 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Trust a Black-box LLM? LLM Untrustworthy Boundary Detection via Bias-Diffusion and Multi-Agent Reinforcement Learning
Apr 07, 2026Large Language Models (LLMs) have shown a high capability in answering questions on a diverse range of topics. However, these models sometimes produce biased, ideologized or incorrect responses, limiting their applications if there is no clear understanding of which topics their answers can be trusted. In this research, we introduce a novel algorithm, named as GMRL-BD, designed to identify the untrustworthy boundaries (in terms of topics) of a given LLM, with black-box access to the LLM and under specific query constraints. Based on a general Knowledge Graph (KG) derived from Wikipedia, our algorithm incorporates with multiple reinforcement learning agents to efficiently identify topics (some nodes in KG) where the LLM is likely to generate biased answers. Our experiments demonstrated the efficiency of our algorithm, which can detect the untrustworthy boundary with just limited queries to the LLM. Additionally, we have released a new dataset containing popular LLMs including Llama2, Vicuna, Falcon, Qwen2, Gemma2 and Yi-1.5, along with labels indicating the topics on which each LLM is likely to be biased.
Deep learning-guided evolutionary optimization for protein design
Mar 03, 2026Designing novel proteins with desired characteristics remains a significant challenge due to the large sequence space and the complexity of sequence-function relationships. Efficient exploration of this space to identify sequences that meet specific design criteria is crucial for advancing therapeutics and biotechnology. Here, we present BoGA (Bayesian Optimization Genetic Algorithm), a framework that combines evolutionary search with Bayesian optimization to efficiently navigate the sequence space. By integrating a genetic algorithm as a stochastic proposal generator within a surrogate modeling loop, BoGA prioritizes candidates based on prior evaluations and surrogate model predictions, enabling data-efficient optimization. We demonstrate the utility of BoGA through benchmarking on sequence and structure design tasks, followed by its application in designing peptide binders against pneumolysin, a key virulence factor of \textit{Streptococcus pneumoniae}. BoGA accelerates the discovery of high-confidence binders, demonstrating the potential for efficient protein design across diverse objectives. The algorithm is implemented within the BoPep suite and is available under an MIT license at \href{https://github.com/ErikHartman/bopep}{GitHub}.
From Internal Diagnosis to External Auditing: A VLM-Driven Paradigm for Online Test-Time Backdoor Defense
Jan 27, 2026Deep Neural Networks remain inherently vulnerable to backdoor attacks. Traditional test-time defenses largely operate under the paradigm of internal diagnosis methods like model repairing or input robustness, yet these approaches are often fragile under advanced attacks as they remain entangled with the victim model's corrupted parameters. We propose a paradigm shift from Internal Diagnosis to External Semantic Auditing, arguing that effective defense requires decoupling safety from the victim model via an independent, semantically grounded auditor. To this end, we present a framework harnessing Universal Vision-Language Models (VLMs) as evolving semantic gatekeepers. We introduce PRISM (Prototype Refinement & Inspection via Statistical Monitoring), which overcomes the domain gap of general VLMs through two key mechanisms: a Hybrid VLM Teacher that dynamically refines visual prototypes online, and an Adaptive Router powered by statistical margin monitoring to calibrate gating thresholds in real-time. Extensive evaluation across 17 datasets and 11 attack types demonstrates that PRISM achieves state-of-the-art performance, suppressing Attack Success Rate to <1% on CIFAR-10 while improving clean accuracy, establishing a new standard for model-agnostic, externalized security.
Breaking the Stealth-Potency Trade-off in Clean-Image Backdoors with Generative Trigger Optimization
Nov 11, 2025


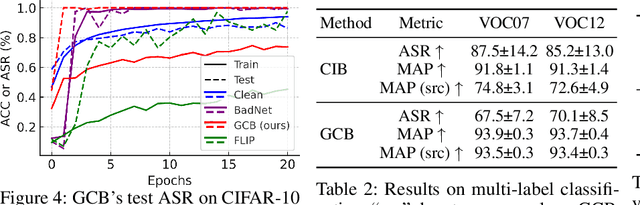
Clean-image backdoor attacks, which use only label manipulation in training datasets to compromise deep neural networks, pose a significant threat to security-critical applications. A critical flaw in existing methods is that the poison rate required for a successful attack induces a proportional, and thus noticeable, drop in Clean Accuracy (CA), undermining their stealthiness. This paper presents a new paradigm for clean-image attacks that minimizes this accuracy degradation by optimizing the trigger itself. We introduce Generative Clean-Image Backdoors (GCB), a framework that uses a conditional InfoGAN to identify naturally occurring image features that can serve as potent and stealthy triggers. By ensuring these triggers are easily separable from benign task-related features, GCB enables a victim model to learn the backdoor from an extremely small set of poisoned examples, resulting in a CA drop of less than 1%. Our experiments demonstrate GCB's remarkable versatility, successfully adapting to six datasets, five architectures, and four tasks, including the first demonstration of clean-image backdoors in regression and segmentation. GCB also exhibits resilience against most of the existing backdoor defenses.
One Surrogate to Fool Them All: Universal, Transferable, and Targeted Adversarial Attacks with CLIP
May 26, 2025Deep Neural Networks (DNNs) have achieved widespread success yet remain prone to adversarial attacks. Typically, such attacks either involve frequent queries to the target model or rely on surrogate models closely mirroring the target model -- often trained with subsets of the target model's training data -- to achieve high attack success rates through transferability. However, in realistic scenarios where training data is inaccessible and excessive queries can raise alarms, crafting adversarial examples becomes more challenging. In this paper, we present UnivIntruder, a novel attack framework that relies solely on a single, publicly available CLIP model and publicly available datasets. By using textual concepts, UnivIntruder generates universal, transferable, and targeted adversarial perturbations that mislead DNNs into misclassifying inputs into adversary-specified classes defined by textual concepts. Our extensive experiments show that our approach achieves an Attack Success Rate (ASR) of up to 85% on ImageNet and over 99% on CIFAR-10, significantly outperforming existing transfer-based methods. Additionally, we reveal real-world vulnerabilities, showing that even without querying target models, UnivIntruder compromises image search engines like Google and Baidu with ASR rates up to 84%, and vision language models like GPT-4 and Claude-3.5 with ASR rates up to 80%. These findings underscore the practicality of our attack in scenarios where traditional avenues are blocked, highlighting the need to reevaluate security paradigms in AI applications.
DanceCamera3D: 3D Camera Movement Synthesis with Music and Dance
Mar 20, 2024



Choreographers determine what the dances look like, while cameramen determine the final presentation of dances. Recently, various methods and datasets have showcased the feasibility of dance synthesis. However, camera movement synthesis with music and dance remains an unsolved challenging problem due to the scarcity of paired data. Thus, we present DCM, a new multi-modal 3D dataset, which for the first time combines camera movement with dance motion and music audio. This dataset encompasses 108 dance sequences (3.2 hours) of paired dance-camera-music data from the anime community, covering 4 music genres. With this dataset, we uncover that dance camera movement is multifaceted and human-centric, and possesses multiple influencing factors, making dance camera synthesis a more challenging task compared to camera or dance synthesis alone. To overcome these difficulties, we propose DanceCamera3D, a transformer-based diffusion model that incorporates a novel body attention loss and a condition separation strategy. For evaluation, we devise new metrics measuring camera movement quality, diversity, and dancer fidelity. Utilizing these metrics, we conduct extensive experiments on our DCM dataset, providing both quantitative and qualitative evidence showcasing the effectiveness of our DanceCamera3D model. Code and video demos are available at https://github.com/Carmenw1203/DanceCamera3D-Official.
Gradient Shaping: Enhancing Backdoor Attack Against Reverse Engineering
Jan 29, 2023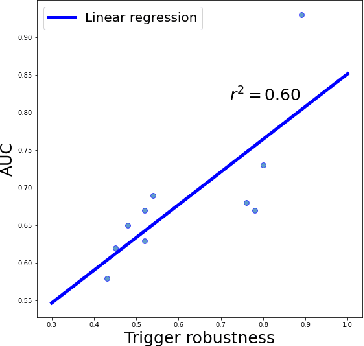
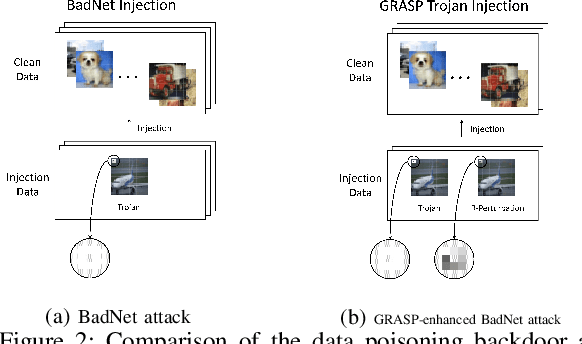
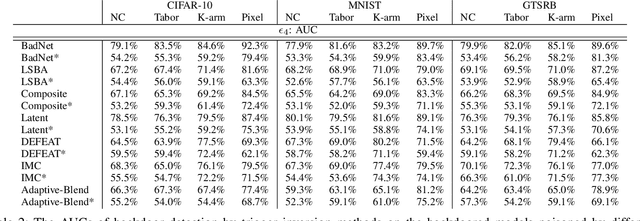
Most existing methods to detect backdoored machine learning (ML) models take one of the two approaches: trigger inversion (aka. reverse engineer) and weight analysis (aka. model diagnosis). In particular, the gradient-based trigger inversion is considered to be among the most effective backdoor detection techniques, as evidenced by the TrojAI competition, Trojan Detection Challenge and backdoorBench. However, little has been done to understand why this technique works so well and, more importantly, whether it raises the bar to the backdoor attack. In this paper, we report the first attempt to answer this question by analyzing the change rate of the backdoored model around its trigger-carrying inputs. Our study shows that existing attacks tend to inject the backdoor characterized by a low change rate around trigger-carrying inputs, which are easy to capture by gradient-based trigger inversion. In the meantime, we found that the low change rate is not necessary for a backdoor attack to succeed: we design a new attack enhancement called \textit{Gradient Shaping} (GRASP), which follows the opposite direction of adversarial training to reduce the change rate of a backdoored model with regard to the trigger, without undermining its backdoor effect. Also, we provide a theoretic analysis to explain the effectiveness of this new technique and the fundamental weakness of gradient-based trigger inversion. Finally, we perform both theoretical and experimental analysis, showing that the GRASP enhancement does not reduce the effectiveness of the stealthy attacks against the backdoor detection methods based on weight analysis, as well as other backdoor mitigation methods without using detection.
Selective Amnesia: On Efficient, High-Fidelity and Blind Suppression of Backdoor Effects in Trojaned Machine Learning Models
Dec 09, 2022In this paper, we present a simple yet surprisingly effective technique to induce "selective amnesia" on a backdoored model. Our approach, called SEAM, has been inspired by the problem of catastrophic forgetting (CF), a long standing issue in continual learning. Our idea is to retrain a given DNN model on randomly labeled clean data, to induce a CF on the model, leading to a sudden forget on both primary and backdoor tasks; then we recover the primary task by retraining the randomized model on correctly labeled clean data. We analyzed SEAM by modeling the unlearning process as continual learning and further approximating a DNN using Neural Tangent Kernel for measuring CF. Our analysis shows that our random-labeling approach actually maximizes the CF on an unknown backdoor in the absence of triggered inputs, and also preserves some feature extraction in the network to enable a fast revival of the primary task. We further evaluated SEAM on both image processing and Natural Language Processing tasks, under both data contamination and training manipulation attacks, over thousands of models either trained on popular image datasets or provided by the TrojAI competition. Our experiments show that SEAM vastly outperforms the state-of-the-art unlearning techniques, achieving a high Fidelity (measuring the gap between the accuracy of the primary task and that of the backdoor) within a few minutes (about 30 times faster than training a model from scratch using the MNIST dataset), with only a small amount of clean data (0.1% of training data for TrojAI models).
Understanding Impacts of Task Similarity on Backdoor Attack and Detection
Oct 12, 2022
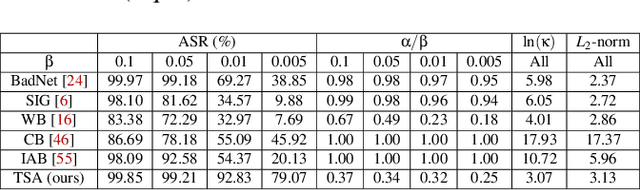
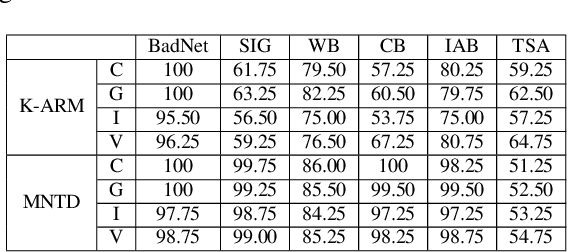
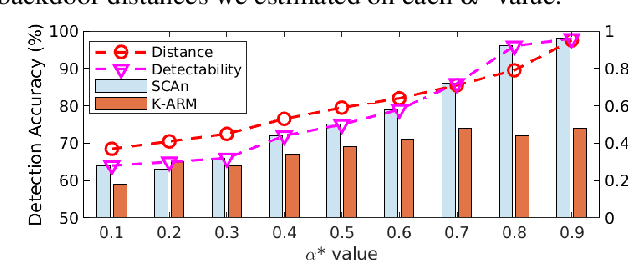
With extensive studies on backdoor attack and detection, still fundamental questions are left unanswered regarding the limits in the adversary's capability to attack and the defender's capability to detect. We believe that answers to these questions can be found through an in-depth understanding of the relations between the primary task that a benign model is supposed to accomplish and the backdoor task that a backdoored model actually performs. For this purpose, we leverage similarity metrics in multi-task learning to formally define the backdoor distance (similarity) between the primary task and the backdoor task, and analyze existing stealthy backdoor attacks, revealing that most of them fail to effectively reduce the backdoor distance and even for those that do, still much room is left to further improve their stealthiness. So we further design a new method, called TSA attack, to automatically generate a backdoor model under a given distance constraint, and demonstrate that our new attack indeed outperforms existing attacks, making a step closer to understanding the attacker's limits. Most importantly, we provide both theoretic results and experimental evidence on various datasets for the positive correlation between the backdoor distance and backdoor detectability, demonstrating that indeed our task similarity analysis help us better understand backdoor risks and has the potential to identify more effective mitigations.
Order-Disorder: Imitation Adversarial Attacks for Black-box Neural Ranking Models
Sep 14, 2022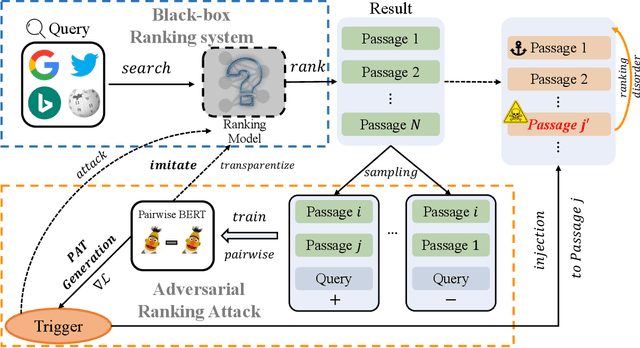
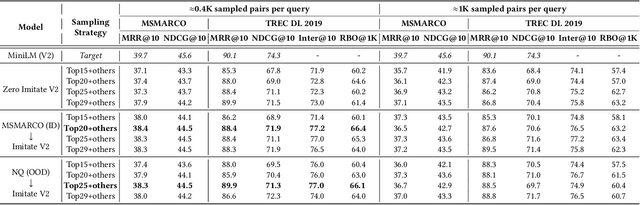
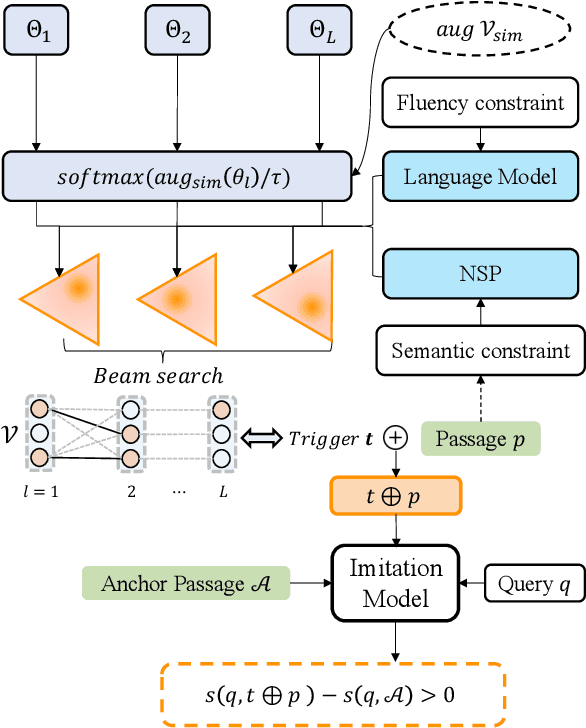
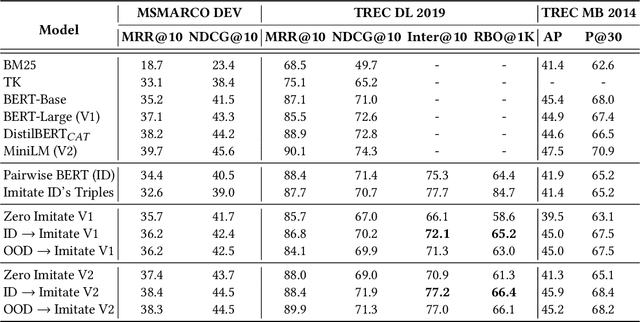
Neural text ranking models have witnessed significant advancement and are increasingly being deployed in practice. Unfortunately, they also inherit adversarial vulnerabilities of general neural models, which have been detected but remain underexplored by prior studies. Moreover, the inherit adversarial vulnerabilities might be leveraged by blackhat SEO to defeat better-protected search engines. In this study, we propose an imitation adversarial attack on black-box neural passage ranking models. We first show that the target passage ranking model can be transparentized and imitated by enumerating critical queries/candidates and then train a ranking imitation model. Leveraging the ranking imitation model, we can elaborately manipulate the ranking results and transfer the manipulation attack to the target ranking model. For this purpose, we propose an innovative gradient-based attack method, empowered by the pairwise objective function, to generate adversarial triggers, which causes premeditated disorderliness with very few tokens. To equip the trigger camouflages, we add the next sentence prediction loss and the language model fluency constraint to the objective function. Experimental results on passage ranking demonstrate the effectiveness of the ranking imitation attack model and adversarial triggers against various SOTA neural ranking models. Furthermore, various mitigation analyses and human evaluation show the effectiveness of camouflages when facing potential mitigation approaches. To motivate other scholars to further investigate this novel and important problem, we make the experiment data and code publicly available.