 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCo-MILP: Inter-Variable Contrastive and Intra-Constraint Competitive MILP Solution Prediction
Nov 12, 2025Mixed-Integer Linear Programming (MILP) is a cornerstone of combinatorial optimization, yet solving large-scale instances remains a significant computational challenge. Recently, Graph Neural Networks (GNNs) have shown promise in accelerating MILP solvers by predicting high-quality solutions. However, we identify that existing methods misalign with the intrinsic structure of MILP problems at two levels. At the leaning objective level, the Binary Cross-Entropy (BCE) loss treats variables independently, neglecting their relative priority and yielding plausible logits. At the model architecture level, standard GNN message passing inherently smooths the representations across variables, missing the natural competitive relationships within constraints. To address these challenges, we propose CoCo-MILP, which explicitly models inter-variable Contrast and intra-constraint Competition for advanced MILP solution prediction. At the objective level, CoCo-MILP introduces the Inter-Variable Contrastive Loss (VCL), which explicitly maximizes the embedding margin between variables assigned one versus zero. At the architectural level, we design an Intra-Constraint Competitive GNN layer that, instead of homogenizing features, learns to differentiate representations of competing variables within a constraint, capturing their exclusionary nature. Experimental results on standard benchmarks demonstrate that CoCo-MILP significantly outperforms existing learning-based approaches, reducing the solution gap by up to 68.12% compared to traditional solvers. Our code is available at https://github.com/happypu326/CoCo-MILP.
A Comprehensive Survey on Underwater Acoustic Target Positioning and Tracking: Progress, Challenges, and Perspectives
Jun 17, 2025Underwater target tracking technology plays a pivotal role in marine resource exploration, environmental monitoring, and national defense security. Given that acoustic waves represent an effective medium for long-distance transmission in aquatic environments, underwater acoustic target tracking has become a prominent research area of underwater communications and networking. Existing literature reviews often offer a narrow perspective or inadequately address the paradigm shifts driven by emerging technologies like deep learning and reinforcement learning. To address these gaps, this work presents a systematic survey of this field and introduces an innovative multidimensional taxonomy framework based on target scale, sensor perception modes, and sensor collaboration patterns. Within this framework, we comprehensively survey the literature (more than 180 publications) over the period 2016-2025, spanning from the theoretical foundations to diverse algorithmic approaches in underwater acoustic target tracking. Particularly, we emphasize the transformative potential and recent advancements of machine learning techniques, including deep learning and reinforcement learning, in enhancing the performance and adaptability of underwater tracking systems. Finally, this survey concludes by identifying key challenges in the field and proposing future avenues based on emerging technologies such as federated learning, blockchain, embodied intelligence, and large models.
Transform then Explore: a Simple and Effective Technique for Exploratory Combinatorial Optimization with Reinforcement Learning
Apr 06, 2024Many complex problems encountered in both production and daily life can be conceptualized as combinatorial optimization problems (COPs) over graphs. Recent years, reinforcement learning (RL) based models have emerged as a promising direction, which treat the COPs solving as a heuristic learning problem. However, current finite-horizon-MDP based RL models have inherent limitations. They are not allowed to explore adquately for improving solutions at test time, which may be necessary given the complexity of NP-hard optimization tasks. Some recent attempts solve this issue by focusing on reward design and state feature engineering, which are tedious and ad-hoc. In this work, we instead propose a much simpler but more effective technique, named gauge transformation (GT). The technique is originated from physics, but is very effective in enabling RL agents to explore to continuously improve the solutions during test. Morever, GT is very simple, which can be implemented with less than 10 lines of Python codes, and can be applied to a vast majority of RL models. Experimentally, we show that traditional RL models with GT technique produce the state-of-the-art performances on the MaxCut problem. Furthermore, since GT is independent of any RL models, it can be seamlessly integrated into various RL frameworks, paving the way of these models for more effective explorations in the solving of general COPs.
Machine Learning for the Multi-Dimensional Bin Packing Problem: Literature Review and Empirical Evaluation
Dec 13, 2023The Bin Packing Problem (BPP) is a well-established combinatorial optimization (CO) problem. Since it has many applications in our daily life, e.g. logistics and resource allocation, people are seeking efficient bin packing algorithms. On the other hand, researchers have been making constant advances in machine learning (ML), which is famous for its efficiency. In this article, we first formulate BPP, introducing its variants and practical constraints. Then, a comprehensive survey on ML for multi-dimensional BPP is provided. We further collect some public benchmarks of 3D BPP, and evaluate some online methods on the Cutting Stock Dataset. Finally, we share our perspective on challenges and future directions in BPP. To the best of our knowledge, this is the first systematic review of ML-related methods for BPP.
Finding Influencers in Complex Networks: An Effective Deep Reinforcement Learning Approach
Sep 09, 2023



Maximizing influences in complex networks is a practically important but computationally challenging task for social network analysis, due to its NP- hard nature. Most current approximation or heuristic methods either require tremendous human design efforts or achieve unsatisfying balances between effectiveness and efficiency. Recent machine learning attempts only focus on speed but lack performance enhancement. In this paper, different from previous attempts, we propose an effective deep reinforcement learning model that achieves superior performances over traditional best influence maximization algorithms. Specifically, we design an end-to-end learning framework that combines graph neural network as the encoder and reinforcement learning as the decoder, named DREIM. Trough extensive training on small synthetic graphs, DREIM outperforms the state-of-the-art baseline methods on very large synthetic and real-world networks on solution quality, and we also empirically show its linear scalability with regard to the network size, which demonstrates its superiority in solving this problem.
The Expressive Power of Graph Neural Networks: A Survey
Aug 16, 2023
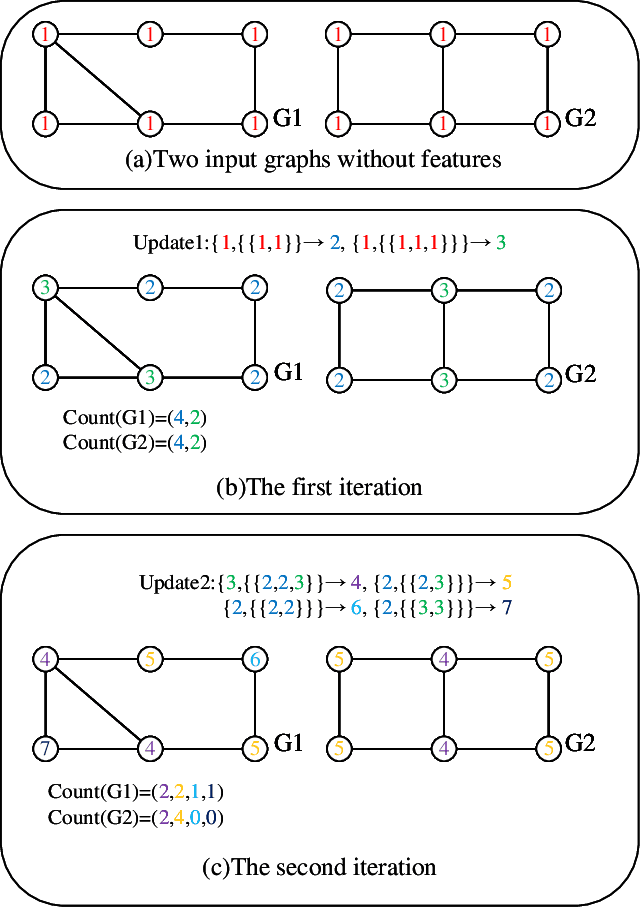
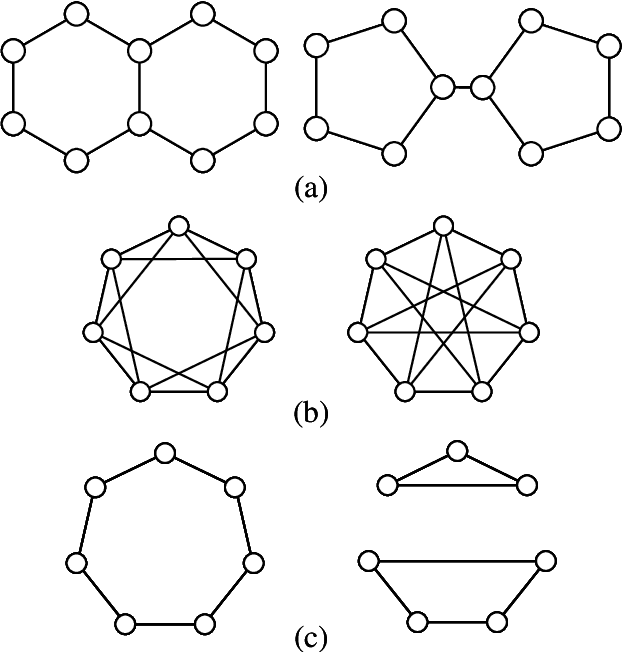
Graph neural networks (GNNs) are effective machine learning models for many graph-related applications. Despite their empirical success, many research efforts focus on the theoretical limitations of GNNs, i.e., the GNNs expressive power. Early works in this domain mainly focus on studying the graph isomorphism recognition ability of GNNs, and recent works try to leverage the properties such as subgraph counting and connectivity learning to characterize the expressive power of GNNs, which are more practical and closer to real-world. However, no survey papers and open-source repositories comprehensively summarize and discuss models in this important direction. To fill the gap, we conduct a first survey for models for enhancing expressive power under different forms of definition. Concretely, the models are reviewed based on three categories, i.e., Graph feature enhancement, Graph topology enhancement, and GNNs architecture enhancement.
Inductive Meta-path Learning for Schema-complex Heterogeneous Information Networks
Jul 08, 2023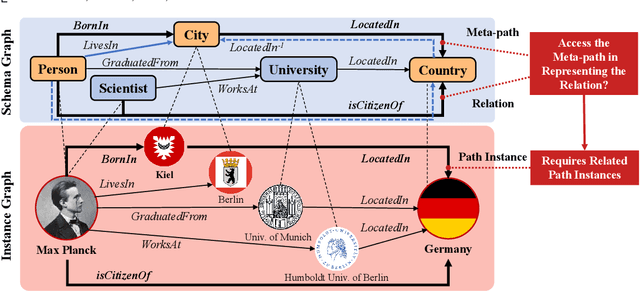
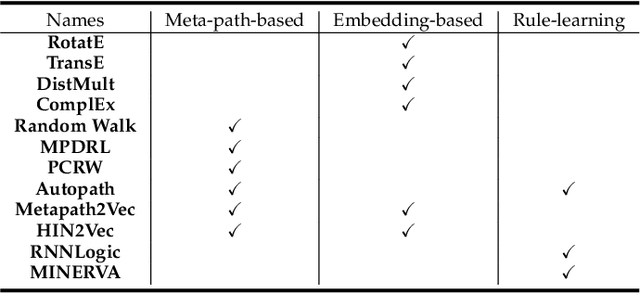
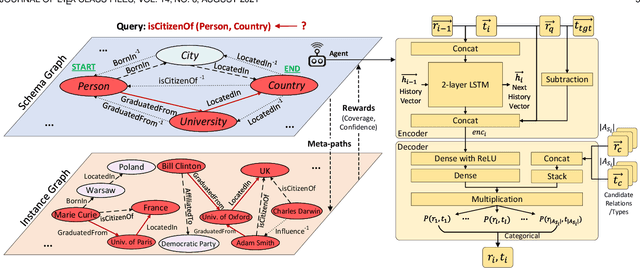
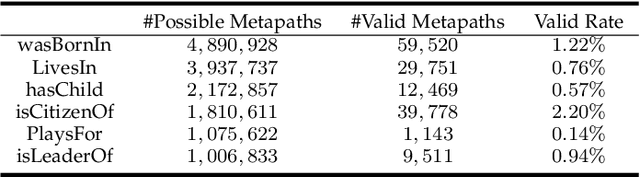
Heterogeneous Information Networks (HINs) are information networks with multiple types of nodes and edges. The concept of meta-path, i.e., a sequence of entity types and relation types connecting two entities, is proposed to provide the meta-level explainable semantics for various HIN tasks. Traditionally, meta-paths are primarily used for schema-simple HINs, e.g., bibliographic networks with only a few entity types, where meta-paths are often enumerated with domain knowledge. However, the adoption of meta-paths for schema-complex HINs, such as knowledge bases (KBs) with hundreds of entity and relation types, has been limited due to the computational complexity associated with meta-path enumeration. Additionally, effectively assessing meta-paths requires enumerating relevant path instances, which adds further complexity to the meta-path learning process. To address these challenges, we propose SchemaWalk, an inductive meta-path learning framework for schema-complex HINs. We represent meta-paths with schema-level representations to support the learning of the scores of meta-paths for varying relations, mitigating the need of exhaustive path instance enumeration for each relation. Further, we design a reinforcement-learning based path-finding agent, which directly navigates the network schema (i.e., schema graph) to learn policies for establishing meta-paths with high coverage and confidence for multiple relations. Extensive experiments on real data sets demonstrate the effectiveness of our proposed paradigm.
Learning from History: Modeling Temporal Knowledge Graphs with Sequential Copy-Generation Networks
Dec 15, 2020



Large knowledge graphs often grow to store temporal facts that model the dynamic relations or interactions of entities along the timeline. Since such temporal knowledge graphs often suffer from incompleteness, it is important to develop time-aware representation learning models that help to infer the missing temporal facts. While the temporal facts are typically evolving, it is observed that many facts often show a repeated pattern along the timeline, such as economic crises and diplomatic activities. This observation indicates that a model could potentially learn much from the known facts appeared in history. To this end, we propose a new representation learning model for temporal knowledge graphs, namely CyGNet, based on a novel timeaware copy-generation mechanism. CyGNet is not only able to predict future facts from the whole entity vocabulary, but also capable of identifying facts with repetition and accordingly predicting such future facts with reference to the known facts in the past. We evaluate the proposed method on the knowledge graph completion task using five benchmark datasets. Extensive experiments demonstrate the effectiveness of CyGNet for predicting future facts with repetition as well as de novo fact prediction.
Multilingual Knowledge Graph Completion via Ensemble Knowledge Transfer
Oct 08, 2020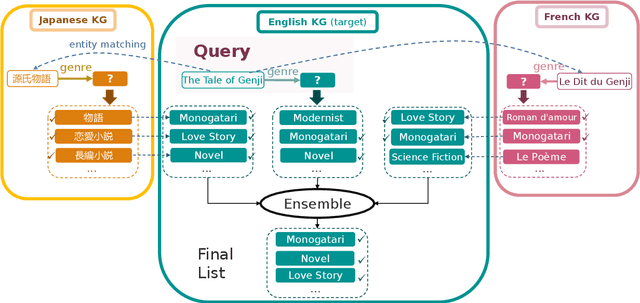
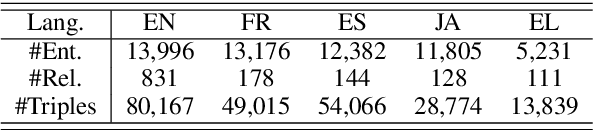
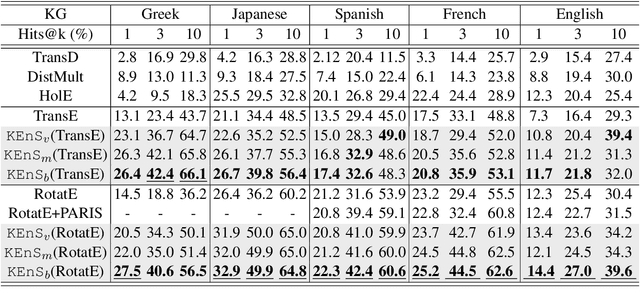
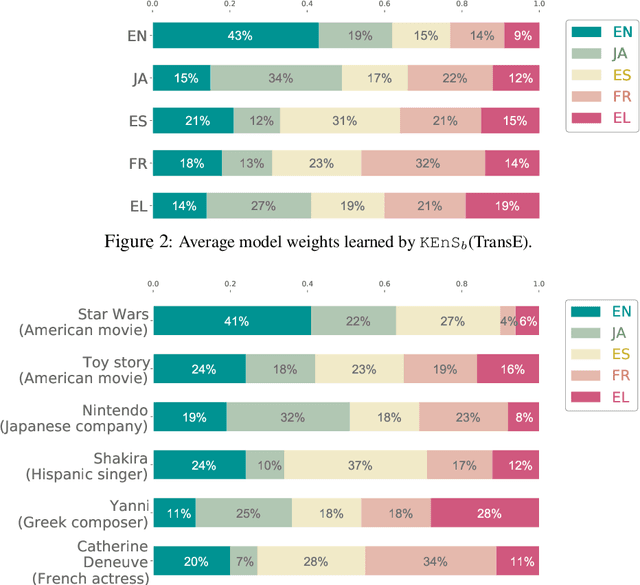
Predicting missing facts in a knowledge graph (KG) is a crucial task in knowledge base construction and reasoning, and it has been the subject of much research in recent works using KG embeddings. While existing KG embedding approaches mainly learn and predict facts within a single KG, a more plausible solution would benefit from the knowledge in multiple language-specific KGs, considering that different KGs have their own strengths and limitations on data quality and coverage. This is quite challenging, since the transfer of knowledge among multiple independently maintained KGs is often hindered by the insufficiency of alignment information and the inconsistency of described facts. In this paper, we propose KEnS, a novel framework for embedding learning and ensemble knowledge transfer across a number of language-specific KGs. KEnS embeds all KGs in a shared embedding space, where the association of entities is captured based on self-learning. Then, KEnS performs ensemble inference to combine prediction results from embeddings of multiple language-specific KGs, for which multiple ensemble techniques are investigated. Experiments on five real-world language-specific KGs show that KEnS consistently improves state-of-the-art methods on KG completion, via effectively identifying and leveraging complementary knowledge.
Pre-Training Graph Neural Networks for Generic Structural Feature Extraction
May 31, 2019



Graph neural networks (GNNs) are shown to be successful in modeling applications with graph structures. However, training an accurate GNN model requires a large collection of labeled data and expressive features, which might be inaccessible for some applications. To tackle this problem, we propose a pre-training framework that captures generic graph structural information that is transferable across tasks. Our framework can leverage the following three tasks: 1) denoising link reconstruction, 2) centrality score ranking, and 3) cluster preserving. The pre-training procedure can be conducted purely on the synthetic graphs, and the pre-trained GNN is then adapted for downstream applications. With the proposed pre-training procedure, the generic structural information is learned and preserved, thus the pre-trained GNN requires less amount of labeled data and fewer domain-specific features to achieve high performance on different downstream tasks. Comprehensive experiments demonstrate that our proposed framework can significantly enhance the performance of various tasks at the level of node, link, and graph.