 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuch Ado About Gender: Current Practices and Future Recommendations for Appropriate Gender-Aware Information Access
Jan 13, 2023Information access research (and development) sometimes makes use of gender, whether to report on the demographics of participants in a user study, as inputs to personalized results or recommendations, or to make systems gender-fair, amongst other purposes. This work makes a variety of assumptions about gender, however, that are not necessarily aligned with current understandings of what gender is, how it should be encoded, and how a gender variable should be ethically used. In this work, we present a systematic review of papers on information retrieval and recommender systems that mention gender in order to document how gender is currently being used in this field. We find that most papers mentioning gender do not use an explicit gender variable, but most of those that do either focus on contextualizing results of model performance, personalizing a system based on assumptions of user gender, or auditing a model's behavior for fairness or other privacy-related issues. Moreover, most of the papers we review rely on a binary notion of gender, even if they acknowledge that gender cannot be split into two categories. We connect these findings with scholarship on gender theory and recent work on gender in human-computer interaction and natural language processing. We conclude by making recommendations for ethical and well-grounded use of gender in building and researching information access systems.
Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research
Dec 03, 2021
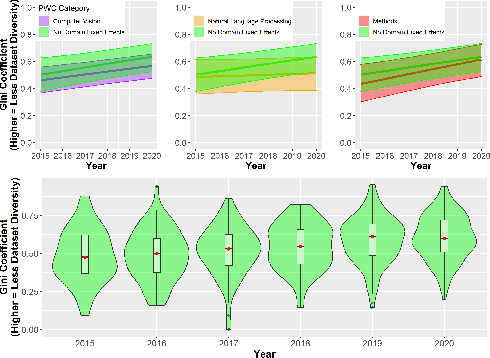
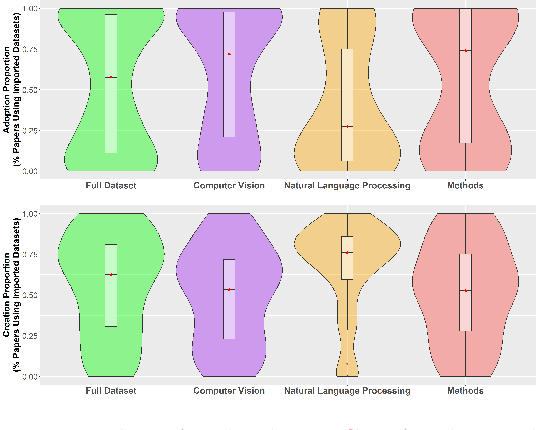
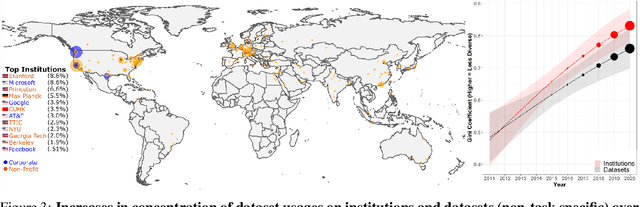
Benchmark datasets play a central role in the organization of machine learning research. They coordinate researchers around shared research problems and serve as a measure of progress towards shared goals. Despite the foundational role of benchmarking practices in this field, relatively little attention has been paid to the dynamics of benchmark dataset use and reuse, within or across machine learning subcommunities. In this paper, we dig into these dynamics. We study how dataset usage patterns differ across machine learning subcommunities and across time from 2015-2020. We find increasing concentration on fewer and fewer datasets within task communities, significant adoption of datasets from other tasks, and concentration across the field on datasets that have been introduced by researchers situated within a small number of elite institutions. Our results have implications for scientific evaluation, AI ethics, and equity/access within the field.
AI and the Everything in the Whole Wide World Benchmark
Nov 26, 2021
There is a tendency across different subfields in AI to valorize a small collection of influential benchmarks. These benchmarks operate as stand-ins for a range of anointed common problems that are frequently framed as foundational milestones on the path towards flexible and generalizable AI systems. State-of-the-art performance on these benchmarks is widely understood as indicative of progress towards these long-term goals. In this position paper, we explore the limits of such benchmarks in order to reveal the construct validity issues in their framing as the functionally "general" broad measures of progress they are set up to be.
Do Datasets Have Politics? Disciplinary Values in Computer Vision Dataset Development
Aug 09, 2021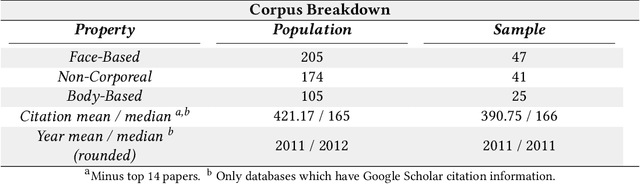
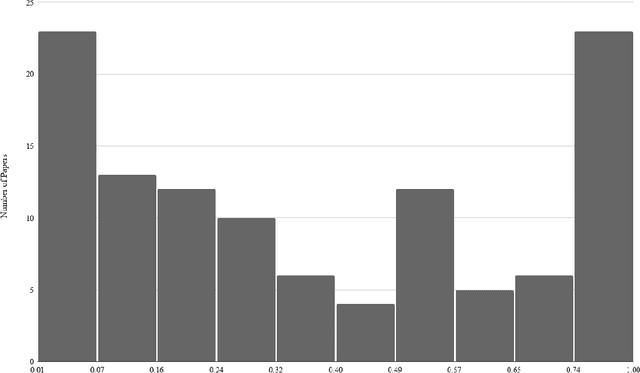
Data is a crucial component of machine learning. The field is reliant on data to train, validate, and test models. With increased technical capabilities, machine learning research has boomed in both academic and industry settings, and one major focus has been on computer vision. Computer vision is a popular domain of machine learning increasingly pertinent to real-world applications, from facial recognition in policing to object detection for autonomous vehicles. Given computer vision's propensity to shape machine learning research and impact human life, we seek to understand disciplinary practices around dataset documentation - how data is collected, curated, annotated, and packaged into datasets for computer vision researchers and practitioners to use for model tuning and development. Specifically, we examine what dataset documentation communicates about the underlying values of vision data and the larger practices and goals of computer vision as a field. To conduct this study, we collected a corpus of about 500 computer vision datasets, from which we sampled 114 dataset publications across different vision tasks. Through both a structured and thematic content analysis, we document a number of values around accepted data practices, what makes desirable data, and the treatment of humans in the dataset construction process. We discuss how computer vision datasets authors value efficiency at the expense of care; universality at the expense of contextuality; impartiality at the expense of positionality; and model work at the expense of data work. Many of the silenced values we identify sit in opposition with social computing practices. We conclude with suggestions on how to better incorporate silenced values into the dataset creation and curation process.
* CSCW 2021; 37 pages
Data and its contents: A survey of dataset development and use in machine learning research
Dec 09, 2020Datasets have played a foundational role in the advancement of machine learning research. They form the basis for the models we design and deploy, as well as our primary medium for benchmarking and evaluation. Furthermore, the ways in which we collect, construct and share these datasets inform the kinds of problems the field pursues and the methods explored in algorithm development. However, recent work from a breadth of perspectives has revealed the limitations of predominant practices in dataset collection and use. In this paper, we survey the many concerns raised about the way we collect and use data in machine learning and advocate that a more cautious and thorough understanding of data is necessary to address several of the practical and ethical issues of the field.
Towards Accountability for Machine Learning Datasets: Practices from Software Engineering and Infrastructure
Oct 23, 2020

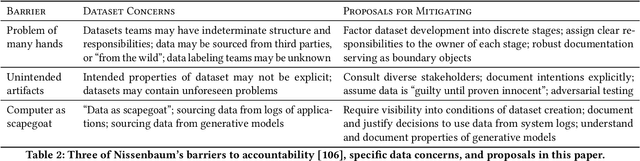
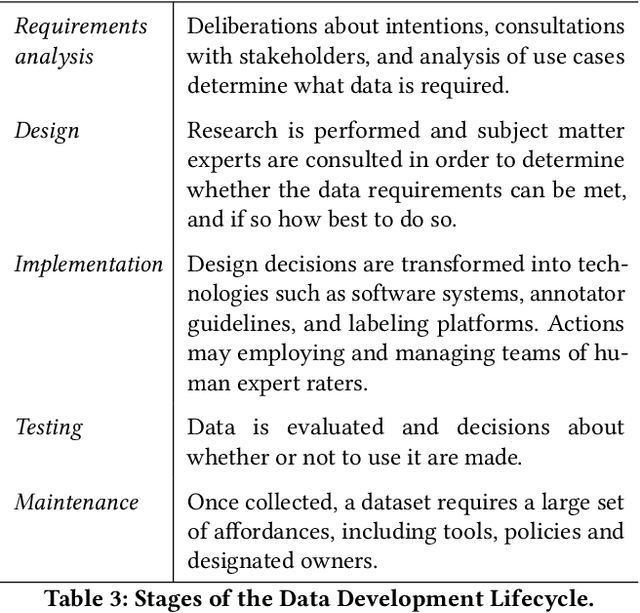
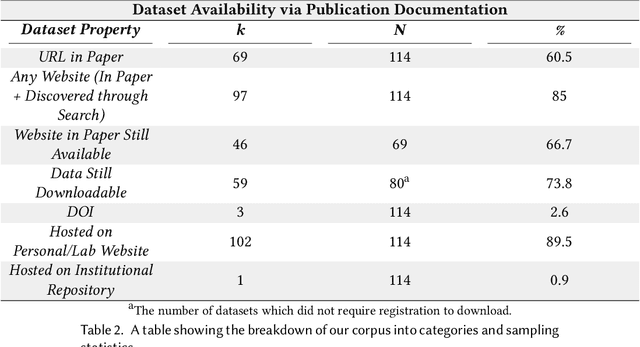
Rising concern for the societal implications of artificial intelligence systems has inspired demands for greater transparency and accountability. However the datasets which empower machine learning are often used, shared and re-used with little visibility into the processes of deliberation which led to their creation. Which stakeholder groups had their perspectives included when the dataset was conceived? Which domain experts were consulted regarding how to model subgroups and other phenomena? How were questions of representational biases measured and addressed? Who labeled the data? In this paper, we introduce a rigorous framework for dataset development transparency which supports decision-making and accountability. The framework uses the cyclical, infrastructural and engineering nature of dataset development to draw on best practices from the software development lifecycle. Each stage of the data development lifecycle yields a set of documents that facilitate improved communication and decision-making, as well as drawing attention the value and necessity of careful data work. The proposed framework is intended to contribute to closing the accountability gap in artificial intelligence systems, by making visible the often overlooked work that goes into dataset creation.
Diversity and Inclusion Metrics in Subset Selection
Feb 09, 2020


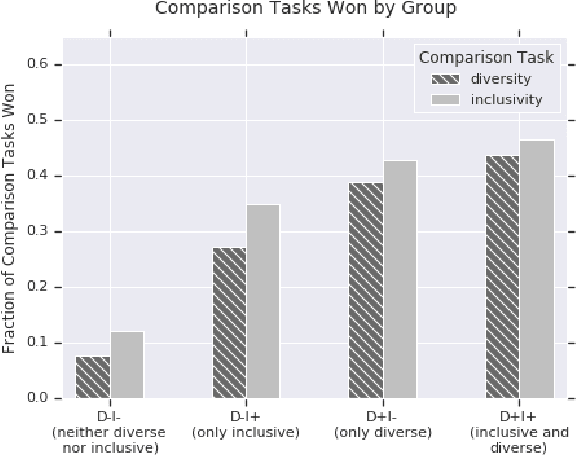
The ethical concept of fairness has recently been applied in machine learning (ML) settings to describe a wide range of constraints and objectives. When considering the relevance of ethical concepts to subset selection problems, the concepts of diversity and inclusion are additionally applicable in order to create outputs that account for social power and access differentials. We introduce metrics based on these concepts, which can be applied together, separately, and in tandem with additional fairness constraints. Results from human subject experiments lend support to the proposed criteria. Social choice methods can additionally be leveraged to aggregate and choose preferable sets, and we detail how these may be applied.