 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical foundations and limits of word embeddings: what types of meaning can they capture?
Jul 22, 2021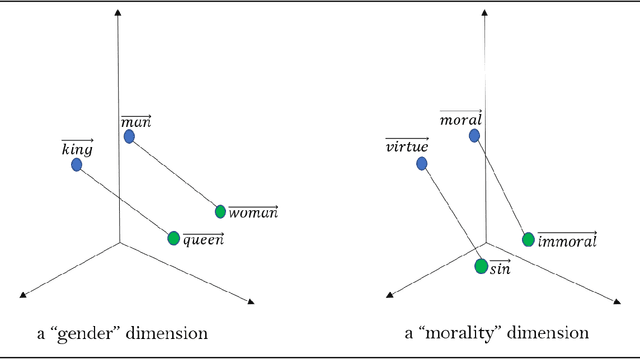
Measuring meaning is a central problem in cultural sociology and word embeddings may offer powerful new tools to do so. But like any tool, they build on and exert theoretical assumptions. In this paper I theorize the ways in which word embeddings model three core premises of a structural linguistic theory of meaning: that meaning is relational, coherent, and may be analyzed as a static system. In certain ways, word embedding methods are vulnerable to the same, enduring critiques of these premises. In other ways, they offer novel solutions to these critiques. More broadly, formalizing the study of meaning with word embeddings offers theoretical opportunities to clarify core concepts and debates in cultural sociology, such as the coherence of meaning. Just as network analysis specified the once vague notion of social relations (Borgatti et al. 2009), formalizing meaning with embedding methods can push us to specify and reimagine meaning itself.
Integrating topic modeling and word embedding to characterize violent deaths
Jun 28, 2021
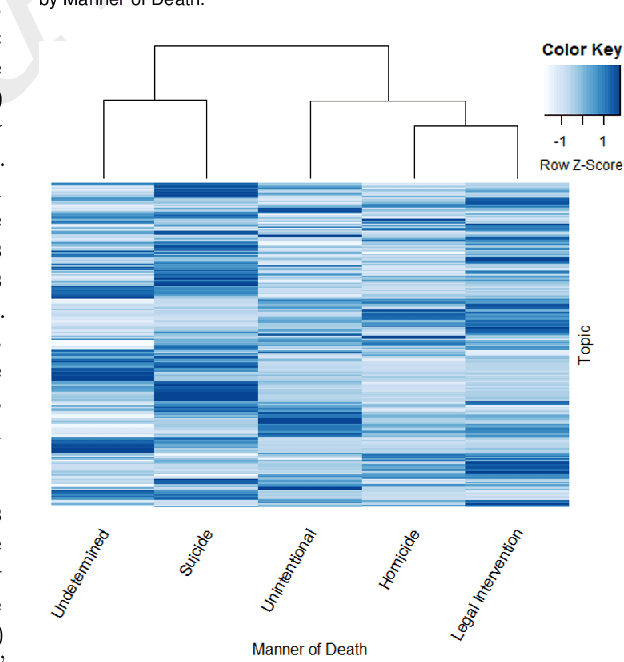
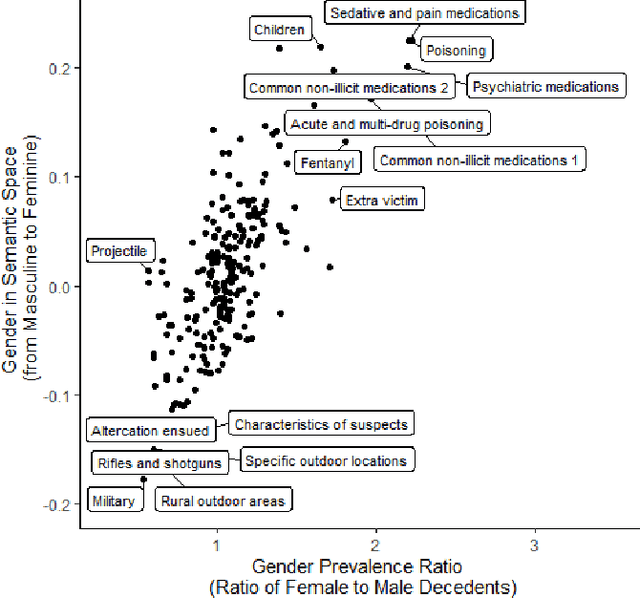
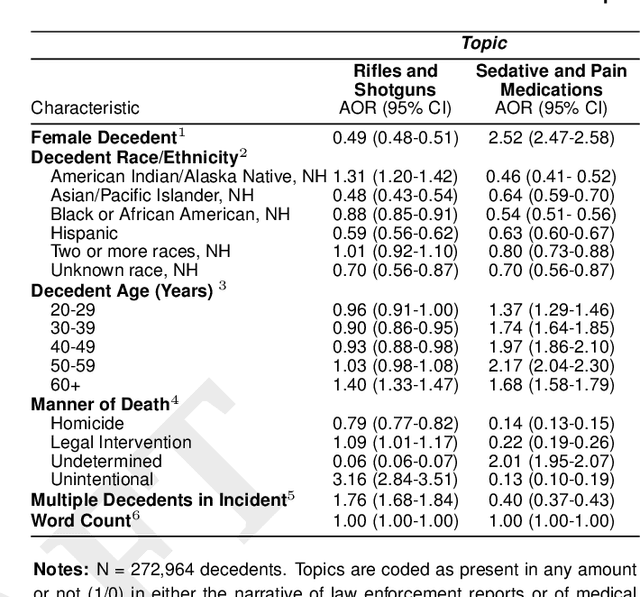
There is an escalating need for methods to identify latent patterns in text data from many domains. We introduce a new method to identify topics in a corpus and represent documents as topic sequences. Discourse Atom Topic Modeling draws on advances in theoretical machine learning to integrate topic modeling and word embedding, capitalizing on the distinct capabilities of each. We first identify a set of vectors ("discourse atoms") that provide a sparse representation of an embedding space. Atom vectors can be interpreted as latent topics: Through a generative model, atoms map onto distributions over words; one can also infer the topic that generated a sequence of words. We illustrate our method with a prominent example of underutilized text: the U.S. National Violent Death Reporting System (NVDRS). The NVDRS summarizes violent death incidents with structured variables and unstructured narratives. We identify 225 latent topics in the narratives (e.g., preparation for death and physical aggression); many of these topics are not captured by existing structured variables. Motivated by known patterns in suicide and homicide by gender, and recent research on gender biases in semantic space, we identify the gender bias of our topics (e.g., a topic about pain medication is feminine). We then compare the gender bias of topics to their prevalence in narratives of female versus male victims. Results provide a detailed quantitative picture of reporting about lethal violence and its gendered nature. Our method offers a flexible and broadly applicable approach to model topics in text data.
Adapting Coreference Resolution for Processing Violent Death Narratives
Apr 30, 2021
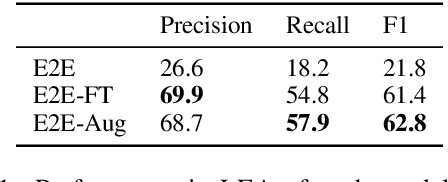
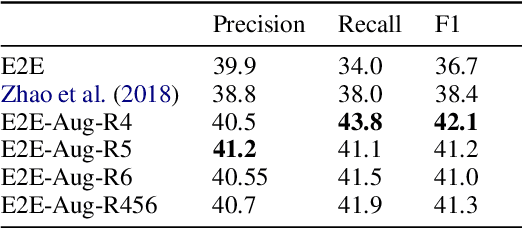
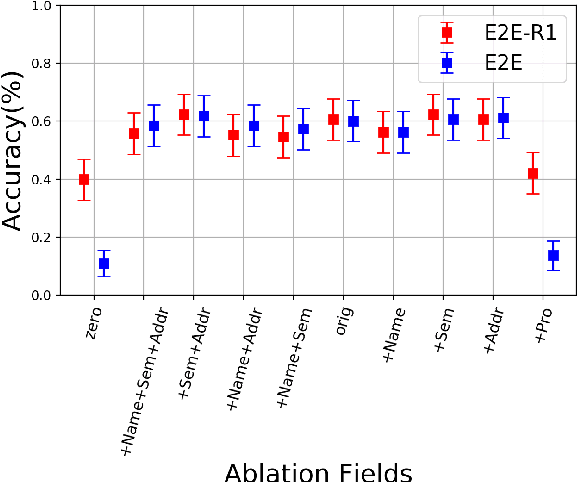
Coreference resolution is an important component in analyzing narrative text from administrative data (e.g., clinical or police sources). However, existing coreference models trained on general language corpora suffer from poor transferability due to domain gaps, especially when they are applied to gender-inclusive data with lesbian, gay, bisexual, and transgender (LGBT) individuals. In this paper, we analyzed the challenges of coreference resolution in an exemplary form of administrative text written in English: violent death narratives from the USA's Centers for Disease Control's (CDC) National Violent Death Reporting System. We developed a set of data augmentation rules to improve model performance using a probabilistic data programming framework. Experiments on narratives from an administrative database, as well as existing gender-inclusive coreference datasets, demonstrate the effectiveness of data augmentation in training coreference models that can better handle text data about LGBT individuals.
Machine learning as a model for cultural learning: Teaching an algorithm what it means to be fat
Mar 24, 2020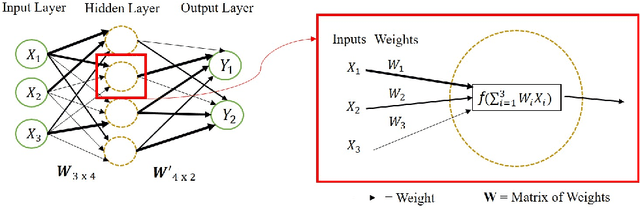
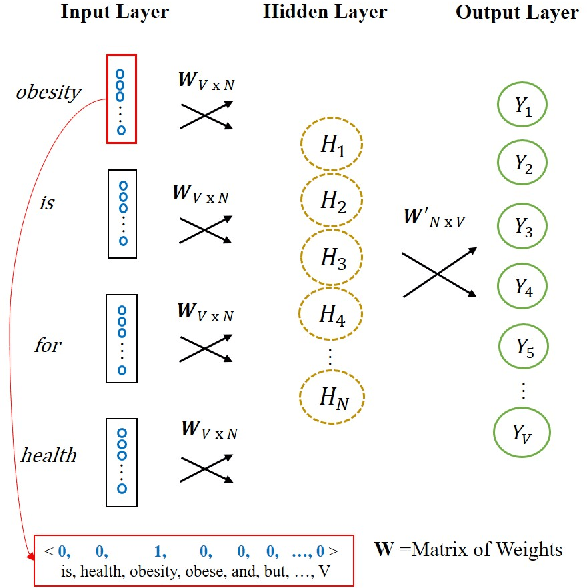

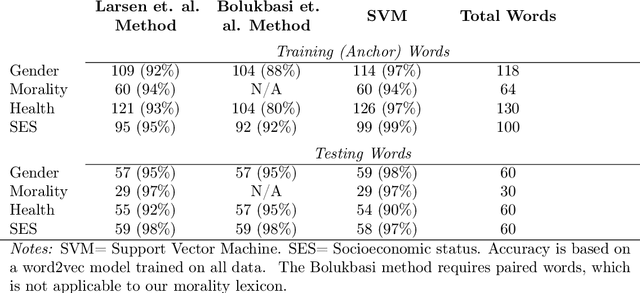
Overweight individuals, and especially women, are disparaged as immoral, unhealthy, and low class. These negative conceptions are not intrinsic to obesity; they are the tainted fruit of cultural learning. Scholars often cite media consumption as a key mechanism for learning cultural biases, but it remains unclear how this public culture becomes private culture. Here we provide a computational account of this learning mechanism, showing that cultural schemata can be learned from news reporting. We extract schemata about obesity from New York Times articles with word2vec, a neural language model inspired by human cognition. We identify several cultural schemata that link obesity to gender, immorality, poor health, and low socioeconomic class. Such schemata may be subtly but pervasively activated by our language; thus, language can chronically reproduce biases (e.g., about weight and health). Our findings also reinforce ongoing concerns that machine learning can encode, and reproduce, harmful human biases.