 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Edge Rewiring Strategies for Enhancing PageRank Fairness
Jan 23, 2026We study the notion of unfairness in social networks, where a group such as females in a male-dominated industry are disadvantaged in access to important information, e.g. job posts, due to their less favorable positions in the network. We investigate a well-established network-based formulation of fairness called PageRank fairness, which refers to a fair allocation of the PageRank weights among distinct groups. Our goal is to enhance the PageRank fairness by modifying the underlying network structure. More precisely, we study the problem of maximizing PageRank fairness with respect to a disadvantaged group, when we are permitted to rewire a fixed number of edges in the network. Building on a greedy approach, we leverage techniques from fast sampling of rooted spanning forests to devise an effective linear-time algorithm for this problem. To evaluate the accuracy and performance of our proposed algorithm, we conduct a large set of experiments on various real-world network data. Our experiments demonstrate that the proposed algorithm significantly outperforms the existing ones. Our algorithm is capable of generating accurate solutions for networks of million nodes in just a few minutes.
Promoting Fairness in Information Access within Social Networks
Dec 08, 2025
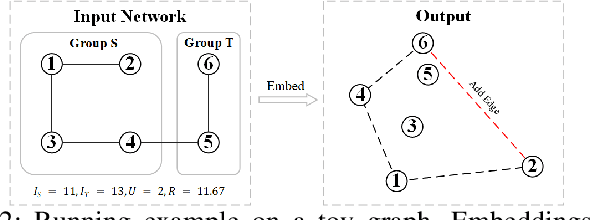
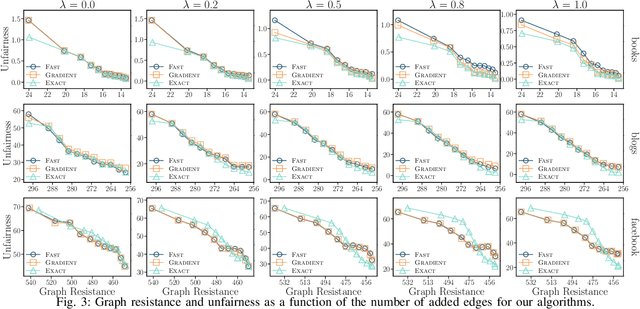
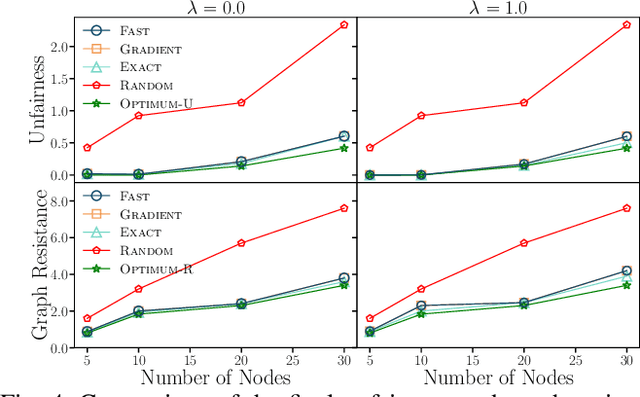
The advent of online social networks has facilitated fast and wide spread of information. However, some users, especially members of minority groups, may be less likely to receive information spreading on the network, due to their disadvantaged network position. We study the optimization problem of adding new connections to a network to enhance fairness in information access among different demographic groups. We provide a concrete formulation of this problem where information access is measured in terms of resistance distance, {offering a new perspective that emphasizes global network structure and multi-path connectivity.} The problem is shown to be NP-hard. We propose a simple greedy algorithm which turns out to output accurate solutions, but its run time is cubic, which makes it undesirable for large networks. As our main technical contribution, we reduce its time complexity to linear, leveraging several novel approximation techniques. In addition to our theoretical findings, we also conduct an extensive set of experiments using both real-world and synthetic datasets. We demonstrate that our linear-time algorithm can produce accurate solutions for networks with millions of nodes.
Efficient Algorithms for Computing Random Walk Centrality
Oct 23, 2025Random walk centrality is a fundamental metric in graph mining for quantifying node importance and influence, defined as the weighted average of hitting times to a node from all other nodes. Despite its ability to capture rich graph structural information and its wide range of applications, computing this measure for large networks remains impractical due to the computational demands of existing methods. In this paper, we present a novel formulation of random walk centrality, underpinning two scalable algorithms: one leveraging approximate Cholesky factorization and sparse inverse estimation, while the other sampling rooted spanning trees. Both algorithms operate in near-linear time and provide strong approximation guarantees. Extensive experiments on large real-world networks, including one with over 10 million nodes, demonstrate the efficiency and approximation quality of the proposed algorithms.
Viral Marketing in Social Networks with Competing Products
Dec 25, 2023



Consider a directed network where each node is either red (using the red product), blue (using the blue product), or uncolored (undecided). Then in each round, an uncolored node chooses red (resp. blue) with some probability proportional to the number of its red (resp. blue) out-neighbors. What is the best strategy to maximize the expected final number of red nodes given the budget to select $k$ red seed nodes? After proving that this problem is computationally hard, we provide a polynomial time approximation algorithm with the best possible approximation guarantee, building on the monotonicity and submodularity of the objective function and exploiting the Monte Carlo method. Furthermore, our experiments on various real-world and synthetic networks demonstrate that our proposed algorithm outperforms other algorithms. Additionally, we investigate the convergence time of the aforementioned process both theoretically and experimentally. In particular, we prove several tight bounds on the convergence time in terms of different graph parameters, such as the number of nodes/edges, maximum out-degree and diameter, by developing novel proof techniques.
Finding Influencers in Complex Networks: An Effective Deep Reinforcement Learning Approach
Sep 09, 2023



Maximizing influences in complex networks is a practically important but computationally challenging task for social network analysis, due to its NP- hard nature. Most current approximation or heuristic methods either require tremendous human design efforts or achieve unsatisfying balances between effectiveness and efficiency. Recent machine learning attempts only focus on speed but lack performance enhancement. In this paper, different from previous attempts, we propose an effective deep reinforcement learning model that achieves superior performances over traditional best influence maximization algorithms. Specifically, we design an end-to-end learning framework that combines graph neural network as the encoder and reinforcement learning as the decoder, named DREIM. Trough extensive training on small synthetic graphs, DREIM outperforms the state-of-the-art baseline methods on very large synthetic and real-world networks on solution quality, and we also empirically show its linear scalability with regard to the network size, which demonstrates its superiority in solving this problem.
A Fast Algorithm for Moderating Critical Nodes via Edge Removal
Sep 09, 2023

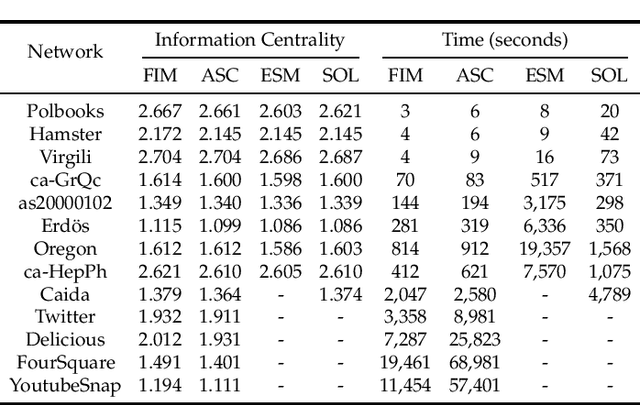

Critical nodes in networks are extremely vulnerable to malicious attacks to trigger negative cascading events such as the spread of misinformation and diseases. Therefore, effective moderation of critical nodes is very vital for mitigating the potential damages caused by such malicious diffusions. The current moderation methods are computationally expensive. Furthermore, they disregard the fundamental metric of information centrality, which measures the dissemination power of nodes. We investigate the problem of removing $k$ edges from a network to minimize the information centrality of a target node $\lea$ while preserving the network's connectivity. We prove that this problem is computationally challenging: it is NP-complete and its objective function is not supermodular. However, we propose three approximation greedy algorithms using novel techniques such as random walk-based Schur complement approximation and fast sum estimation. One of our algorithms runs in nearly linear time in the number of edges. To complement our theoretical analysis, we conduct a comprehensive set of experiments on synthetic and real networks with over one million nodes. Across various settings, the experimental results illustrate the effectiveness and efficiency of our proposed algorithms.
Role Similarity Metric Based on Spanning Rooted Forest
Oct 15, 2021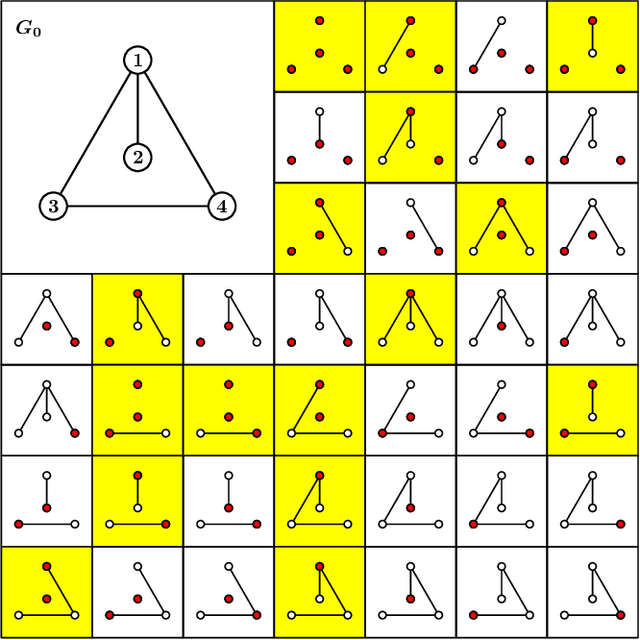

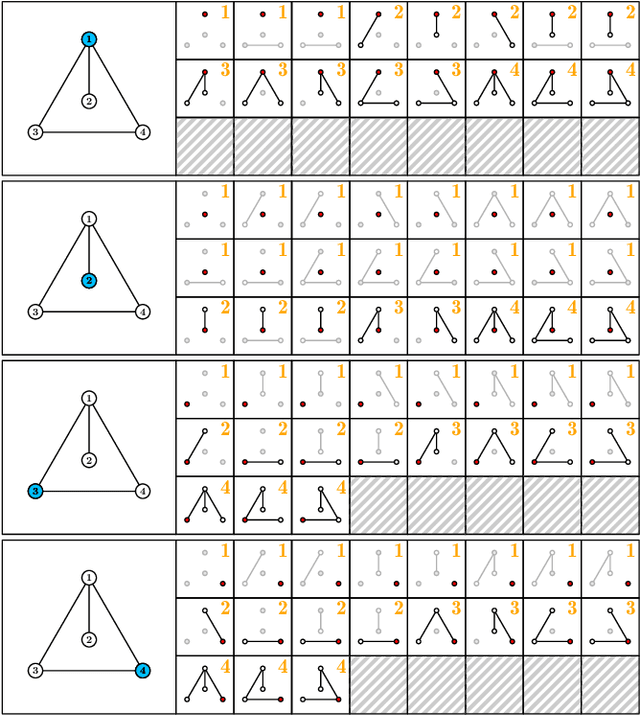
As a fundamental issue in network analysis, structural node similarity has received much attention in academia and is adopted in a wide range of applications. Among these proposed structural node similarity measures, role similarity stands out because of satisfying several axiomatic properties including automorphism conformation. Existing role similarity metrics cannot handle top-k queries on large real-world networks due to the high time and space cost. In this paper, we propose a new role similarity metric, namely \textsf{ForestSim}. We prove that \textsf{ForestSim} is an admissible role similarity metric and devise the corresponding top-k similarity search algorithm, namely \textsf{ForestSimSearch}, which is able to process a top-k query in $O(k)$ time once the precomputation is finished. Moreover, we speed up the precomputation by using a fast approximate algorithm to compute the diagonal entries of the forest matrix, which reduces the time and space complexity of the precomputation to $O(\epsilon^{-2}m\log^5{n}\log{\frac{1}{\epsilon}})$ and $O(m\log^3{n})$, respectively. Finally, we conduct extensive experiments on 26 real-world networks. The results show that \textsf{ForestSim} works efficiently on million-scale networks and achieves comparable performance to the state-of-art methods.