 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating topic modeling and word embedding to characterize violent deaths
Paper and Code
Jun 28, 2021
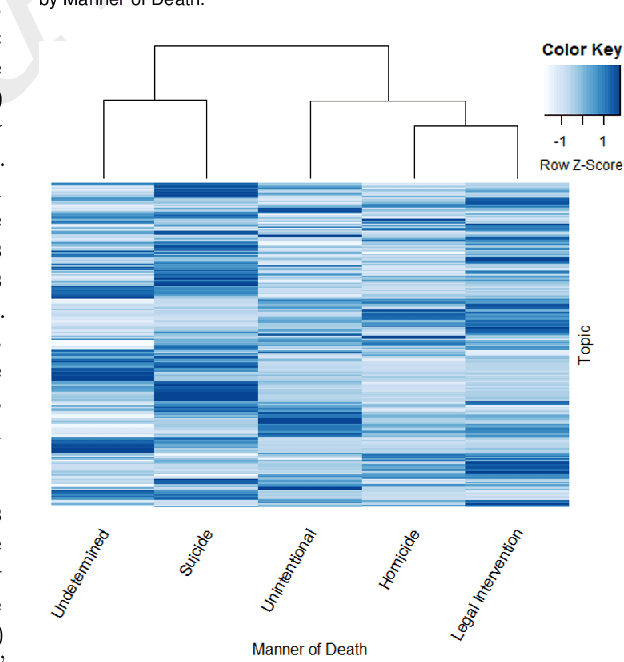
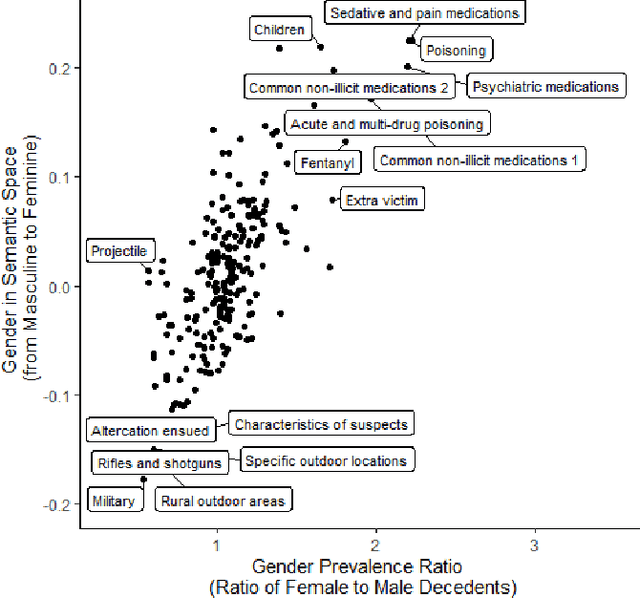
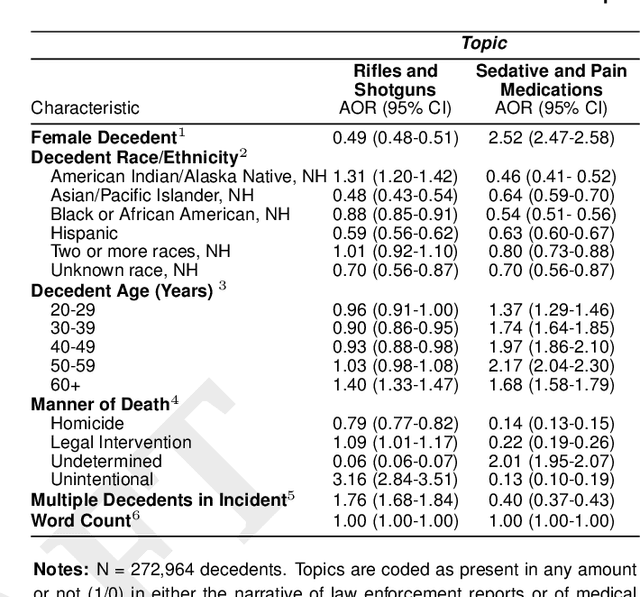
There is an escalating need for methods to identify latent patterns in text data from many domains. We introduce a new method to identify topics in a corpus and represent documents as topic sequences. Discourse Atom Topic Modeling draws on advances in theoretical machine learning to integrate topic modeling and word embedding, capitalizing on the distinct capabilities of each. We first identify a set of vectors ("discourse atoms") that provide a sparse representation of an embedding space. Atom vectors can be interpreted as latent topics: Through a generative model, atoms map onto distributions over words; one can also infer the topic that generated a sequence of words. We illustrate our method with a prominent example of underutilized text: the U.S. National Violent Death Reporting System (NVDRS). The NVDRS summarizes violent death incidents with structured variables and unstructured narratives. We identify 225 latent topics in the narratives (e.g., preparation for death and physical aggression); many of these topics are not captured by existing structured variables. Motivated by known patterns in suicide and homicide by gender, and recent research on gender biases in semantic space, we identify the gender bias of our topics (e.g., a topic about pain medication is feminine). We then compare the gender bias of topics to their prevalence in narratives of female versus male victims. Results provide a detailed quantitative picture of reporting about lethal violence and its gendered nature. Our method offers a flexible and broadly applicable approach to model topics in text data.