 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Coreference Resolution for Processing Violent Death Narratives
Apr 30, 2021
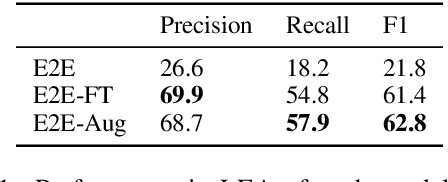
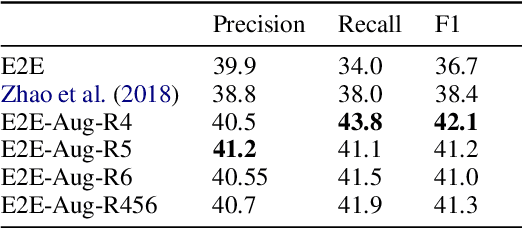
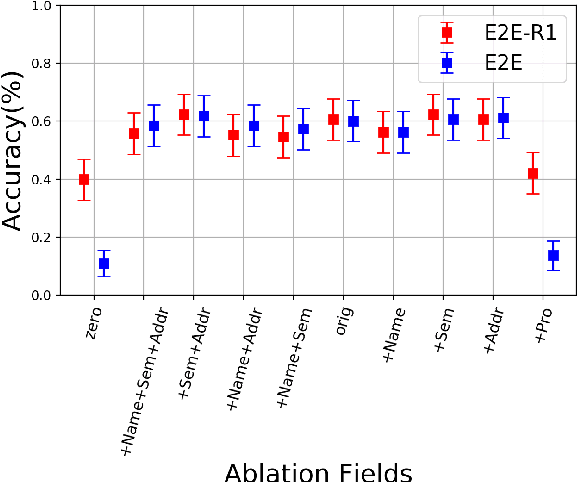
Coreference resolution is an important component in analyzing narrative text from administrative data (e.g., clinical or police sources). However, existing coreference models trained on general language corpora suffer from poor transferability due to domain gaps, especially when they are applied to gender-inclusive data with lesbian, gay, bisexual, and transgender (LGBT) individuals. In this paper, we analyzed the challenges of coreference resolution in an exemplary form of administrative text written in English: violent death narratives from the USA's Centers for Disease Control's (CDC) National Violent Death Reporting System. We developed a set of data augmentation rules to improve model performance using a probabilistic data programming framework. Experiments on narratives from an administrative database, as well as existing gender-inclusive coreference datasets, demonstrate the effectiveness of data augmentation in training coreference models that can better handle text data about LGBT individuals.
Multilingual Knowledge Graph Completion via Ensemble Knowledge Transfer
Oct 08, 2020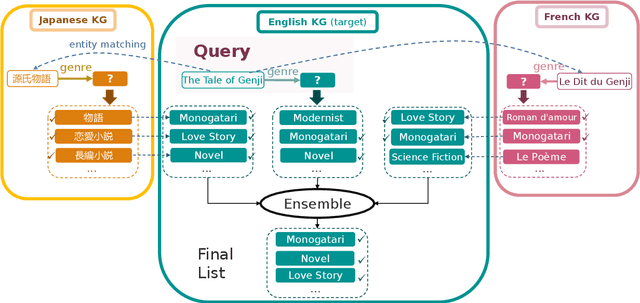
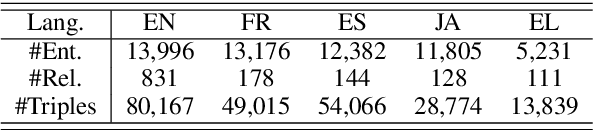
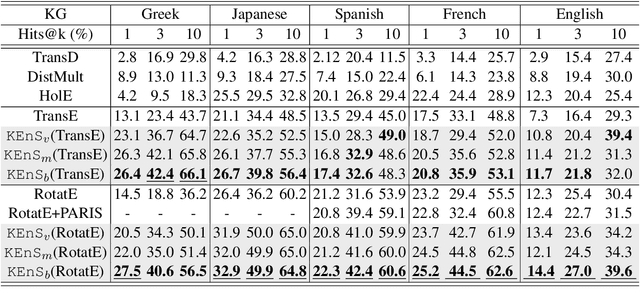
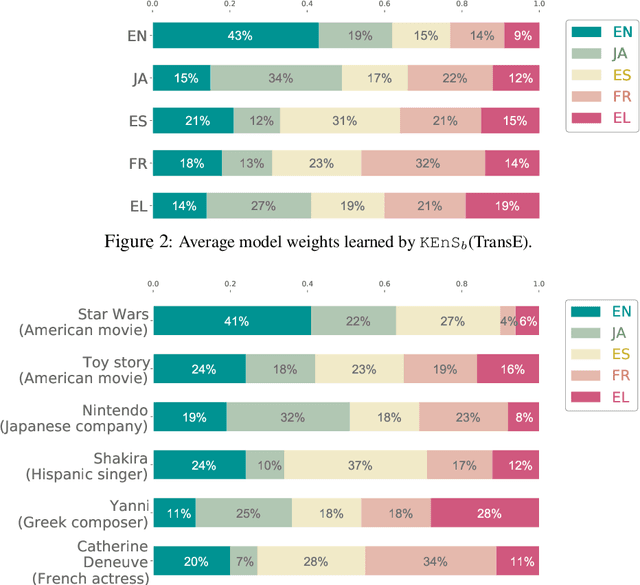
Predicting missing facts in a knowledge graph (KG) is a crucial task in knowledge base construction and reasoning, and it has been the subject of much research in recent works using KG embeddings. While existing KG embedding approaches mainly learn and predict facts within a single KG, a more plausible solution would benefit from the knowledge in multiple language-specific KGs, considering that different KGs have their own strengths and limitations on data quality and coverage. This is quite challenging, since the transfer of knowledge among multiple independently maintained KGs is often hindered by the insufficiency of alignment information and the inconsistency of described facts. In this paper, we propose KEnS, a novel framework for embedding learning and ensemble knowledge transfer across a number of language-specific KGs. KEnS embeds all KGs in a shared embedding space, where the association of entities is captured based on self-learning. Then, KEnS performs ensemble inference to combine prediction results from embeddings of multiple language-specific KGs, for which multiple ensemble techniques are investigated. Experiments on five real-world language-specific KGs show that KEnS consistently improves state-of-the-art methods on KG completion, via effectively identifying and leveraging complementary knowledge.