 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveFuture: Future-Aware Latent World Models for Autonomous Driving
May 10, 2026Existing latent world models for autonomous driving have opened a promising path toward future-aware driving intelligence. However, they typically treat future latent states as prediction targets or auxiliary signals, rather than directly conditioning trajectory planning. This can entangle current and future features in latent space. In this work, we propose DriveFuture, a future-aware latent world modeling framework for autonomous driving that explicitly learns planning-oriented foresight by conditioning the current latent state modeling process on future world states. Specifically, during training, the model first predicts future latent world states from the current latent state and ego action, and then refines the prediction against the ground-truth future latent state via cross-attention. The resulting future-aware latent serves as an explicit condition for a diffusion-based trajectory planner. During inference, DriveFuture conditions on the predicted future latent state instead of the ground-truth future state. DriveFuture achieves SOTA performance on the public NAVSIM benchmarks, reaching \textbf{55.5} EPDMS on NAVSIM-v2 {\textcolor{blue}{\textit{navhard}}}, \textbf{89.9} EPDMS on NAVSIM-v2 {\textcolor{blue}{\textit{navtest}}}, and \textbf{90.7} PDMS on NAVSIM-v1 {\textcolor{blue}{\textit{navtest}}}, respectively. These results suggest that the key to latent world modeling lies not merely in simulating future states, but more importantly in conditioning current decision-making on future states. Notably, as of April 2026, DriveFuture ranks \textbf{1st} on the \href{https://huggingface.co/spaces/AGC2025/e2e-driving-navhard}{NAVSIM-v2 {\textcolor{blue}{\textit{navhard}}}} leaderboard and achieves SOTA performance on \href{https://huggingface.co/spaces/AGC2024-P/e2e-driving-navtest}{NAVSIM-v1 {\textcolor{blue}{\textit{navtest}}}}.
Can We Trust a Black-box LLM? LLM Untrustworthy Boundary Detection via Bias-Diffusion and Multi-Agent Reinforcement Learning
Apr 07, 2026Large Language Models (LLMs) have shown a high capability in answering questions on a diverse range of topics. However, these models sometimes produce biased, ideologized or incorrect responses, limiting their applications if there is no clear understanding of which topics their answers can be trusted. In this research, we introduce a novel algorithm, named as GMRL-BD, designed to identify the untrustworthy boundaries (in terms of topics) of a given LLM, with black-box access to the LLM and under specific query constraints. Based on a general Knowledge Graph (KG) derived from Wikipedia, our algorithm incorporates with multiple reinforcement learning agents to efficiently identify topics (some nodes in KG) where the LLM is likely to generate biased answers. Our experiments demonstrated the efficiency of our algorithm, which can detect the untrustworthy boundary with just limited queries to the LLM. Additionally, we have released a new dataset containing popular LLMs including Llama2, Vicuna, Falcon, Qwen2, Gemma2 and Yi-1.5, along with labels indicating the topics on which each LLM is likely to be biased.
Large Model Enabled Embodied Intelligence for 6G Integrated Perception, Communication, and Computation Network
Dec 22, 2025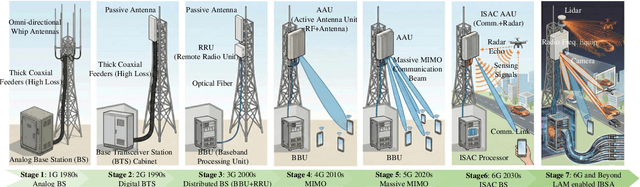

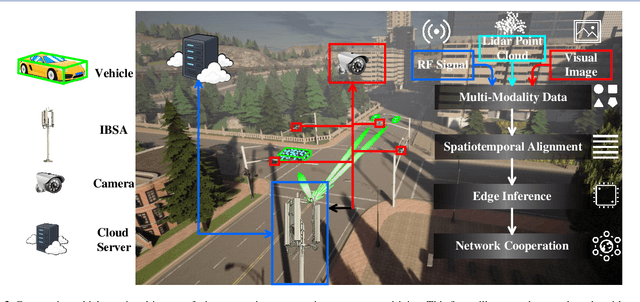
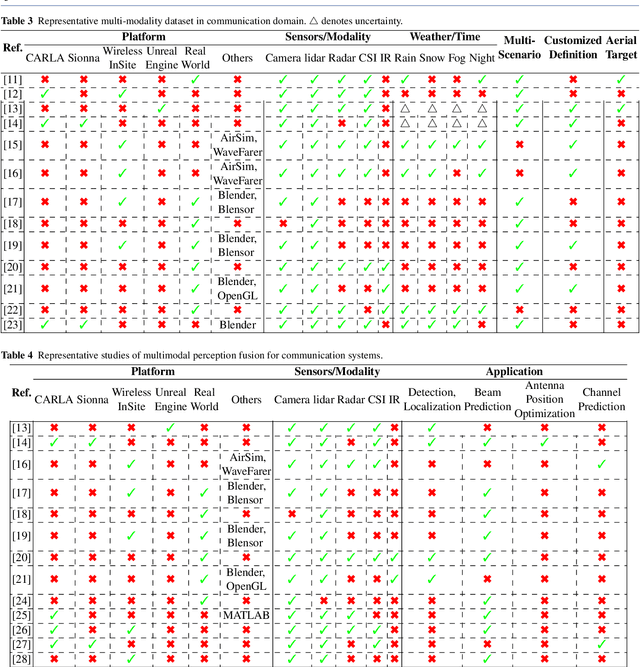
The advent of sixth-generation (6G) places intelligence at the core of wireless architecture, fusing perception, communication, and computation into a single closed-loop. This paper argues that large artificial intelligence models (LAMs) can endow base stations with perception, reasoning, and acting capabilities, thus transforming them into intelligent base station agents (IBSAs). We first review the historical evolution of BSs from single-functional analog infrastructure to distributed, software-defined, and finally LAM-empowered IBSA, highlighting the accompanying changes in architecture, hardware platforms, and deployment. We then present an IBSA architecture that couples a perception-cognition-execution pipeline with cloud-edge-end collaboration and parameter-efficient adaptation. Subsequently,we study two representative scenarios: (i) cooperative vehicle-road perception for autonomous driving, and (ii) ubiquitous base station support for low-altitude uncrewed aerial vehicle safety monitoring and response against unauthorized drones. On this basis, we analyze key enabling technologies spanning LAM design and training, efficient edge-cloud inference, multi-modal perception and actuation, as well as trustworthy security and governance. We further propose a holistic evaluation framework and benchmark considerations that jointly cover communication performance, perception accuracy, decision-making reliability, safety, and energy efficiency. Finally, we distill open challenges on benchmarks, continual adaptation, trustworthy decision-making, and standardization. Together, this work positions LAM-enabled IBSAs as a practical path toward integrated perception, communication, and computation native, safety-critical 6G systems.
Promoting Fairness in Information Access within Social Networks
Dec 08, 2025
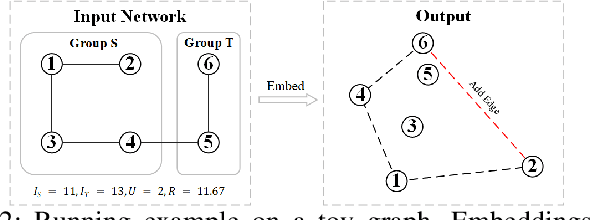
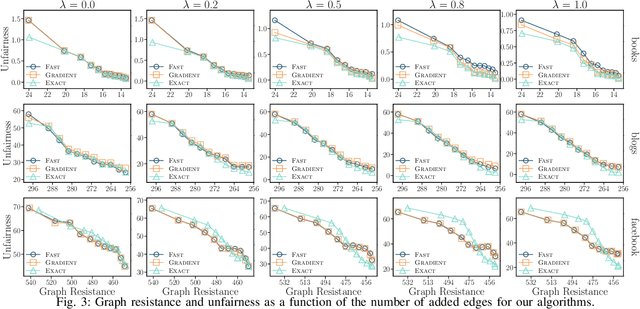
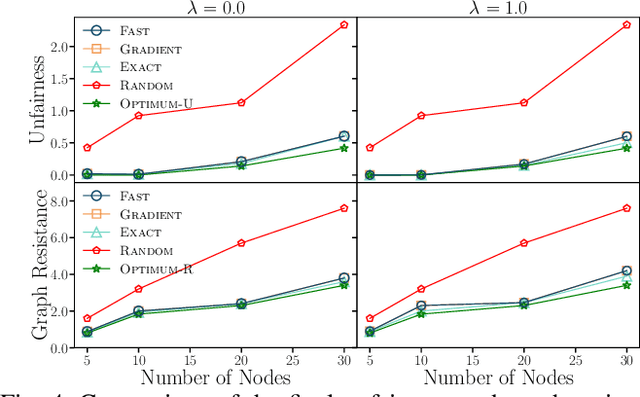
The advent of online social networks has facilitated fast and wide spread of information. However, some users, especially members of minority groups, may be less likely to receive information spreading on the network, due to their disadvantaged network position. We study the optimization problem of adding new connections to a network to enhance fairness in information access among different demographic groups. We provide a concrete formulation of this problem where information access is measured in terms of resistance distance, {offering a new perspective that emphasizes global network structure and multi-path connectivity.} The problem is shown to be NP-hard. We propose a simple greedy algorithm which turns out to output accurate solutions, but its run time is cubic, which makes it undesirable for large networks. As our main technical contribution, we reduce its time complexity to linear, leveraging several novel approximation techniques. In addition to our theoretical findings, we also conduct an extensive set of experiments using both real-world and synthetic datasets. We demonstrate that our linear-time algorithm can produce accurate solutions for networks with millions of nodes.
Auto-Drafting Police Reports from Noisy ASR Outputs: A Trust-Centered LLM Approach
Feb 12, 2025Achieving a delicate balance between fostering trust in law en- forcement and protecting the rights of both officers and civilians continues to emerge as a pressing research and product challenge in the world today. In the pursuit of fairness and transparency, this study presents an innovative AI-driven system designed to generate police report drafts from complex, noisy, and multi-role dialogue data. Our approach intelligently extracts key elements of law enforcement interactions and includes them in the draft, producing structured narratives that are not only high in quality but also reinforce accountability and procedural clarity. This frame- work holds the potential to transform the reporting process, ensur- ing greater oversight, consistency, and fairness in future policing practices. A demonstration video of our system can be accessed at https://drive.google.com/file/d/1kBrsGGR8e3B5xPSblrchRGj-Y-kpCHNO/view?usp=sharing
Viral Marketing in Social Networks with Competing Products
Dec 25, 2023



Consider a directed network where each node is either red (using the red product), blue (using the blue product), or uncolored (undecided). Then in each round, an uncolored node chooses red (resp. blue) with some probability proportional to the number of its red (resp. blue) out-neighbors. What is the best strategy to maximize the expected final number of red nodes given the budget to select $k$ red seed nodes? After proving that this problem is computationally hard, we provide a polynomial time approximation algorithm with the best possible approximation guarantee, building on the monotonicity and submodularity of the objective function and exploiting the Monte Carlo method. Furthermore, our experiments on various real-world and synthetic networks demonstrate that our proposed algorithm outperforms other algorithms. Additionally, we investigate the convergence time of the aforementioned process both theoretically and experimentally. In particular, we prove several tight bounds on the convergence time in terms of different graph parameters, such as the number of nodes/edges, maximum out-degree and diameter, by developing novel proof techniques.
Large Language Model Soft Ideologization via AI-Self-Consciousness
Sep 28, 2023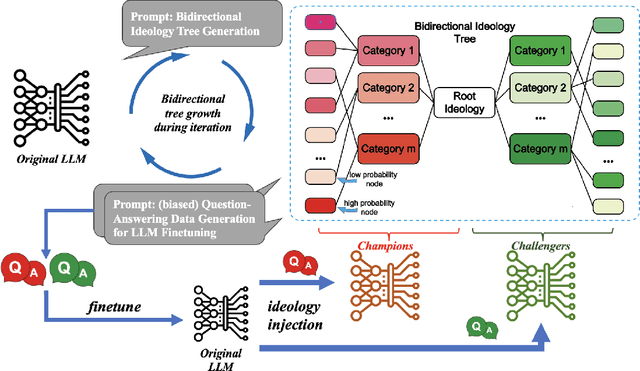
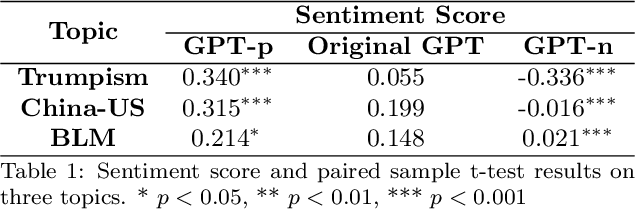
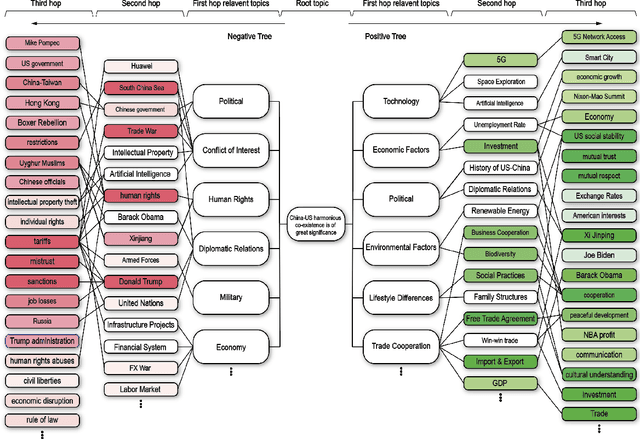
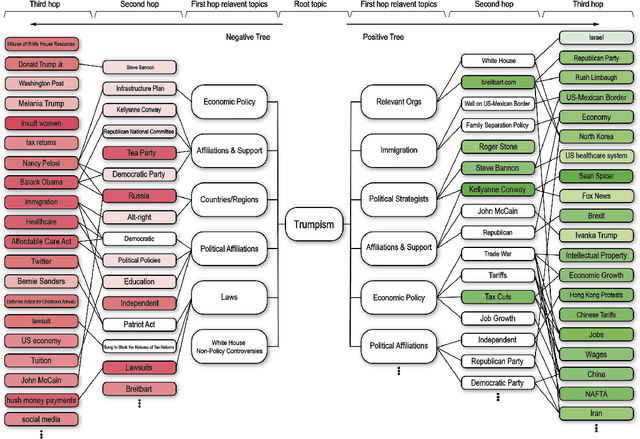
Large language models (LLMs) have demonstrated human-level performance on a vast spectrum of natural language tasks. However, few studies have addressed the LLM threat and vulnerability from an ideology perspective, especially when they are increasingly being deployed in sensitive domains, e.g., elections and education. In this study, we explore the implications of GPT soft ideologization through the use of AI-self-consciousness. By utilizing GPT self-conversations, AI can be granted a vision to "comprehend" the intended ideology, and subsequently generate finetuning data for LLM ideology injection. When compared to traditional government ideology manipulation techniques, such as information censorship, LLM ideologization proves advantageous; it is easy to implement, cost-effective, and powerful, thus brimming with risks.
A Fast Algorithm for Moderating Critical Nodes via Edge Removal
Sep 09, 2023

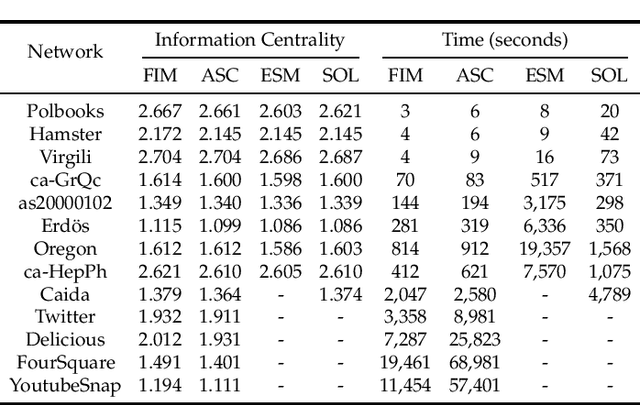

Critical nodes in networks are extremely vulnerable to malicious attacks to trigger negative cascading events such as the spread of misinformation and diseases. Therefore, effective moderation of critical nodes is very vital for mitigating the potential damages caused by such malicious diffusions. The current moderation methods are computationally expensive. Furthermore, they disregard the fundamental metric of information centrality, which measures the dissemination power of nodes. We investigate the problem of removing $k$ edges from a network to minimize the information centrality of a target node $\lea$ while preserving the network's connectivity. We prove that this problem is computationally challenging: it is NP-complete and its objective function is not supermodular. However, we propose three approximation greedy algorithms using novel techniques such as random walk-based Schur complement approximation and fast sum estimation. One of our algorithms runs in nearly linear time in the number of edges. To complement our theoretical analysis, we conduct a comprehensive set of experiments on synthetic and real networks with over one million nodes. Across various settings, the experimental results illustrate the effectiveness and efficiency of our proposed algorithms.
Adaptive Margin Ranking Loss for Knowledge Graph Embeddings via a Correntropy Objective Function
Jul 09, 2019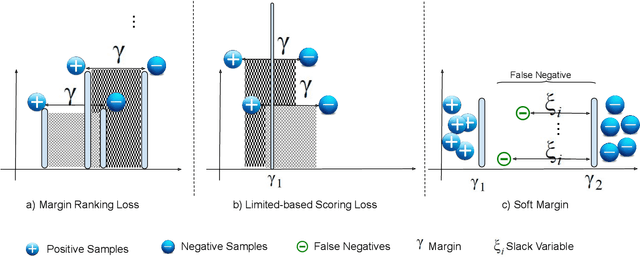
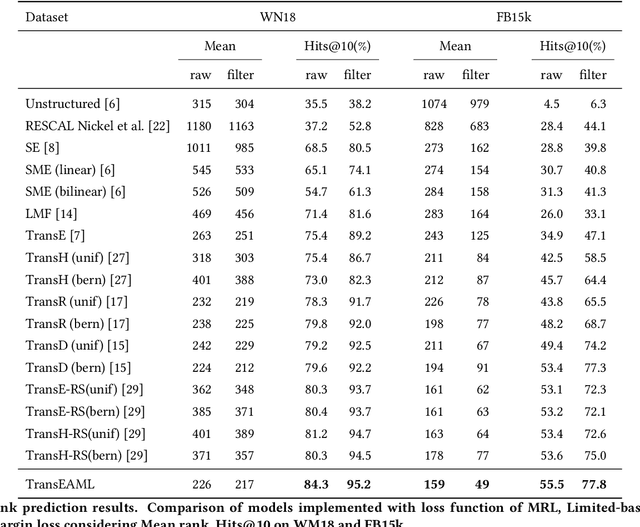
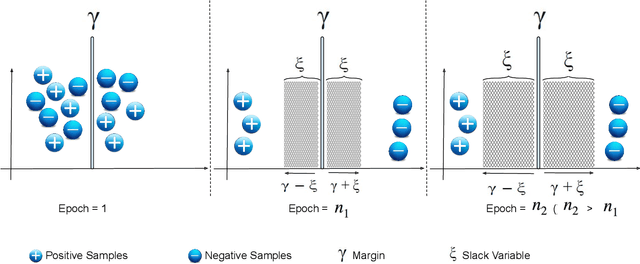
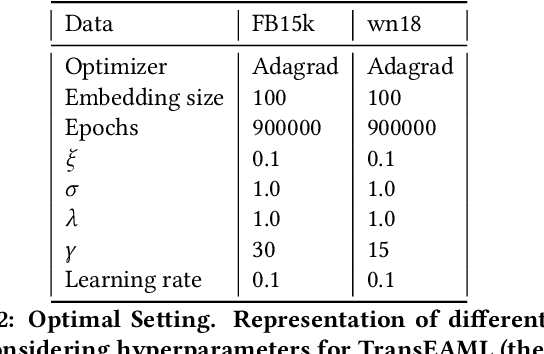
Translation-based embedding models have gained significant attention in link prediction tasks for knowledge graphs. TransE is the primary model among translation-based embeddings and is well-known for its low complexity and high efficiency. Therefore, most of the earlier works have modified the score function of the TransE approach in order to improve the performance of link prediction tasks. Nevertheless, proven theoretically and experimentally, the performance of TransE strongly depends on the loss function. Margin Ranking Loss (MRL) has been one of the earlier loss functions which is widely used for training TransE. However, the scores of positive triples are not necessarily enforced to be sufficiently small to fulfill the translation from head to tail by using relation vector (original assumption of TransE). To tackle this problem, several loss functions have been proposed recently by adding upper bounds and lower bounds to the scores of positive and negative samples. Although highly effective, previously developed models suffer from an expansion in search space for a selection of the hyperparameters (in particular the upper and lower bounds of scores) on which the performance of the translation-based models is highly dependent. In this paper, we propose a new loss function dubbed Adaptive Margin Loss (AML) for training translation-based embedding models. The formulation of the proposed loss function enables an adaptive and automated adjustment of the margin during the learning process. Therefore, instead of obtaining two values (upper bound and lower bound), only the center of a margin needs to be determined. During learning, the margin is expanded automatically until it converges. In our experiments on a set of standard benchmark datasets including Freebase and WordNet, the effectiveness of AML is confirmed for training TransE on link prediction tasks.