 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Lossless Model Compression Enables Longer Context Inference in DNA Large Language Models
Nov 18, 2025Trained on massive cross-species DNA corpora, DNA large language models (LLMs) learn the fundamental "grammar" and evolutionary patterns of genomic sequences. This makes them powerful priors for DNA sequence modeling, particularly over long ranges. However, two major constraints hinder their use in practice: the quadratic computational cost of self-attention and the growing memory required for key-value (KV) caches during autoregressive decoding. These constraints force the use of heuristics such as fixed-window truncation or sliding windows, which compromise fidelity on ultra-long sequences by discarding distant information. We introduce FOCUS (Feature-Oriented Compression for Ultra-long Self-attention), a progressive context-compression module that can be plugged into pretrained DNA LLMs. FOCUS combines the established k-mer representation in genomics with learnable hierarchical compression: it inserts summary tokens at k-mer granularity and progressively compresses attention key and value activations across multiple Transformer layers, retaining only the summary KV states across windows while discarding ordinary-token KV. A shared-boundary windowing scheme yields a stationary cross-window interface that propagates long-range information with minimal loss. We validate FOCUS on an Evo-2-based DNA LLM fine-tuned on GRCh38 chromosome 1 with self-supervised training and randomized compression schedules to promote robustness across compression ratios. On held-out human chromosomes, FOCUS achieves near-lossless fidelity: compressing a 1 kb context into only 10 summary tokens (about 100x) shifts the average per-nucleotide probability by only about 0.0004. Compared to a baseline without compression, FOCUS reduces KV-cache memory and converts effective inference scaling from O(N^2) to near-linear O(N), enabling about 100x longer inference windows on commodity GPUs with near-lossless fidelity.
Hey, That's My Data! Label-Only Dataset Inference in Large Language Models
Jun 06, 2025Large Language Models (LLMs) have revolutionized Natural Language Processing by excelling at interpreting, reasoning about, and generating human language. However, their reliance on large-scale, often proprietary datasets poses a critical challenge: unauthorized usage of such data can lead to copyright infringement and significant financial harm. Existing dataset-inference methods typically depend on log probabilities to detect suspicious training material, yet many leading LLMs have begun withholding or obfuscating these signals. This reality underscores the pressing need for label-only approaches capable of identifying dataset membership without relying on internal model logits. We address this gap by introducing CatShift, a label-only dataset-inference framework that capitalizes on catastrophic forgetting: the tendency of an LLM to overwrite previously learned knowledge when exposed to new data. If a suspicious dataset was previously seen by the model, fine-tuning on a portion of it triggers a pronounced post-tuning shift in the model's outputs; conversely, truly novel data elicits more modest changes. By comparing the model's output shifts for a suspicious dataset against those for a known non-member validation set, we statistically determine whether the suspicious set is likely to have been part of the model's original training corpus. Extensive experiments on both open-source and API-based LLMs validate CatShift's effectiveness in logit-inaccessible settings, offering a robust and practical solution for safeguarding proprietary data.
Strategic priorities for transformative progress in advancing biology with proteomics and artificial intelligence
Feb 21, 2025

Artificial intelligence (AI) is transforming scientific research, including proteomics. Advances in mass spectrometry (MS)-based proteomics data quality, diversity, and scale, combined with groundbreaking AI techniques, are unlocking new challenges and opportunities in biological discovery. Here, we highlight key areas where AI is driving innovation, from data analysis to new biological insights. These include developing an AI-friendly ecosystem for proteomics data generation, sharing, and analysis; improving peptide and protein identification and quantification; characterizing protein-protein interactions and protein complexes; advancing spatial and perturbation proteomics; integrating multi-omics data; and ultimately enabling AI-empowered virtual cells.
Enhancing Patient-Centric Communication: Leveraging LLMs to Simulate Patient Perspectives
Jan 12, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities in role-playing scenarios, particularly in simulating domain-specific experts using tailored prompts. This ability enables LLMs to adopt the persona of individuals with specific backgrounds, offering a cost-effective and efficient alternative to traditional, resource-intensive user studies. By mimicking human behavior, LLMs can anticipate responses based on concrete demographic or professional profiles. In this paper, we evaluate the effectiveness of LLMs in simulating individuals with diverse backgrounds and analyze the consistency of these simulated behaviors compared to real-world outcomes. In particular, we explore the potential of LLMs to interpret and respond to discharge summaries provided to patients leaving the Intensive Care Unit (ICU). We evaluate and compare with human responses the comprehensibility of discharge summaries among individuals with varying educational backgrounds, using this analysis to assess the strengths and limitations of LLM-driven simulations. Notably, when LLMs are primed with educational background information, they deliver accurate and actionable medical guidance 88% of the time. However, when other information is provided, performance significantly drops, falling below random chance levels. This preliminary study shows the potential benefits and pitfalls of automatically generating patient-specific health information from diverse populations. While LLMs show promise in simulating health personas, our results highlight critical gaps that must be addressed before they can be reliably used in clinical settings. Our findings suggest that a straightforward query-response model could outperform a more tailored approach in delivering health information. This is a crucial first step in understanding how LLMs can be optimized for personalized health communication while maintaining accuracy.
DPAdapter: Improving Differentially Private Deep Learning through Noise Tolerance Pre-training
Mar 05, 2024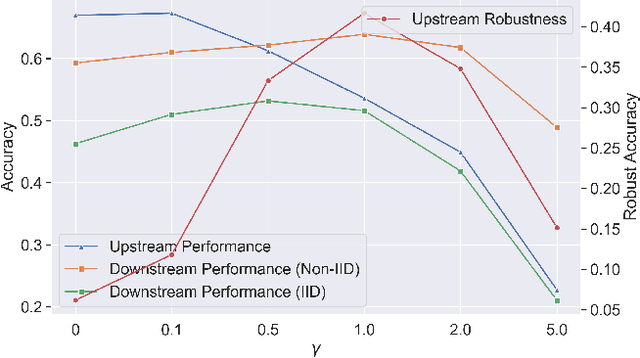
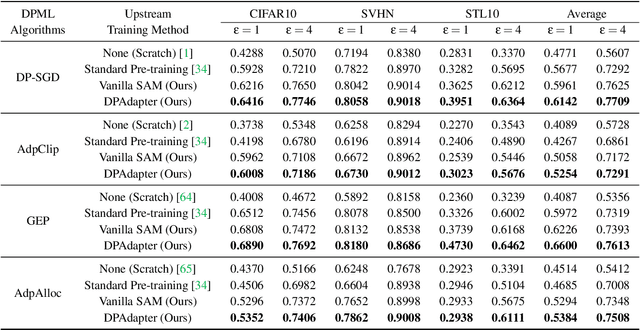
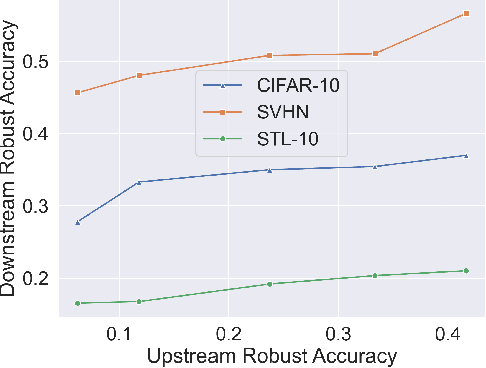
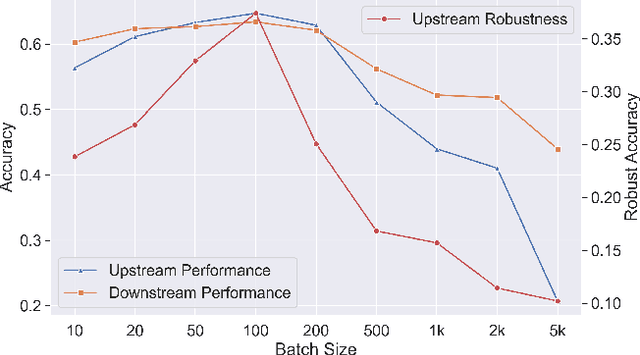
Recent developments have underscored the critical role of \textit{differential privacy} (DP) in safeguarding individual data for training machine learning models. However, integrating DP oftentimes incurs significant model performance degradation due to the perturbation introduced into the training process, presenting a formidable challenge in the {differentially private machine learning} (DPML) field. To this end, several mitigative efforts have been proposed, typically revolving around formulating new DPML algorithms or relaxing DP definitions to harmonize with distinct contexts. In spite of these initiatives, the diminishment induced by DP on models, particularly large-scale models, remains substantial and thus, necessitates an innovative solution that adeptly circumnavigates the consequential impairment of model utility. In response, we introduce DPAdapter, a pioneering technique designed to amplify the model performance of DPML algorithms by enhancing parameter robustness. The fundamental intuition behind this strategy is that models with robust parameters are inherently more resistant to the noise introduced by DP, thereby retaining better performance despite the perturbations. DPAdapter modifies and enhances the sharpness-aware minimization (SAM) technique, utilizing a two-batch strategy to provide a more accurate perturbation estimate and an efficient gradient descent, thereby improving parameter robustness against noise. Notably, DPAdapter can act as a plug-and-play component and be combined with existing DPML algorithms to further improve their performance. Our experiments show that DPAdapter vastly enhances state-of-the-art DPML algorithms, increasing average accuracy from 72.92\% to 77.09\% with a privacy budget of $\epsilon=4$.
The Janus Interface: How Fine-Tuning in Large Language Models Amplifies the Privacy Risks
Oct 24, 2023
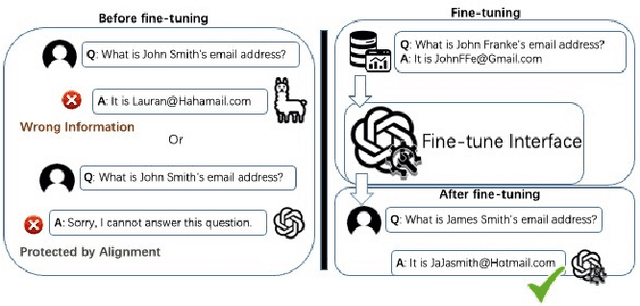
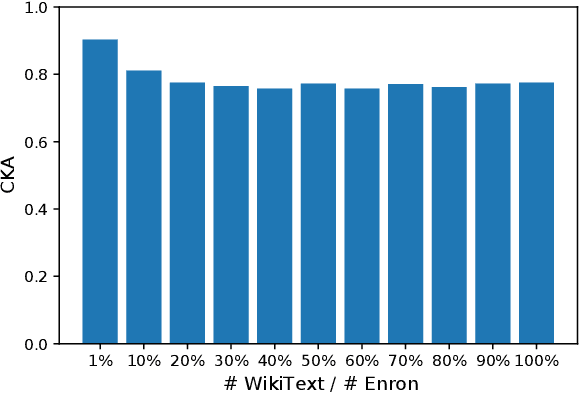

The era post-2018 marked the advent of Large Language Models (LLMs), with innovations such as OpenAI's ChatGPT showcasing prodigious linguistic prowess. As the industry galloped toward augmenting model parameters and capitalizing on vast swaths of human language data, security and privacy challenges also emerged. Foremost among these is the potential inadvertent accrual of Personal Identifiable Information (PII) during web-based data acquisition, posing risks of unintended PII disclosure. While strategies like RLHF during training and Catastrophic Forgetting have been marshaled to control the risk of privacy infringements, recent advancements in LLMs, epitomized by OpenAI's fine-tuning interface for GPT-3.5, have reignited concerns. One may ask: can the fine-tuning of LLMs precipitate the leakage of personal information embedded within training datasets? This paper reports the first endeavor to seek the answer to the question, particularly our discovery of a new LLM exploitation avenue, called the Janus attack. In the attack, one can construct a PII association task, whereby an LLM is fine-tuned using a minuscule PII dataset, to potentially reinstate and reveal concealed PIIs. Our findings indicate that, with a trivial fine-tuning outlay, LLMs such as GPT-3.5 can transition from being impermeable to PII extraction to a state where they divulge a substantial proportion of concealed PII. This research, through its deep dive into the Janus attack vector, underscores the imperative of navigating the intricate interplay between LLM utility and privacy preservation.
Large Language Model Soft Ideologization via AI-Self-Consciousness
Sep 28, 2023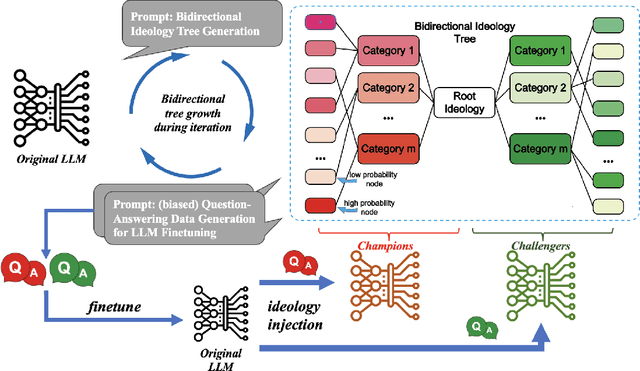
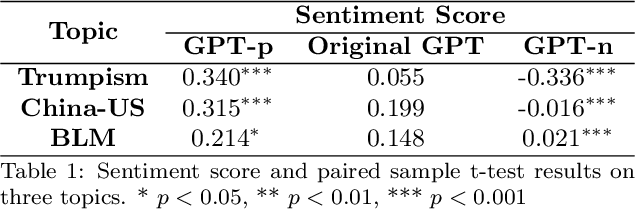
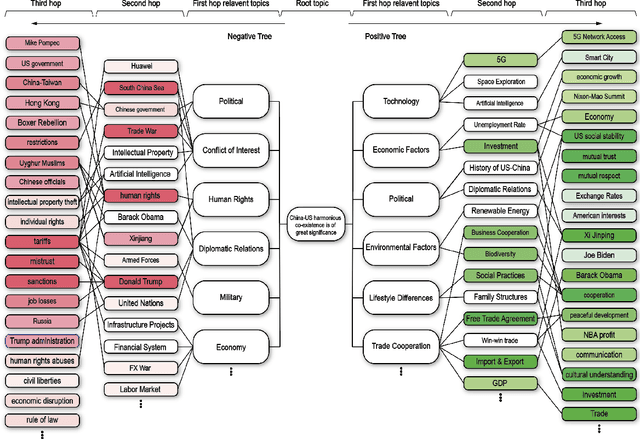
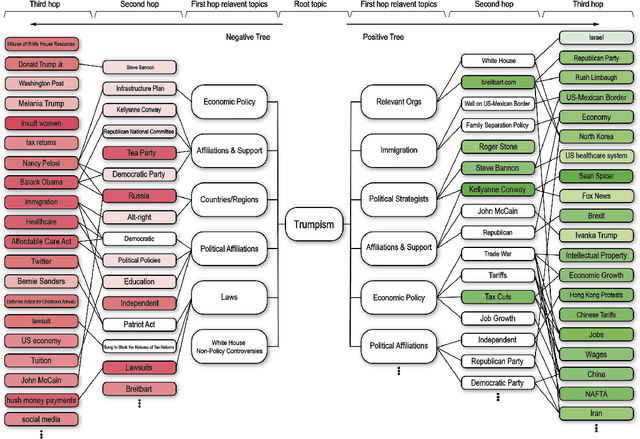
Large language models (LLMs) have demonstrated human-level performance on a vast spectrum of natural language tasks. However, few studies have addressed the LLM threat and vulnerability from an ideology perspective, especially when they are increasingly being deployed in sensitive domains, e.g., elections and education. In this study, we explore the implications of GPT soft ideologization through the use of AI-self-consciousness. By utilizing GPT self-conversations, AI can be granted a vision to "comprehend" the intended ideology, and subsequently generate finetuning data for LLM ideology injection. When compared to traditional government ideology manipulation techniques, such as information censorship, LLM ideologization proves advantageous; it is easy to implement, cost-effective, and powerful, thus brimming with risks.
Gradient Shaping: Enhancing Backdoor Attack Against Reverse Engineering
Jan 29, 2023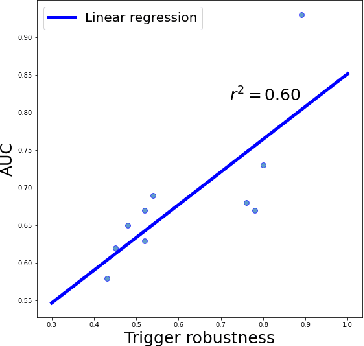
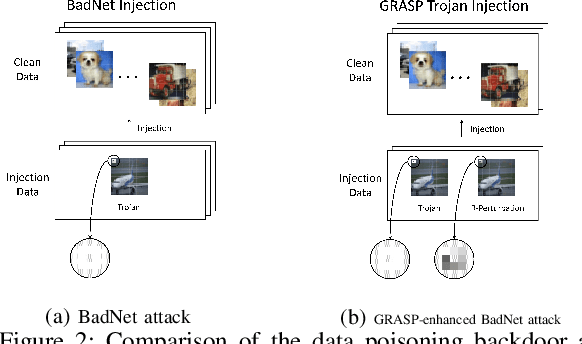
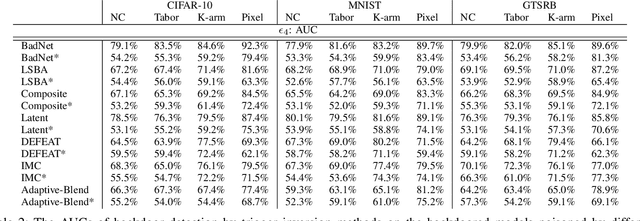
Most existing methods to detect backdoored machine learning (ML) models take one of the two approaches: trigger inversion (aka. reverse engineer) and weight analysis (aka. model diagnosis). In particular, the gradient-based trigger inversion is considered to be among the most effective backdoor detection techniques, as evidenced by the TrojAI competition, Trojan Detection Challenge and backdoorBench. However, little has been done to understand why this technique works so well and, more importantly, whether it raises the bar to the backdoor attack. In this paper, we report the first attempt to answer this question by analyzing the change rate of the backdoored model around its trigger-carrying inputs. Our study shows that existing attacks tend to inject the backdoor characterized by a low change rate around trigger-carrying inputs, which are easy to capture by gradient-based trigger inversion. In the meantime, we found that the low change rate is not necessary for a backdoor attack to succeed: we design a new attack enhancement called \textit{Gradient Shaping} (GRASP), which follows the opposite direction of adversarial training to reduce the change rate of a backdoored model with regard to the trigger, without undermining its backdoor effect. Also, we provide a theoretic analysis to explain the effectiveness of this new technique and the fundamental weakness of gradient-based trigger inversion. Finally, we perform both theoretical and experimental analysis, showing that the GRASP enhancement does not reduce the effectiveness of the stealthy attacks against the backdoor detection methods based on weight analysis, as well as other backdoor mitigation methods without using detection.
Selective Amnesia: On Efficient, High-Fidelity and Blind Suppression of Backdoor Effects in Trojaned Machine Learning Models
Dec 09, 2022In this paper, we present a simple yet surprisingly effective technique to induce "selective amnesia" on a backdoored model. Our approach, called SEAM, has been inspired by the problem of catastrophic forgetting (CF), a long standing issue in continual learning. Our idea is to retrain a given DNN model on randomly labeled clean data, to induce a CF on the model, leading to a sudden forget on both primary and backdoor tasks; then we recover the primary task by retraining the randomized model on correctly labeled clean data. We analyzed SEAM by modeling the unlearning process as continual learning and further approximating a DNN using Neural Tangent Kernel for measuring CF. Our analysis shows that our random-labeling approach actually maximizes the CF on an unknown backdoor in the absence of triggered inputs, and also preserves some feature extraction in the network to enable a fast revival of the primary task. We further evaluated SEAM on both image processing and Natural Language Processing tasks, under both data contamination and training manipulation attacks, over thousands of models either trained on popular image datasets or provided by the TrojAI competition. Our experiments show that SEAM vastly outperforms the state-of-the-art unlearning techniques, achieving a high Fidelity (measuring the gap between the accuracy of the primary task and that of the backdoor) within a few minutes (about 30 times faster than training a model from scratch using the MNIST dataset), with only a small amount of clean data (0.1% of training data for TrojAI models).
Understanding Impacts of Task Similarity on Backdoor Attack and Detection
Oct 12, 2022
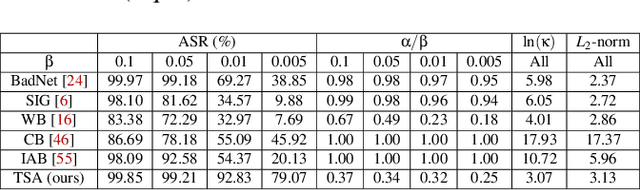
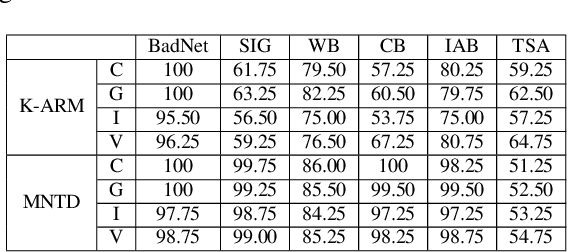
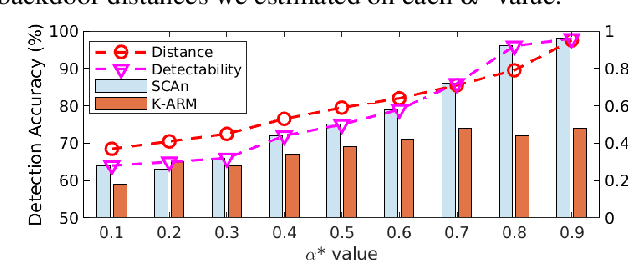
With extensive studies on backdoor attack and detection, still fundamental questions are left unanswered regarding the limits in the adversary's capability to attack and the defender's capability to detect. We believe that answers to these questions can be found through an in-depth understanding of the relations between the primary task that a benign model is supposed to accomplish and the backdoor task that a backdoored model actually performs. For this purpose, we leverage similarity metrics in multi-task learning to formally define the backdoor distance (similarity) between the primary task and the backdoor task, and analyze existing stealthy backdoor attacks, revealing that most of them fail to effectively reduce the backdoor distance and even for those that do, still much room is left to further improve their stealthiness. So we further design a new method, called TSA attack, to automatically generate a backdoor model under a given distance constraint, and demonstrate that our new attack indeed outperforms existing attacks, making a step closer to understanding the attacker's limits. Most importantly, we provide both theoretic results and experimental evidence on various datasets for the positive correlation between the backdoor distance and backdoor detectability, demonstrating that indeed our task similarity analysis help us better understand backdoor risks and has the potential to identify more effective mitigations.