 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research
Dec 03, 2021
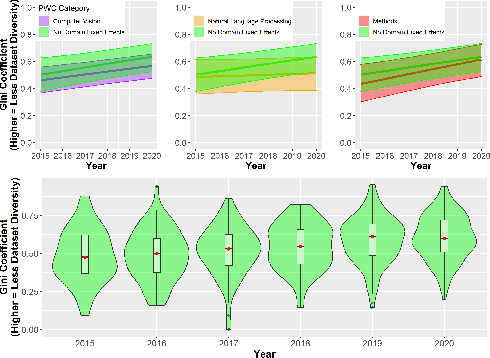
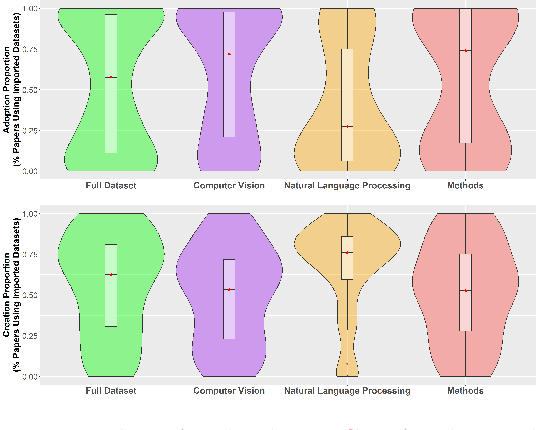
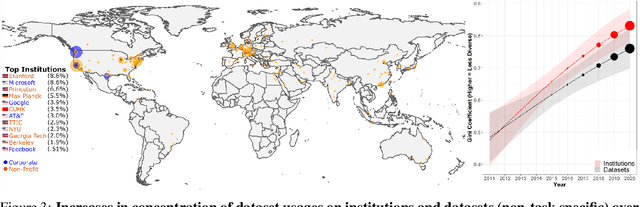
Benchmark datasets play a central role in the organization of machine learning research. They coordinate researchers around shared research problems and serve as a measure of progress towards shared goals. Despite the foundational role of benchmarking practices in this field, relatively little attention has been paid to the dynamics of benchmark dataset use and reuse, within or across machine learning subcommunities. In this paper, we dig into these dynamics. We study how dataset usage patterns differ across machine learning subcommunities and across time from 2015-2020. We find increasing concentration on fewer and fewer datasets within task communities, significant adoption of datasets from other tasks, and concentration across the field on datasets that have been introduced by researchers situated within a small number of elite institutions. Our results have implications for scientific evaluation, AI ethics, and equity/access within the field.
Adapting Coreference Resolution for Processing Violent Death Narratives
Apr 30, 2021
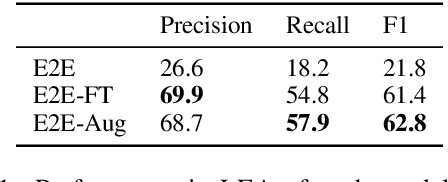
Coreference resolution is an important component in analyzing narrative text from administrative data (e.g., clinical or police sources). However, existing coreference models trained on general language corpora suffer from poor transferability due to domain gaps, especially when they are applied to gender-inclusive data with lesbian, gay, bisexual, and transgender (LGBT) individuals. In this paper, we analyzed the challenges of coreference resolution in an exemplary form of administrative text written in English: violent death narratives from the USA's Centers for Disease Control's (CDC) National Violent Death Reporting System. We developed a set of data augmentation rules to improve model performance using a probabilistic data programming framework. Experiments on narratives from an administrative database, as well as existing gender-inclusive coreference datasets, demonstrate the effectiveness of data augmentation in training coreference models that can better handle text data about LGBT individuals.
Machine learning as a model for cultural learning: Teaching an algorithm what it means to be fat
Mar 24, 2020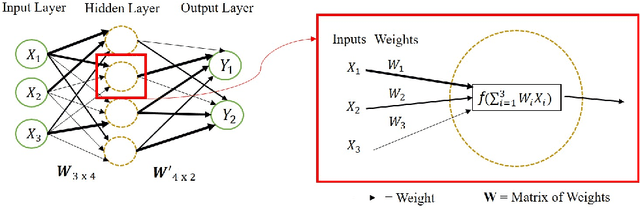
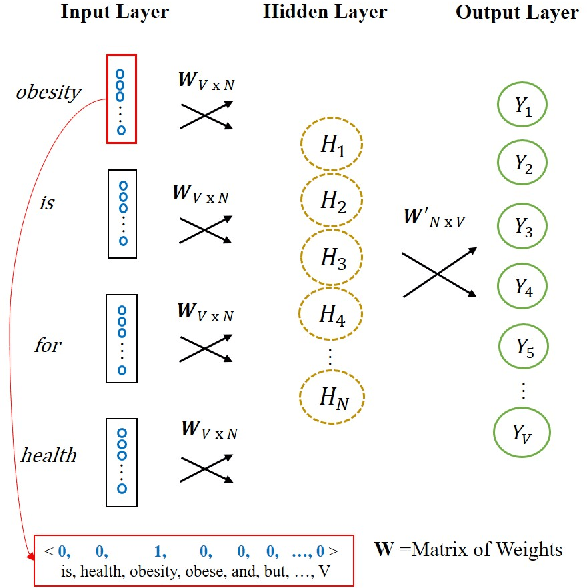

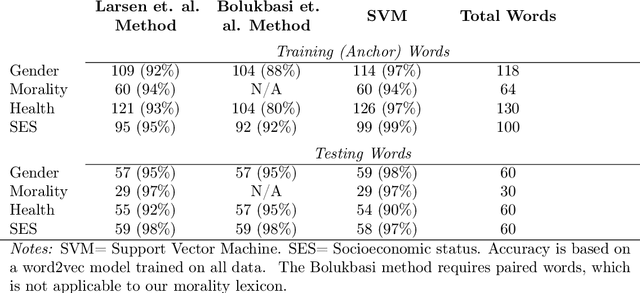
Overweight individuals, and especially women, are disparaged as immoral, unhealthy, and low class. These negative conceptions are not intrinsic to obesity; they are the tainted fruit of cultural learning. Scholars often cite media consumption as a key mechanism for learning cultural biases, but it remains unclear how this public culture becomes private culture. Here we provide a computational account of this learning mechanism, showing that cultural schemata can be learned from news reporting. We extract schemata about obesity from New York Times articles with word2vec, a neural language model inspired by human cognition. We identify several cultural schemata that link obesity to gender, immorality, poor health, and low socioeconomic class. Such schemata may be subtly but pervasively activated by our language; thus, language can chronically reproduce biases (e.g., about weight and health). Our findings also reinforce ongoing concerns that machine learning can encode, and reproduce, harmful human biases.