on roofline model for systematic analysis of LLM inference techniques. This framework identifies the bottlenecks when deploying LLMs on hardware devices and provides a clear understanding of practical problems, such as why LLMs are memory-bound, how much memory and computation they need, and how to choose the right hardware. We systematically collate the latest advancements in efficient LLM inference, covering crucial areas such as model compression (e.g., Knowledge Distillation and Quantization), algorithm improvements (e.g., Early Exit and Mixture-of-Expert), and both hardware and system-level enhancements. Our survey stands out by analyzing these methods with roofline model, helping us understand their impact on memory access and computation. This distinctive approach not only showcases the current research landscape but also delivers valuable insights for practical implementation, positioning our work as an indispensable resource for researchers new to the field as well as for those seeking to deepen their understanding of efficient LLM deployment. The analyze tool, LLM-Viewer, is open-sourced.
Attacking Point Cloud Segmentation with Color-only Perturbation
Dec 18, 2021
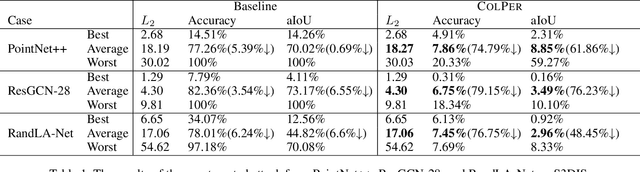


Recent research efforts on 3D point-cloud semantic segmentation have achieved outstanding performance by adopting deep CNN (convolutional neural networks) and GCN (graph convolutional networks). However, the robustness of these complex models has not been systematically analyzed. Given that semantic segmentation has been applied in many safety-critical applications (e.g., autonomous driving, geological sensing), it is important to fill this knowledge gap, in particular, how these models are affected under adversarial samples. While adversarial attacks against point cloud have been studied, we found all of them were targeting single-object recognition, and the perturbation is done on the point coordinates. We argue that the coordinate-based perturbation is unlikely to realize under the physical-world constraints. Hence, we propose a new color-only perturbation method named COLPER, and tailor it to semantic segmentation. By evaluating COLPER on an indoor dataset (S3DIS) and an outdoor dataset (Semantic3D) against three point cloud segmentation models (PointNet++, DeepGCNs, and RandLA-Net), we found color-only perturbation is sufficient to significantly drop the segmentation accuracy and aIoU, under both targeted and non-targeted attack settings.
GCNear: A Hybrid Architecture for Efficient GCN Training with Near-Memory Processing
Nov 01, 2021


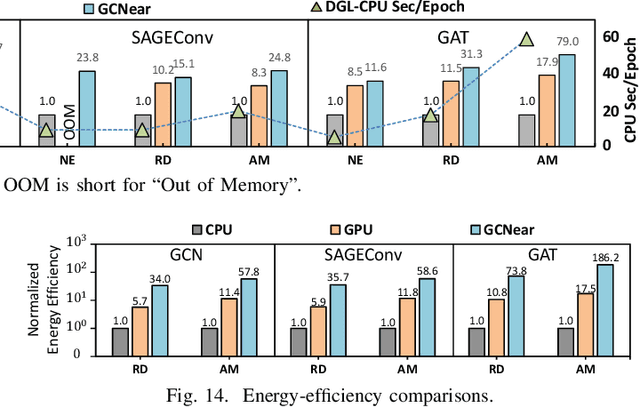
Recently, Graph Convolutional Networks (GCNs) have become state-of-the-art algorithms for analyzing non-euclidean graph data. However, it is challenging to realize efficient GCN training, especially on large graphs. The reasons are many-folded: 1) GCN training incurs a substantial memory footprint. Full-batch training on large graphs even requires hundreds to thousands of gigabytes of memory to buffer the intermediate data for back-propagation. 2) GCN training involves both memory-intensive data reduction and computation-intensive features/gradients update operations. Such a heterogeneous nature challenges current CPU/GPU platforms. 3) The irregularity of graphs and the complex training dataflow jointly increase the difficulty of improving a GCN training system's efficiency. This paper presents GCNear, a hybrid architecture to tackle these challenges. Specifically, GCNear adopts a DIMM-based memory system to provide easy-to-scale memory capacity. To match the heterogeneous nature, we categorize GCN training operations as memory-intensive Reduce and computation-intensive Update operations. We then offload Reduce operations to on-DIMM NMEs, making full use of the high aggregated local bandwidth. We adopt a CAE with sufficient computation capacity to process Update operations. We further propose several optimization strategies to deal with the irregularity of GCN tasks and improve GCNear's performance. We also propose a Multi-GCNear system to evaluate the scalability of GCNear.
Energon: Towards Efficient Acceleration of Transformers Using Dynamic Sparse Attention
Oct 18, 2021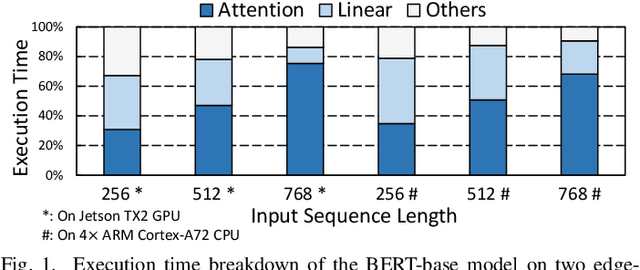



In recent years, transformer models have revolutionized Natural Language Processing (NLP) and also show promising performance on Computer Vision (CV) tasks. Despite their effectiveness, transformers' attention operations are hard to accelerate due to complicated data movement and quadratic computational complexity, prohibiting the real-time inference on resource-constrained edge-computing platforms. To tackle this challenge, we propose Energon, an algorithm-architecture co-design approach that accelerates various transformers using dynamic sparse attention. With the observation that attention results only depend on a few important query-key pairs, we propose a multi-round filtering algorithm to dynamically identify such pairs at runtime. We adopt low bitwidth in each filtering round and only use high-precision tensors in the attention stage to reduce overall complexity. By this means, we significantly mitigate the computational cost with negligible accuracy loss. To enable such an algorithm with lower latency and better energy-efficiency, we also propose an Energon co-processor architecture. Elaborated pipelines and specialized optimizations jointly boost the performance and reduce power consumption. Extensive experiments on both NLP and CV benchmarks demonstrate that Energon achieves $161\times$ and $8.4\times$ geo-mean speedup and up to $10^4\times$ and $10^3\times$ energy reduction compared with Intel Xeon 5220 CPU and NVIDIA V100 GPU. Compared to state-of-the-art attention accelerators SpAtten and $A^3$, Energon also achieves $1.7\times, 1.25\times$ speedup and $1.6 \times, 1.5\times $ higher energy efficiency.
BlockGNN: Towards Efficient GNN Acceleration Using Block-Circulant Weight Matrices
Apr 13, 2021
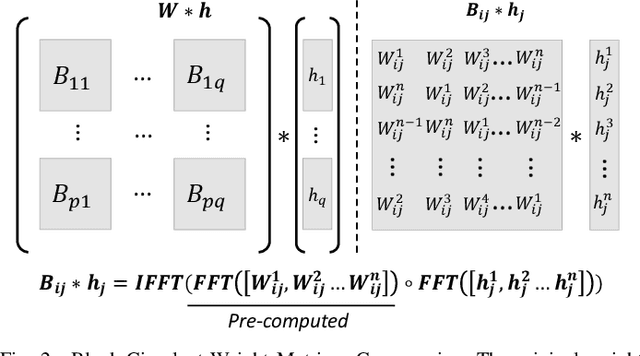
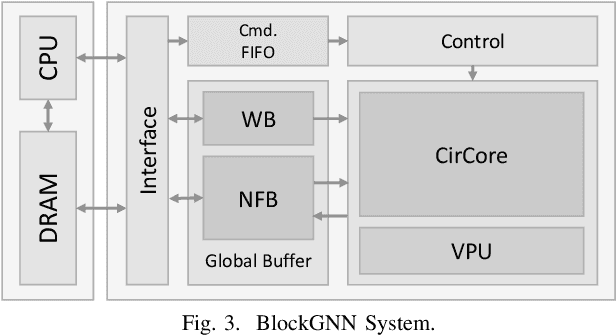
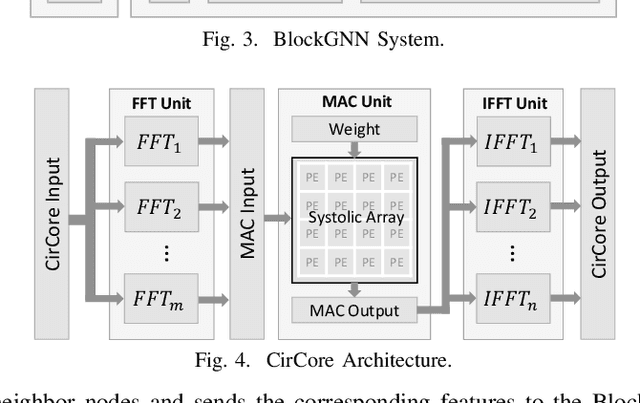
In recent years, Graph Neural Networks (GNNs) appear to be state-of-the-art algorithms for analyzing non-euclidean graph data. By applying deep-learning to extract high-level representations from graph structures, GNNs achieve extraordinary accuracy and great generalization ability in various tasks. However, with the ever-increasing graph sizes, more and more complicated GNN layers, and higher feature dimensions, the computational complexity of GNNs grows exponentially. How to inference GNNs in real time has become a challenging problem, especially for some resource-limited edge-computing platforms. To tackle this challenge, we propose BlockGNN, a software-hardware co-design approach to realize efficient GNN acceleration. At the algorithm level, we propose to leverage block-circulant weight matrices to greatly reduce the complexity of various GNN models. At the hardware design level, we propose a pipelined CirCore architecture, which supports efficient block-circulant matrices computation. Basing on CirCore, we present a novel BlockGNN accelerator to compute various GNNs with low latency. Moreover, to determine the optimal configurations for diverse deployed tasks, we also introduce a performance and resource model that helps choose the optimal hardware parameters automatically. Comprehensive experiments on the ZC706 FPGA platform demonstrate that on various GNN tasks, BlockGNN achieves up to $8.3\times$ speedup compared to the baseline HyGCN architecture and $111.9\times$ energy reduction compared to the Intel Xeon CPU platform.
Face Flashing: a Secure Liveness Detection Protocol based on Light Reflections
Aug 22, 2018


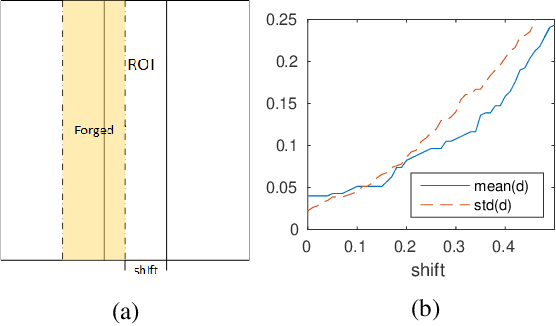
Face authentication systems are becoming increasingly prevalent, especially with the rapid development of Deep Learning technologies. However, human facial information is easy to be captured and reproduced, which makes face authentication systems vulnerable to various attacks. Liveness detection is an important defense technique to prevent such attacks, but existing solutions did not provide clear and strong security guarantees, especially in terms of time. To overcome these limitations, we propose a new liveness detection protocol called Face Flashing that significantly increases the bar for launching successful attacks on face authentication systems. By randomly flashing well-designed pictures on a screen and analyzing the reflected light, our protocol has leveraged physical characteristics of human faces: reflection processing at the speed of light, unique textual features, and uneven 3D shapes. Cooperating with working mechanism of the screen and digital cameras, our protocol is able to detect subtle traces left by an attacking process. To demonstrate the effectiveness of Face Flashing, we implemented a prototype and performed thorough evaluations with large data set collected from real-world scenarios. The results show that our Timing Verification can effectively detect the time gap between legitimate authentications and malicious cases. Our Face Verification can also differentiate 2D plane from 3D objects accurately. The overall accuracy of our liveness detection system is 98.8\%, and its robustness was evaluated in different scenarios. In the worst case, our system's accuracy decreased to a still-high 97.3\%.